
數據庫分庫分表的應用場景及解決方案
數據庫分庫分表的應用場景及解決方案
現實業務場景中,為了保障客戶體驗並滿足業務的線性增長。會對數據量巨大,且業務會始終進行的產品進行分表分庫策略。但是如何合理的根據業務采取爭取的分表分庫策略至關重要。下面以具體實例來進行分析。
? 場景一:用戶中心,單key業務如何進行數據庫切分 ? 場景二:訂單中心,多key業務如何進行數據庫切分場景一:用戶中心數據庫切分架構實踐|場景介紹
用戶中心是一個十分常見的業務系統,涵蓋用戶登錄、註冊、信息查詢與修改等服務。
用戶的核心元數據為:
User(uid,login_name,nickname,password,sex,age)
其中 ● uid :用戶ID,主鍵
● login_name,nickname,password,sex,age :用戶的其他屬性
在業務初期,單表單庫就能滿足業務需求:

場景一:用戶中心數據庫切分方法|範圍法
當數據量越來越大時,需要對數據庫進行水平切分,常見的切分算法有“範圍法”和“哈希法”。
範圍法:以用戶中心的業務uid為劃分依據,將數據水平切分到兩個數據庫實例上去:

範圍法的優點是:
? 切分策略簡單,根據uid,按照範圍,user- center很快能夠定位到數據在哪個庫上 ? 擴容簡單,如果容量不夠,只要增加user-db3即可範圍法的不足是:
? uid必須要滿足遞增的特性 ? 數據量不均,新增的user-db3,在初期的數據會比較少 ? 請求量不均,一般來說,新註冊的用戶活躍度會比較高,故user-db2往往會比user-db1負載要高,導致服務器利用率不平衡場景一:用戶中心數據庫切分方法|哈希法
哈希法:以用戶中心的業務uid為劃分依據,將數據水平切分到兩個數據庫實例上去:

哈希法的優點是:
?切分策略簡單,根據uid,按照範圍,user- center很快能夠定位到數據在哪個庫上 ?數據量均衡:只要uid是均衡的,數據在各個庫上的分布一定是均衡的 ?請求量均衡:只要uid是均衡的,負載在各個庫上的分布一定是均衡的哈希法的不足是:
場景一:用戶中心數據查詢需求分析
任何脫離業務的架構設計都是耍流氓,在進行架構討論之前,首先要對業務進行簡要分析,看看表結構上有哪些查詢需求。
根據業務經驗,用戶中心往往有以下幾類業務需求:
(1)用戶側,前臺訪問,最典型的有兩類需求
用戶登錄:通過login_name/email/phone查詢用戶實體,1%的請求屬於這種類型。
用戶信息查詢:登錄之後,通過uid來查詢用戶的實例,99%請求屬於這種類型。
用戶側查詢的基本特點是:基本是單條記錄查詢,訪問量大,服務要求高可用,並且對一致性要求較高。
(2)運營側,後臺訪問。需要滿足產品及運營層面的各類需求,訪問模式各異,按照年齡、性別、登錄時間、註冊時間等屬性來 進行查詢。運營側需求的的基本特點是:大量的批量分頁查詢需求,訪問量較低,對可用性要求不高,對一致性的要求也沒有這麽嚴格。
