
阿裏P8架構師告訴你什麽是分布式架構
我們都知道,當今無論在BAT這樣的大公司,還是各種各樣的小公司,甚至是傳統行業剛轉互聯網的企業都開始使用分布式架構,那麽什麽叫分布式架構呢?分布式架構有什麽好處呢?分布式架構經過了怎樣的發展呢?是哪家企業開啟了分布式架構的時代呢?讀完本文,你就會得到這些答案,下面讓我們一起來開啟分布式概述的奇妙之旅吧!
二、分布式架構的發展歷史
1946年2.14日,那是一個浪漫的情人節 , 世界上第一臺電子數字計算機在美國賓夕法尼亞大學誕生了,她的名字叫ENIAC。這臺計算機占地170平米、重達 30 噸,每秒可以進行 5000 次加法運算。
第一臺電子計算機誕生以後,就意味著一個日新月異的 IT 時代到來了。單臺計算機的性能不斷得到提升,從最早的 8 位 CPU 到現在的 64 位 CPU;從早期的 MB 級內存到現在的 GB 級別內存;從慢速的機械存儲到現在的固態 SSD 硬盤存儲。
ENIAC 之後,電子計算機就進入了 IBM 主導的大型機時代。1964 年 4 月 7 日,在吉恩.阿姆達爾(IBM 大型機之父, 被認為是有史以來最偉大的計算機設計師之一)的帶領下,耗費 50 億美元,歷時三年,第一臺 IBM 大型機 SYSTEM/360 誕生了。這使得 IBM 在 20 世紀 50~60 年代統治著整個大型計算機工業,奠定了 IBM 計算機帝國的基礎。IBM 大型機曾支撐美國航天登月計劃,IBM 主機一直服務於金融等核心行業的關鍵領域。由於超強的計算能力和高可靠性,即使在 X86 和雲計算高速發展的背景下,IBM 的大型機依然牢牢占據著一定的高端市場份額。
20 世紀 80 年代,在大型機霸權的時代下,計算機的架構同時向兩個方向發展:
1、以 CISC (微處理器執行的計算機語言指令集) CPU 為架構的面向個人、價格便宜的PC。
2、以 RISC (精簡指令集計算機) CPU 為架構的面向企業、價格昂貴的小型 UNIX 服務器。
三、分布式架構發展的裏程碑
大型主機憑借著大型機超強的計算和 I/O 處理能力、安全性、 穩定性等,在很長一段時間內,大型機引領著計算機行業及商業計算領域的發展。而集中式的計算機系統架構也漸漸成為了主流。但是隨著社會的發展,這種架構越來越難以適應企業的需求,比如說:
1.大型主機復雜性高,培養一個能夠熟練運維大型主機的人成本很高。
2.大型主機很貴,一般只有土豪機構(政府、電信、金融)才能用得起。
3.會有單點問題,一旦大型主機出現故障,那整個系統就將處於不可用的狀態。而對於大型機的使用機構來說,這種不可用導致的損失是非常具大的。
阿裏巴巴發起的"去 IOE"運動開啟新時代
IOE 指的是 IBM 小型機、Oracle 數據庫、EMC 的高端存儲。阿裏巴巴2009 年“去 IOE”戰略技術總監透露,截止到 2013 年 5 月 17 日阿裏巴巴最後一臺 IBM 小型機在支付寶下線。
