
阿裏雲CPFS在人工智能/深度學習領域的實踐
AI/DL在迅速發展
隨著數據量的爆發式增長和計算能力的不斷提升,以及在算法上的不斷突破,人工智能(AI,Artificial Intelligence )和其支持的深度學習(DL,Deep Learning)計算模型取得了突飛猛進的發展。
去年,中國制定了《新一代人工智能發展規劃》立誌要在AI總體技術和應用2020年與世界前沿同步,2025年AI成為產業升級和經濟轉型的主要動力,2030年,中國要成為世界主要AI創新中心。AI已經上升為國家策略,針對AI的投資也在不斷迅速增長。
AI/DL的數據處理流程
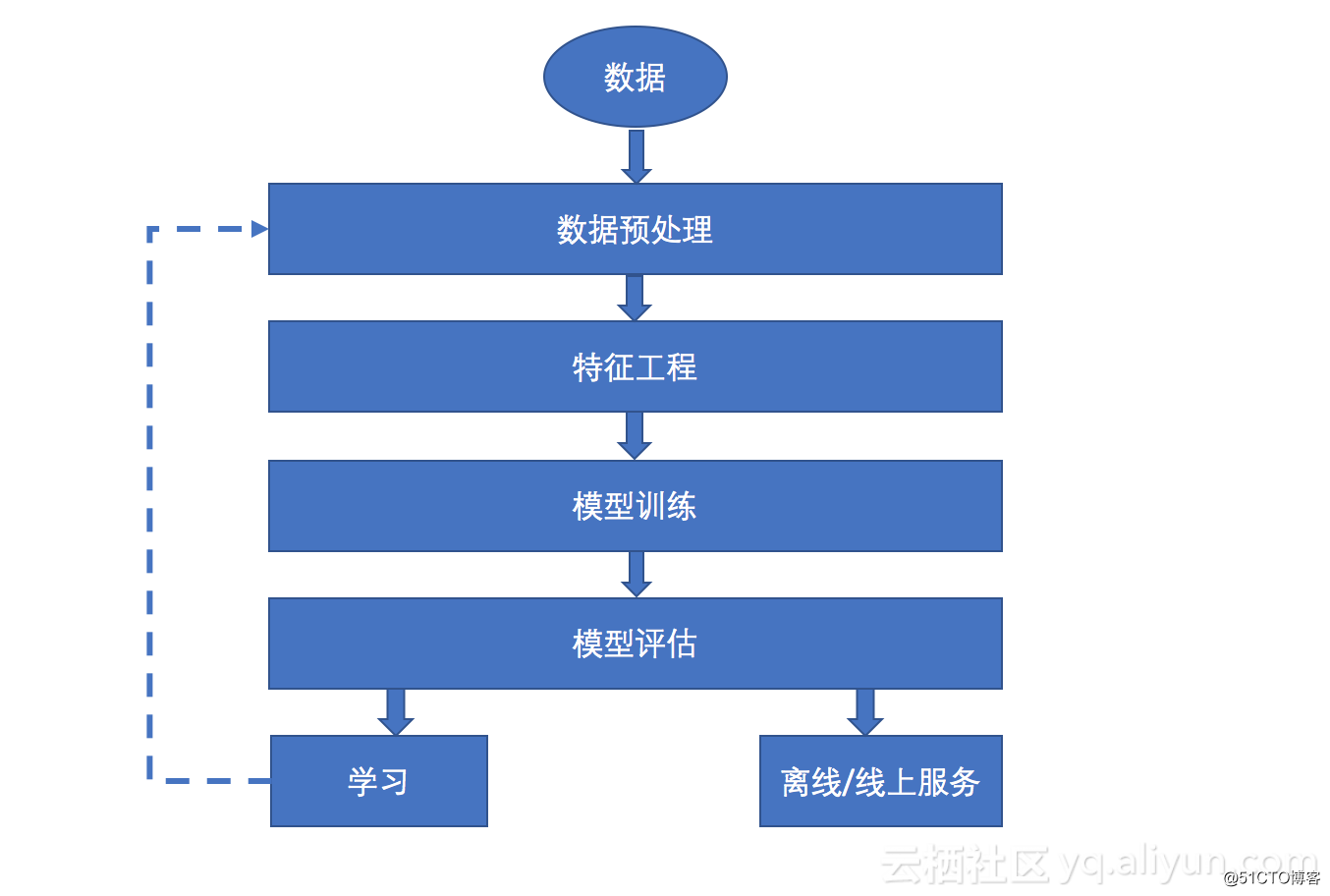
采集數據:
根據業務需要,實際采集相應的數據,或者從專門的數據采集公司購買現成的原始數據。
數據預處理:
這些原始數據可能會存在有缺失值、重復值等,在使用之前需要進行數據預處理。數據預處理沒有標準的流程,通常針對不同的任務和數據集屬性的不同而不同。例如,調整照片的亮度、對比度等等。
特征工程:
將數據中的特征標註出來,比如標記自動駕駛采集的道路信息,道路兩旁的汽車信息等等,再比如人臉識別的場景中,將人臉照片根據不同的特征進行分類等。
模型訓練:
構建適當的算法,從訓練集中計算出準確的預測值。比如,在自動駕駛汽車的場景中,機器學習算法的主要任務之一是持續感應周圍環境,並預測可能出現的變化。