場景一:用戶中心數據查詢需求解決方案-用戶側
1.索引表法:思路:uid可以直接定位到數據庫,login_name不可以直接定位到庫。建立login_name到login_id的映射關系。
解決方案:
? 建立一個索引表記錄login_name->uid的映射關系 ? 用login_name來訪問時,先通過索引表查詢到uid,再定位相應的庫 ? 索引表屬性較少,可以容納非常多數據,一般不需要分庫 ? 如果數據量過大,可以通過login_name來分庫不足:多一次數據庫查詢,性能下降一倍。
2.緩存映射法:
思路:訪問索引表的性能比較低。將映射放在緩存中可以獲得更好的性能體驗。
解決方案:
? login_name查詢先到cache中查詢uid,再根據uid定位數據庫 ? 假設cachemiss,采用掃全庫法獲取login_name對應的uid,放入cache ? login_name到uid的映射關系不會變化,映射關系一旦放入緩存,不會更改,無需淘汰,緩存命中率超高 ? 如果數據量過大,可以通過login_name進行cache水平切分不足:多一次cache查詢。
3.login_name生成uid
思路:不進行遠程查詢,由login_name直接得到uid
解決方案:
? 在用戶註冊時,設計函數login_name生成uid,uid=f(login_name),按uid分庫插入數據 ? 用login_name進行登錄時,先通過函數計算出uid,再由uid路由到對應數據庫進行查詢。不足:對login_name到uid的生成函數要求較高,有uid生成沖突的風險
4.login_name基因融入uid
思路:從login_name抽取“基因” 融入uid中。

解決方案:
? 在用戶註冊時,設計函數login_name生成4bit基因,login_name_gene=f(login_name),如上圖粉色部分 ? 同時,生成60bit的全局唯一id,作為用戶的標識,如上圖綠色部分 ? 接著把4bit的login_name_gene也作為uid的一部分,如上圖屎黃色部分 ? 生成64bit的uid,由id和login_name_gene拼裝而成,並按照uid分庫插入數據 ? 用login_name來訪問時,先通過函數由login_name再次復原4bit基因,login_name_gene=f(login_name),通過 login_name_gene%8直接定位到庫場景一:用戶中心數據查詢需求解決方案-運營側
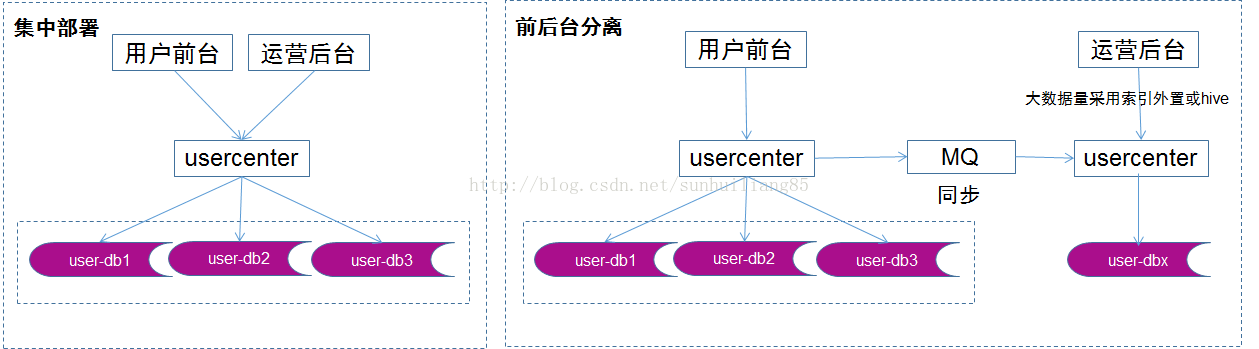
後臺運營側的查詢需求各異,基本是批量的分頁查詢,計算量和返回數據量較大,比較消耗數據庫性能。此時如果後臺業務和前臺業務共用一批服務和同一個數據庫。有可能會導致後臺少數幾個請求的批量查詢的低效訪問造成數據庫服務器cpu瞬時100%,影響前臺用戶的正常訪問。另外,由於後臺業務的查詢需求多種多樣,需要在數據庫上建立多種索引,這些索引會占用大量的內存和磁盤,從而造成前臺業務的uid/login_name的查詢和寫入性能大幅度降低,處理時間增長。對這一類業務,應該采用“前後臺分離”的架構方案:
