
使用elasticsearch和filebeat做日誌收集
https://www.elastic.co/guide/en/beats/filebeat/current/configuring-ingest-node.html
1 使用ingest功能
1.1 定義一個pipeline
例如grib2-pipeline.json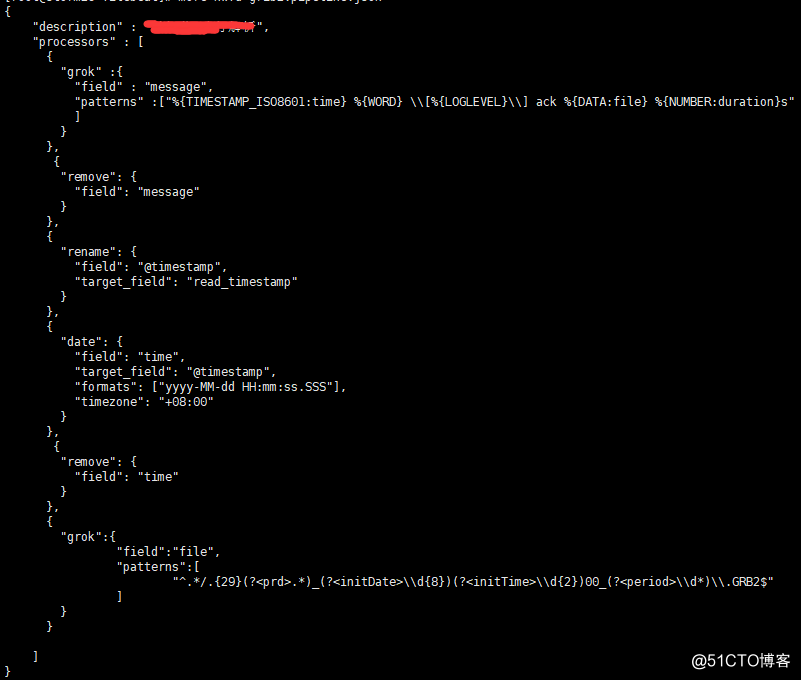
grok可以使用預定義Patterns(%{Pattern:name}匹配提取字段),也可以直接使用正則表達式(分組命名提取字段)
1.2 將pipeline添加到elasticsearch中
curl -H ‘Content-Type: application/json‘ -XPUT ‘http://localhost:9200/_ingest/pipeline/grib2‘ [email protected]
1.3 如何使用ingest功能
https://www.elastic.co/guide/en/elasticsearch/reference/6.4/ingest.html
PUT my-index/_doc/my-id?pipeline=my_pipeline_id
{
"foo": "bar"
}
2 配置filebeat
2.1 新建 ack.yml文件
filebeat.inputs:
- type: log
paths:
- /opt/deploy/storm/logs/workers-artifacts/grib2*/*/worker.log
include_lines: [‘ack ‘]
output.elasticsearch:
hosts: ["127.0.0.1:9200"]
pipeline: grib2
index: "grib2-%{+yyyy.MM.dd}"
setup.template.name: "grib2"
setup.template.pattern: "grib2-*"
通過setup.template.name|pattern 和 output.elasticsearch.index配置索引的名稱,便於將來的使用。
2.2 啟動filebeat
nohup ./filebeat -c ack.yml &
3 檢索日誌
http://localhost:9200/grib2*/_search
使用elasticsearch和filebeat做日誌收集