將訓練好的模型放到實際的應用環境中,評估模型的好壞。在這個過程中,可以根據我們設定的評價指標和結果,反過來不斷的修正我們的模型,使得模型的準確度不斷提高。
從整個流程來看,AI需要強大的計算能力和大量的數據為基礎,這也是為什麽很多科技巨頭宣布自己是數據驅動的公司,同時很多行業在不斷推動將業務數據化。數據化之後,借力AI,就能讓數據產生巨大的價值。有了數據之後,還要有高效的算法和匹配的模型,這是AI的核心競爭力。
AI/DL對存儲系統的需求
目前AI/DL最常用的三大編程框架分別是 TensorFlow,Caffe,MXnet,並且GPU(Graphical Processing Units)在這一技術騰飛的過程中發揮了巨大的推動作用,逐漸奠定了GPU在AI/DL解決方案中的主導地位,幾乎所有的AI/DL解決方案都采用了GPU的集群解決方案。
這種變化使得服務器的形態發生了很大的變化,用於AI/DL的服務器通常配置2個CPU+四個GPU,甚至有的廠商推出了一機8卡,一機16卡的服務器。 隨著單機GPU數量的不斷增加,前端計算系統的計算能力和計算密度得到了極大的提升,這也給後端的存儲系統帶來極大的挑戰。
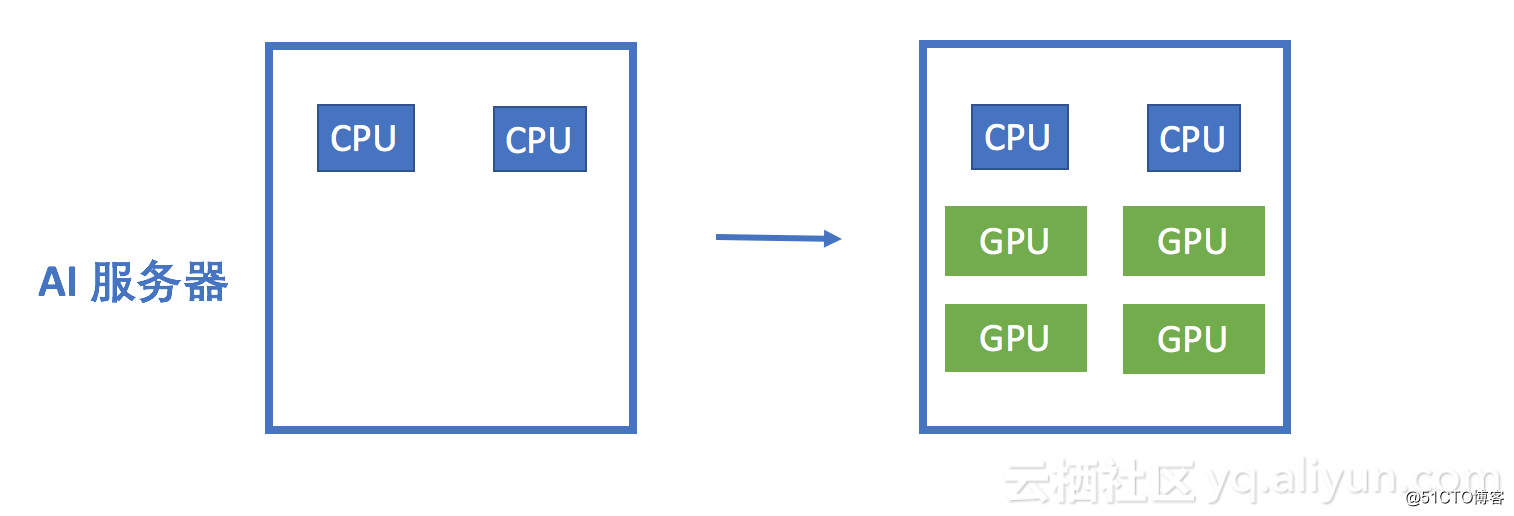