場景二:訂單中心數據查詢需求分析
還是那句話,任何脫離業務的架構設計都是耍流氓,在進行架構討論之前,首先要對業務進行簡要分析,看看表結構上有哪些查詢需求。
根據業務經驗,訂單中心往往有以下幾類業務需求:
(1)用戶側,前臺訪問,最典型的有三類需求
訂單實體查詢:通過oid查詢訂單實體,90%都是這種需求。
用戶訂單列表查詢:通過buyer_id分頁查詢用戶歷史訂單列表,9%流量屬於這種需求。
商家訂單列表查詢:通過seller_uid分頁查詢商家歷史訂單列表,1%流量屬於這類需求。
前臺訪問的特點是:吞吐量大,服務要求高可用,對一致性要求較高。其中商家對一致性要求較低,可以接受一定程度的延遲。
(2)運營側,後臺訪問。根據產品、運營需求,訪問模式各異:按照時間,架構,商品和詳情來進行查詢
後臺訪問的特點:運營側的查詢基本上是批量的分頁查詢,訪問量低,對可用性一致性的要求不高,允許秒甚至十秒級別的查詢延遲。
場景二:訂單中心數據查詢需求解決方案
後臺運營側的查詢需求各異,基本是批量的分頁查詢,計算量和返回數據量較大,比較消耗數據庫性能。此時如果後臺業務和前臺業務共用一批服務和同一個數據庫。有可能會導致後臺少數幾個請求的批量查詢的低效訪問造成數據庫服務器cpu瞬時100%,影響前臺用戶的正常訪問。對這一類業務,應該采用“前後臺分離”的架構方案:前臺業務架構不變,站點訪問,服務分層,數據庫水平切分。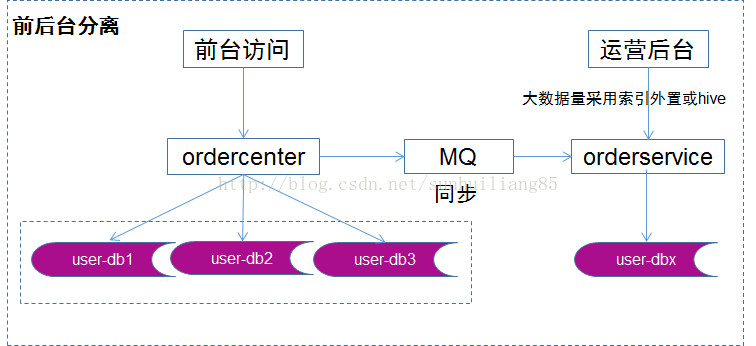
場景二:訂單中心數據庫切分方法
明確了訂單中心的訪問需求後,問題轉化為,前臺的oid,buyer_id,seller_id如何來進行數據庫的水平切分呢?
需要同時滿足以下條件:
1.根據buyer_uid%n,可以定位到數據庫
2.根據oid%n,可以定位到數據庫
3.根據seller_uid%n,可以定位到數據庫
以上業務是一個1:N(1個買家:N個訂單)和N:N(1個買家:N個賣家, 1個賣家:N個買家)的業務場景,對於“多對多”的業務,水平切分應該使用“數據冗余法”
場景二:訂單中心數據庫切分方法
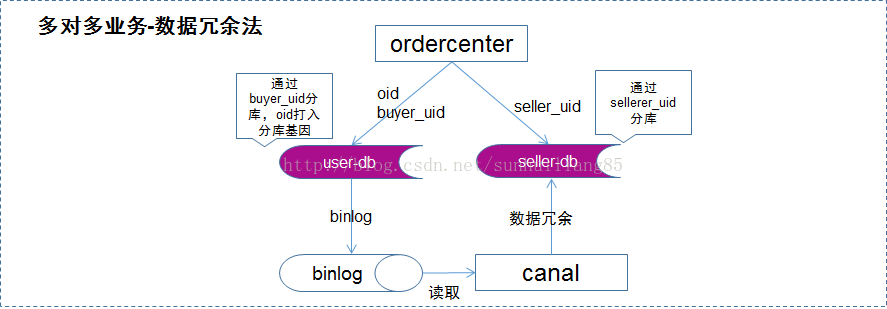
? 當有訂單生成時,通過buyer_uid分庫,oid中融入分庫基因,寫入DB-buyer庫 ? 通過線下異步的方式,通過binlog+canal,將數據冗余到DB-seller庫中 ? buyer庫通過buyer_uid分庫,seller庫通過seller_uid分庫,前者滿足oid和buyer_uid的查詢需求,後者滿足seller_uid的查詢需求
場景二:訂單中心數據庫切分方法|數據冗余法
為什麽要冗余數據?
