
spark成長之路(1)spark究竟是什麽?
今年6月畢業,來到公司前前後後各種事情折騰下來,8月中旬才入職。本以為終於可以靜下心來研究技術了,但是又把我分配到了一個幾乎不做技術的解決方案部門,導致現在寫代碼的時間都幾乎沒有了,所以只能在每天下班後留在公司研究一下自己喜歡的技術,搞得特別晚才回,身心俱疲。
唉~以前天天寫代碼時覺得苦逼,現在沒得代碼寫了,反而更累了。。。
言歸正傳,這次準備利用空余的時間,好好研究下大數據相關的技術,也算是彌補下自己的技術短板吧。這一個系列的文章是我從一個大數據小白開始學習的過程,不知道我究竟能學到哪個程度,也不清楚自己是否會半途而廢,但是希望能盡量堅持下去,也希望看到這一系列博客的讀者能更我一起努力,一起進步!
首先我們來看一下spark究竟是什麽。相信很多讀者跟我一樣,聽說過hadoop,也知道spark,更知道spark是現在最火的大數據技術,所以一直有一個疑問:spark是不是替代能夠hadoop的下一代大數據技術?答案是:不是!
首先我們看看spark的官網介紹:Apache Spark is a fast and general-purpose cluster computing system. It provides high-level APIs in Java, Scala, Python and R, and an optimized engine that supports general execution graphs. It also supports a rich set of higher-level tools including Spark SQL for SQL and structured data processing, MLlib for machine learning, GraphX for graph processing, and Spark Streaming.
再來看看hadoop的官網介紹:The Apache Hadoop software library is a framework that allows for the distributed processing of large data sets across clusters of computers using simple programming models. It is designed to scale up from single servers to thousands of machines, each offering local computation and storage. Rather than rely on hardware to deliver high-availability, the library itself is designed to detect and handle failures at the application layer, so delivering a highly-available service on top of a cluster of computers, each of which may be prone to failures.註意到,在官網的介紹中,hadoop只包含了4個模塊:
- Hadoop Common: The common utilities that support the other Hadoop modules.
- Hadoop Distributed File System (HDFS?): A distributed file system that provides high-throughput access to application data.
- Hadoop YARN: A framework for job scheduling and cluster resource management.
- Hadoop MapReduce: A YARN-based system for parallel processing of large data sets.