AI/DL對計算能力的不斷苛求,正在創造著當今計算領域最復雜最苛刻的工作負載,這種變化正給數據中心解決方案的計算,存儲,網絡系統帶來了越來越大的挑戰。之前針對傳統工作負載設計的存儲系統,已經不能滿足AI/DL工作負載的需求。
最開始,AI很多訓練任務,都是在單機進行的,使用本地磁盤來創建RAID,然後格式化成本地的文件系統來存儲數據。並且如果使用機械硬盤不能滿足AI對IOPS的需求,很多用戶使用了SATA的SSD硬盤,甚至使用了NVME的SSD硬盤來支持AI的工作負載。雖然這很好的滿足了單機訓練的需求,但是也帶來了一定的問題,例如需要將訓練樣本拷貝到多個服務器進行訓練,這樣同一份數據不僅要拷貝多份占用存儲空間,也給網絡管理和數據管理帶來了復雜性;並且由於數據無法共享,無法支持整個GPU集群同時運行任務,降低了整個IT系統的使用效率。
為了便於數據管理和共享,傳統文件存儲在AI系統中得到一定程度的使用。但是傳統文件存儲無法橫向擴展,並且單個服務器很容易成為性能瓶頸,因此傳統文件存儲能提供的容量,帶寬和IOPS都有限,無法滿足AI對存儲系統的苛刻需求。穩定性方面,隨著磁盤容量的不斷擴大,基於RAID的數據保護機制也越來越遭遇挑戰,例如當RAID中某塊磁盤壞掉,重建的時間越來越長。高可用方面,存儲系統雙節點的高可用配置在某些情況下,已經無法滿足需求。
AI場景需要後端存儲提供高帶寬,高IOPS和高度的並行性,並且能夠方便的擴展和管理。例如,在某些的訓練場景中,訓練集都是幾十KB的小圖片,並且訓練集可以達到上百個TB。在訓練開始的時候,GPU集群從後端存儲系統中,讀取這些小文件的訓練集進行訓練,這要求存儲延遲要低,否則IO會成為整個工作流的瓶頸。