互聯網數據量很大的業務場景,往往數據庫需要進行水平切分來降低單庫數據量。
水平切分會有一個patitionkey,通過patition key的查詢能夠直接定位到庫,但是非patitionkey上的查詢可能就需要掃描多個庫了。
此時常見的架構設計方案,是使用數據冗余這種反範式設計來滿足分庫後不同維度的查詢需求。
例如:訂單業務,對用戶和商家都有訂單查詢需求:
Order(oid,info_detail);
T(buyer_uid,seller_uid,oid);
如果用buyer_uid來分庫,seller_uid的查詢就需要掃描多庫。
如果用seller_uid來分庫,buyer_uid的查詢就需要掃描多庫。
此時可以使用數據冗余來分別滿足buyer_uid和seller_uid上的查詢需求:
T1(buyer_uid,seller_uid,oid)
T2(seller_uid,buyer_uid,oid)
同一個數據,冗余兩份,一份以buyer_uid來分庫,滿足買家的查詢需求;一份以seller_uid來分庫,滿足賣家的查詢需求。
場景二:訂單中心數據庫切分方法|如何實現數據冗余
1.服務同步雙寫
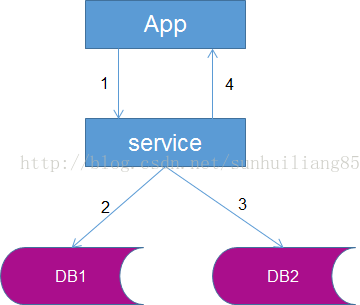
服務同步雙寫,即由服務層同步寫冗余數據。
流程如右圖:
(1)業務應用代用服務層,寫入數據
(2)服務層將數據寫入DB1
(3)服務層將數據寫入DB2
(4)服務層返回新增數據成功給業務應用
優點:
?簡單,服務層由單寫,改為兩次寫人 ?數據一致性較高,雙寫成功後才返回缺點:
? 因為由單寫變為了兩次寫入,請求時間增長 ? 數據仍有可能不一致(數據寫入DB1後,服務宕機或重啟,則數據無法寫人DB2)3.線下異步雙寫
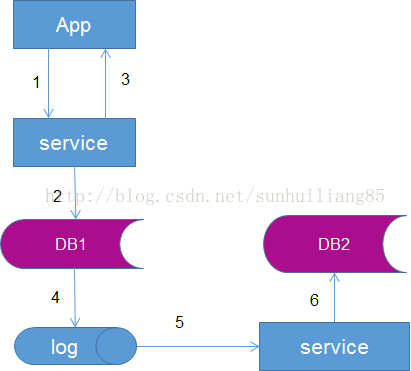
為了屏蔽“復雜性”,數據雙寫由線下服務或者任務來完成,不再由服務層完成。
流程如右圖:
(1)業務應用代用服務層,寫入數據
(2)服務層將數據寫入DB1
(3)服務層返回新增數據成功給業務應用
(4)數據會被寫入到數據庫的log中
(5)線下服務或者任務讀取數據庫log
(6)線下服務或者任務插入T2數據
優點:
?數據雙寫與業務完全解耦 ?請求處理時間短缺點:
?返回業務新增成功時,會存在一個數據不一致的時間窗口,但能保證最終一致性 ?數據一致性依賴於線下服務或者任務的可凹陷數據庫分庫分表的應用場景及解決方案