仔細比對就能明白,其實spark只是一個計算框架,它的能力是在現有數據的基礎上提供一個高性能的計算引擎,然後提供一些上層的處理工具比如做數據查詢的Spark SQL、做機器學習的MLlib等;而hadoop的功能則更加全面,它是包括了數據存儲(HDFS)、任務計劃和集群資源管理(YARN)以及離線並行計算(MapReduce)的一整套技術棧。因此可以看出,spark其實是依賴於第三方的數據源的,但這也是spark靈活的地方,它能夠配合HBase、Hive,以及關系型數據庫Oracle、Mysql等多種類型的數據工作。
說到這兒,如果你還沒明白spark和hadoop的關系的話,我用一張圖告訴你:

這個是hadoop2.x的生態系統架構圖,可以看到人們現在甚至已經把spark納入到hadoop的生態之中了(雖然這種說法是否妥當還需驗證),足以見證:spark僅僅只是一個計算框架,它不能,也沒有必要來替代hadoop,它存在最大的價值就是彌補MapReduce計算性能上的不足,提供超越其數倍甚至數十倍的計算能力。因此,我們可以將spark與MapReduce對標起來。
這裏補充一個題外內容:hive和hbase的關系,有一個博客我覺得寫的很好,於是接取下來自https://blog.csdn.net/zx8167107/article/details/79265537
HIVE:
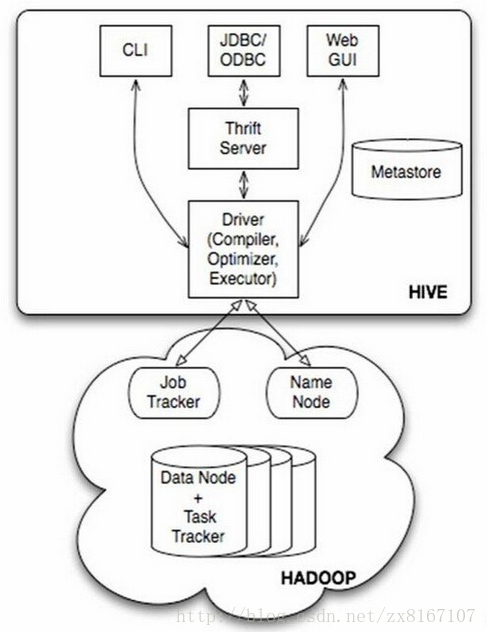
首先說說hive,眾所周知是一款開源的數據倉庫
1、hive不是數據庫,而是數據倉庫,主要依賴於hadoop來實現
2、底層文件系統是hadoop的hdfs,實現對hdfs上結構化數據的SQL操作HQL,速度較慢
3、計算引擎是hadoop的mapreduce
4、依靠存儲在其他關系型數據庫metastore來對hdfs結構化數據進行管理,實現類似數據庫的功能
5、不具備數據庫的一些主鍵、索引、update操作等特性,但是提供了分區、塊索引、SQL等特性
6、比較適合存儲海量的全量(歷史+更新)軌跡數據,比對數據進行批量的挖掘、分析等操作
總結一下,hive是基於hadoop實現的數據倉庫,適合存儲海量全量數據,支持類SQL操作,性能相對較差,數據存儲
有一定的限制,不支持更新、索引等事務。適合海量數據的挖掘和分析,通俗一點來說,hive其實就是借助mysql等數據庫在
hadoop上層套了一個殼,來實現對hdfs上結構化數據的映射,為上層提供sql服務。
HBASE:
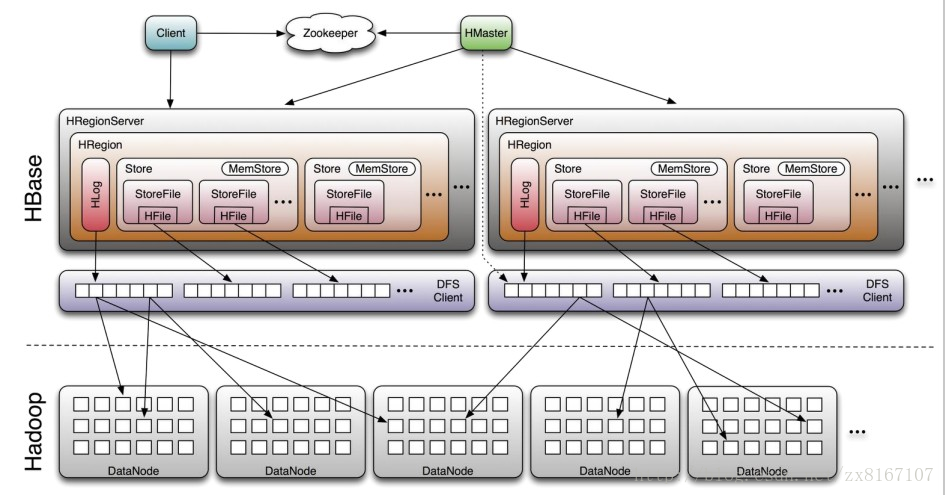
即Hadoop databse,顧名思義就是一個hadoop的數據庫
1、nosql數據庫之一,基於列式存儲(列族),適合海量半結構化數據的存儲和檢索
2、不支持SQL、適合海量、帶時間序列的數據的存儲和檢索、性能較好
3、原生支持基於rowkey的一級索引,rowkey按照字典序進行排序
4、運算執行引擎是hbase自身提供、底層存儲基於hdfs
總結一下,hbase是NOSQL數據庫的一種,基於分布式列式存儲,適合海量半結構化帶時間序列的數據的存儲和檢索,性能較優秀,hbase底層存儲依賴於hdfs,與rdbms的區別與其他nosql類似,比如不支持SQL、事務性相對較差等等。
-----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------
綜上,hbase是數據庫、hive是數據倉庫,而這有很大的區別、也有很多類似的地方比如都屬於hadoop生態圈、存儲都基於hdfs等。一般來說用hive作為海量結構化全量數據的存儲、運算、挖掘、分析;hbase用來作為海量半結構化數據的存儲、檢索;這二者可以很好協同工作,hive上計算完的結果放在hbase中供檢索,也可以將hbase裏面的結構化數據和hive相結合,實現對hbase的sql操作等等。在大數據架構中,Hive和HBase是協作關系,數據流一般如下圖:
通過ETL工具將數據源抽取到HDFS存儲;
通過Hive清洗、處理和計算原始數據;
HIve清洗處理後的結果,如果是面向海量數據隨機查詢場景的可存入Hbase
數據應用從HBase查詢數據;
spark成長之路(1)spark究竟是什麽?