CPFS應用於AI/DL
CPFS(Cloud Parallel File System)並行文件系統是阿裏雲文件存儲團隊推出的並行文件系統。CPFS采用基於對象的設計思路,將數據和元數據分離,將多臺服務器的存儲空間聚合成一個統一的命名空間,原生支持POSIX和MPI接口,上層應用不需要修改可以直接訪問CPFS上的數據。
CPFS的架構先進性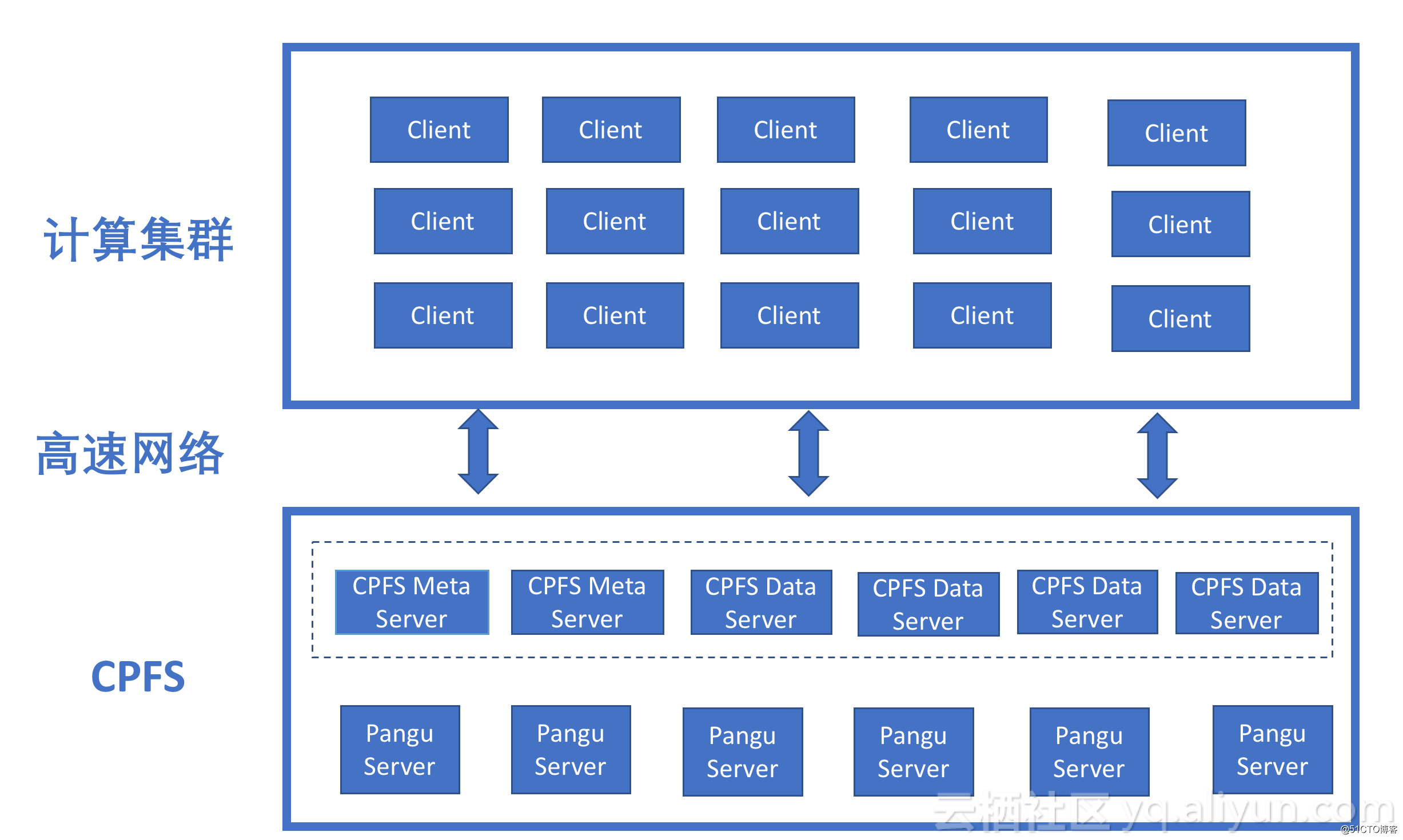
? 超高吞吐和IOPS
CPFS將數據條帶化後均勻分布在存儲集群上,實現計算節點並行訪問,因此吞吐和IOPS可隨存儲節點的數量線性增長。同時,支持高帶寬低延時的Infiniband網絡用於數據交互,整個存儲集群可提供超高的聚合帶寬和IOPS。
? 盤古2.0
CPFS持久化存儲基於飛天盤古2.0分布式存儲系統,通過極致的性能優化,實現磁盤讀寫的超高性能。支持多份數據拷貝,可以提供11個9的數據可靠性,並完美通過了阿裏雙十一超高壓力的考驗。
? 深度優化的高可用性
所有節點均為高可用設計。實現集群內秒級別的故障檢測,並由CPFS集群調度器自動將服務切換到其他節點,同時兼顧負載均衡。整個切換過程用戶不感知,提供遠高於傳統兩節點HA的高可用性。
? 彈性可擴展
