
數據庫優化的幾個階段
大家在面試的時候,是否遭遇過,面試官詢問
那這個問題應該怎麽答呢?其實寫這個題材的原因是我這幾天看到各公眾號轉的一篇數據庫調優的知識(不上鏈接了),我就稍微翻了幾下,上面動不動就來說要對數據庫進行水平拆分,我就想反問各位讀者,你們幾個人經歷過水平拆分?現在很多文章,實踐性實在太差,只能說純理論分析。
這篇文章最早來自知乎的一個提問,我在其基礎上完善了一下。
第一階段 優化sql和索引
這才是調優的第一階段啊,為什麽呢?
因為這一步成本最低啊,不需要加什麽中間件。你沒經過索引優化和SQL優化,就來什麽水平拆分,這不是坑人麽。
那步驟是什麽樣呢?我說個大概
(1)用慢查詢日誌定位執行效率低的SQL語句
(2)用explain分析SQL的執行計劃
(3)確定問題,采取相應的優化措施,建立索引啊,等
我就不舉例了,因為如何優化SQL的文章,一抓一大把,再貼過來,讀者看著也累。
第二階段 搭建緩存
在優化sql無法解決問題的情況下,才考慮搭建緩存。畢竟你使用緩存的目的,就是將復雜的、耗時的、不常變的執行結果緩存起來,降低數據庫的資源消耗。
這裏需要註意的是:搭建緩存後,系統的復雜性增加了。你需要考慮很多問題,比如:
緩存和數據庫一致性問題?(比如是更緩存,還是刪緩存),這點可以看我的一篇文章《數據庫和緩存雙寫一致性方案解析》。
緩存擊穿、緩存穿透、緩存雪崩問題如何解決?是否有做緩存預熱的必要。不過我猜,大部分中小公司應該都沒考慮。這點可以看我的另一篇《分布式之redis復習精講》
第三階段 讀寫分離
緩存也搞不定的情況下,搞主從復制,上讀寫分離。在應用層,區分讀寫請求。或者利用現成的中間件mycat或者altas等做讀寫分離。
需要註意的是,只要你敢說你用了主從架構,有三個問題,你要準備:
(1)主從的好處?
回答:實現數據庫備份,實現數據庫負載均衡,提高數據庫可用性
(2)主從的原理?
回答:如圖所示(圖片不是自己畫的,偷懶了)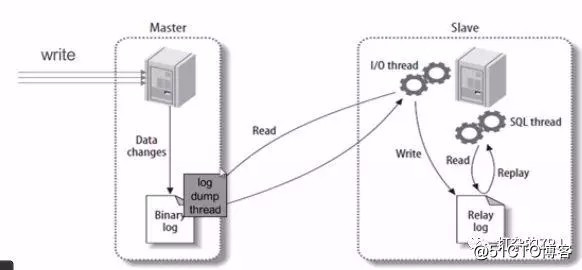
主庫有一個log dump線程,將binlog傳給從庫
從庫有兩個線程,一個I/O線程,一個SQL線程,I/O線程讀取主庫傳過來的binlog內容並寫入到relay log,SQL線程從relay log裏面讀取內容,寫入從庫的數據庫。
(3)如何解決主從一致性?
回答:這個問題,我不建議在數據庫層面解決該問題。根據CAP定理,主從架構本來就是一種高可用架構,是無法滿足一致性的。
哪怕你采用同步復制模式或者半同步復制模式,都是弱一致性,並不是強一致性。所以,推薦還是利用緩存,來解決該問題。
步驟如下:
1、自己通過測試,計算主從延遲時間,建議mysql版本為5.7以後,因為mysql自5.7開始,多線程復制功能比較完善,一般能保證延遲在1s內。不過話說回來,mysql現在都出到8.x了,還有人用5.x的版本麽。
2、數據庫的寫操作,先寫數據庫,再寫cache,但是有效期很短,就比主從延時的時間稍微長一點。
3、讀請求的時候,先讀緩存,緩存存在則直接返回。如果緩存不存在(這時主從同步已經完成),再讀數據庫。
第四階段 利用分區表
說句實在話,你們面試的時候,其實可以略過這個階段。因為很多互聯網公司都不建議用分區表,我自己也不太建議用分區表,采用這個分區表,坑太多。
這裏引用一下其他文章的回答:
什麽是mysql的分區表?
回答:所有數據還在一個表中,但物理存儲根據一定的規則放在不同的文件中。這個是mysql支持的功能,業務代碼不需要改動,但是sql語句需要改動,sql條件需要帶上分區的列。
缺點
(1)分區鍵設計不太靈活,如果不走分區鍵,很容易出現全表鎖
(2)在分區表使用ALTER TABLE … ORDER BY,只能在每個分區內進行order by。
(3)分區表的分區鍵創建索引,那麽這個索引也將被分區。分區鍵沒有全局索引一說。
(4)自己分庫分表,自己掌控業務場景與訪問模式,可控。分區表,研發寫了一個sql,都不確定該去哪個分區查,不太可控。
…不列舉了,不推薦
第五階段 垂直拆分
上面四個階段都沒搞定,就來垂直拆分了。垂直拆分的復雜度還是比水平拆分小的。將你的表,按模塊拆分為不同的小表。大家應該都看過《大型網站架構演變之路》,這種類型的文章或者書籍,基本都有提到這一階段。
如果你有幸能夠在什麽運營商、銀行等公司上班,你會發現他們一個表,幾百個字段都是很常見的事情。所以,應該要進行拆分,拆分原則一般是如下三點:
(1)把不常用的字段單獨放在一張表。
(2)把常用的字段單獨放一張表
(3)經常組合查詢的列放在一張表中(聯合索引)。
第六階段 水平拆分
OK,水平拆分是最麻煩的一個階段,拆分後會有很多的問題,我再強調一次,水平拆分一定是最最最最後的選擇。從某種意義上,我覺得還不如垂直拆分。因為你用垂直拆分,分成不同模塊後,發現單模塊的壓力過大,你完全可以給該模塊單獨做優化,例如提高該模塊的機器配置等。如果是水平拆分,拆成兩張表,代碼需要變動,然後發現兩張表還不行,再變代碼,再拆成三張表的?水平拆分後,各模塊間耦合性太強,成本太大,慎重。
數據庫優化的幾個階段