支持在線的擴容,由於所有數據均以條帶化的方式存儲並且支持擴容以後的自動負載平衡,可滿足性能的線性增長並且即時利用擴容節點的吞吐和存儲能力,滿足業務增長需要的更多容量與性能的訴求。
? 低成本
數據以EC方式持久化存儲,在保證數據可靠性的同時,最大限度發掘存儲集群的可用空間,提升存儲性價比。
CPFS充分利用Infiniband高速網絡的高帶寬,低延遲的特性,同時支持在線橫向擴展,可以為AI提供超高的聚合帶寬和高IOPS,滿足AI訓練場景的苛刻要求,如圖所示。同時,針對AI中應用容器的場景,CPFS可以支持在容器中直接掛載,容器直接訪問數據,加速IO。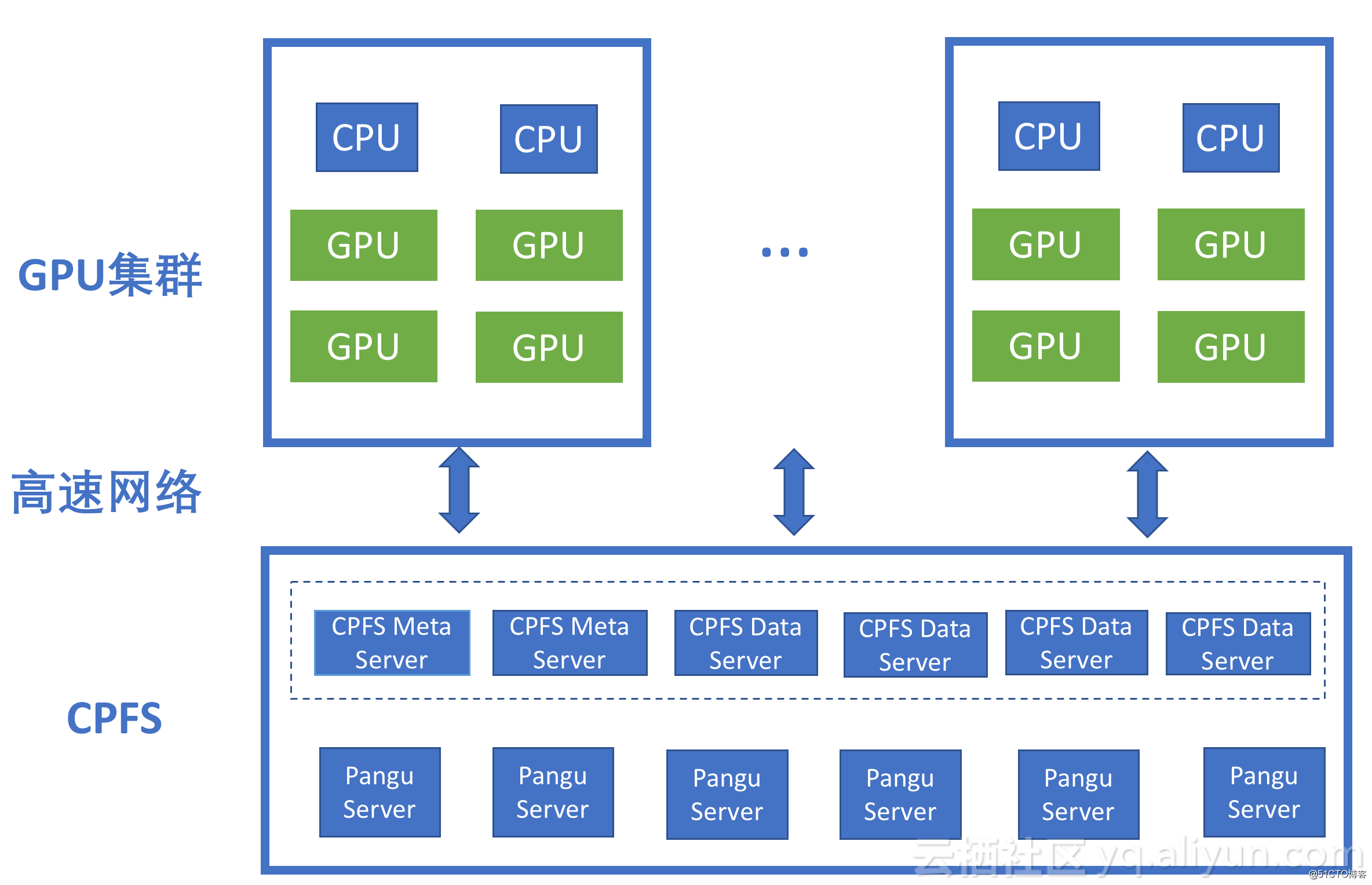
另外,CPFS提供了統一的命令空間,方便了數據在整個AI數據處理流程中的共享和流動,避免了不必要的數據拷貝,簡化了數據管理的流程,方便了數據生命周期的管理。
案例分析
我們最近在跟某深度學習領域客戶的合作中,在訓練場景中使用了CPFS,得到了客戶的認可。客戶的訓練場景中,訓練集中的文件都是jpg格式的小圖片,每個圖片大概20KB~100KB,每個訓練集容量不一定,在幾個TB到幾十個TB之間。訓練機采用的是一機四卡的GPU服務器,總共四臺。
訓練開始之前,需要先將這些訓練集拷貝到CPFS中,通常是拷貝訓練集的壓縮文件,然後再在CPFS來解壓。解壓過程中,會將數量眾多的小文件直接保存到CPFS目錄下。這時相當於在CPFS上寫入海量的小文件,對文件系統的寫入的IOPS要求比較高。訓練過程中,訓練機會從CPFS上讀取數量眾多的小文件,進行模型的訓練和修正。訓練過程中,主要要求保證讀的IOPS。
客戶希望在CPFS上,達到單個節點3W的File creation的IOPS才能滿足需求。我們通過以下優化方法,最終在公有雲CPFS上達到了用戶的要求:
1.系統架構優化:
? 合理配置CPFS節點的CPU,內存配置,網絡,磁盤,確保性能匹配;
? 合理分配CPFS中的元數據節點和數據節點,以及數據存儲和元數據存儲的容量;
2.調整CPFS的優化參數,針對小文件進行參數調優
經過上述優化方法,最終達到了單客戶端File creation 3.5W的最高性能,獲得客戶認可。
總結
CPFS以其超高的穩定性,良好的擴展性,為AI/DL提供了高帶寬,高IOPS的統一的命名空間的文件服務,滿足其需求。
CPFS不僅支持公有雲版本的彈性使用,支持存儲包的付費模式,無縫對接阿裏雲AI生態;同時支持以專有雲的形式輸出,滿足不同客戶的需求。
阿裏雲CPFS並行文件系統,在高穩定性的前提下,為AI提供高帶寬,高IOPS的文件存儲服務,簡化了整個AI的數據處理流程,為AI行業提供了一種高效穩定的文件存儲解決方案。
原文鏈接
本文為雲棲社區原創內容,未經允許不得轉載。
阿裏雲CPFS在人工智能/深度學習領域的實踐