為什麽要去 IOE?
隨著業務的快速發展,阿裏巴巴業務量和數據量呈爆發性增長,傳統集中式 Oracle 數據庫架構在系統的擴展性方面遭遇到了瓶頸。 傳統的商業數據庫軟件(Oracle,DB2)多以集中式架構為主, 那麽這些傳統數據庫軟件的最大特點就是將所有的數據都集中在 一個數據庫中,只能依靠大型高端設備來提供高處理能力和擴展性。 集中式數據庫的擴展性主要采用向上擴展(Scale up)的方式, 通過增加 CPU、內存、磁盤等方式提高系統處理能力。這種集中式數據庫的架構,使得數據庫成為了整個系統的瓶頸,已經越來越不能適應海量數據對計算能力的要求。
四、分布式系統的意義
之所以要發展分布式系統架構,是因為單機系統存在著如下諸多缺點等待被解決:
升級單機處理能力的性價比越來越低,我們知道單機的處理能力主要依靠 CPU、內存、磁盤。通過升級硬件來這種垂直擴展的方式來提升性能,成本會越來越高。性價比會越來越低。
單機處理能力存在瓶頸,並且單機處理能力存在瓶頸,CPU、內存、磁盤都會有自己的性能瓶頸, 就算你是土豪不惜成本去提升硬件,但是硬件的發展速度和性能也還是有限制的。
穩定性和可用性這兩個指標很難達到
最後就是單機系統存在可用性和穩定性的問題,這兩個指標又是我們亟待要去解決的問題。
五、分布式架構的常見概念
1.集群
小張開了一家小飯店,剛開始的時候店裏只有一個廚師,切菜洗菜備料炒菜全幹。後來由於飯香甜可口,人流量越來越多了,一個廚師忙不過來了,小張又請了兩個廚師,那麽這時候三個廚師炒一樣的菜,做相同的切菜洗菜備料炒菜等工作,那這三個廚師的關系是集群。也就意味著來一個顧客,只有其中的一個廚師會為這個顧客服務。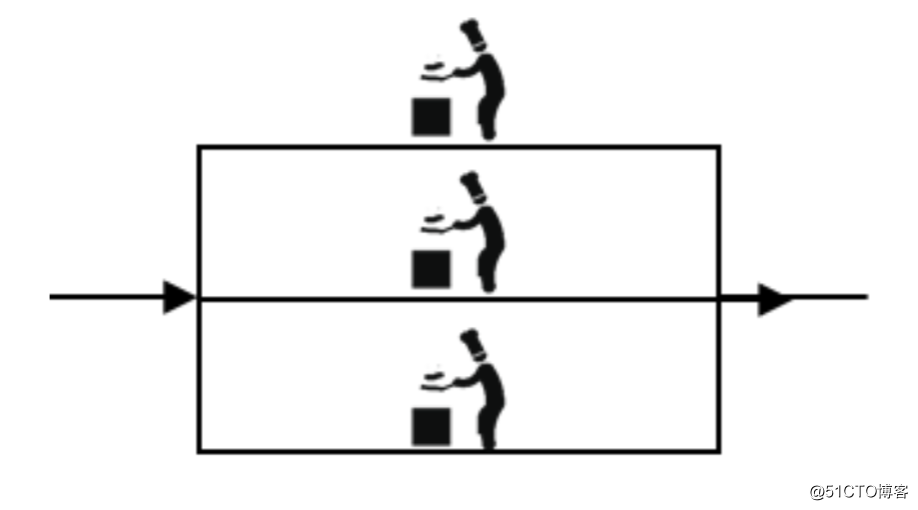
2.分布式
又經過一段時間,店裏的生意更加火爆了,小張為了讓廚師們能專心炒菜,把菜做到極致,又請了個配菜師負責切菜、備菜、備料,那麽廚師和配菜師的關系是分布式,後來一個配菜師也忙不過來了,小張就又請了兩個配菜師,三個配菜師關系也是集群。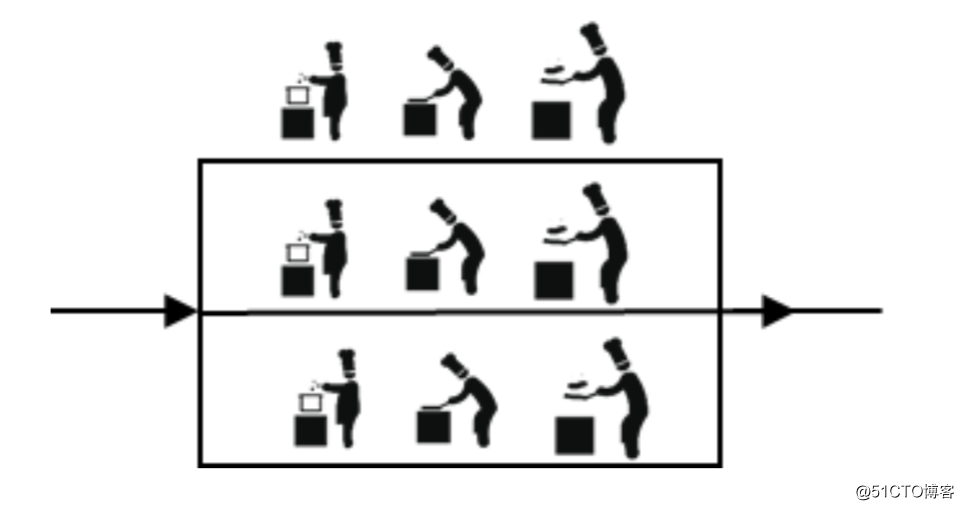
3.節點
節點是指一個可以獨立按照分布式協議完成一組邏輯的程序個體。在具體的項目中,一個節點表示的是一個操作系統上的進程。 那這裏的每一個配菜師和廚師都是一個節點。
4.副本機制
副本(replica/copy)是指在分布式系統中為數據或服務提供的冗余。 數據副本指在不同的節點上持久化同一份數據,當某一個節點出現數據丟失時,可以從副本上恢復數據。數據副本是分布式系統中解決數據丟失問題的唯一手段。 服務副本表示多個節點提供相同的服務,通過主從關系來實現服務高可用的方案。
5.中間件
中間件位於操作系統提供的服務之外,但又不屬於應用,他是位於應用和系統層之間的、為開發者方便的處理通信、輸入輸出的一類軟件,能夠讓用戶只關心自己應用的部分。
六、分布式領域中馮諾依曼模型的變化
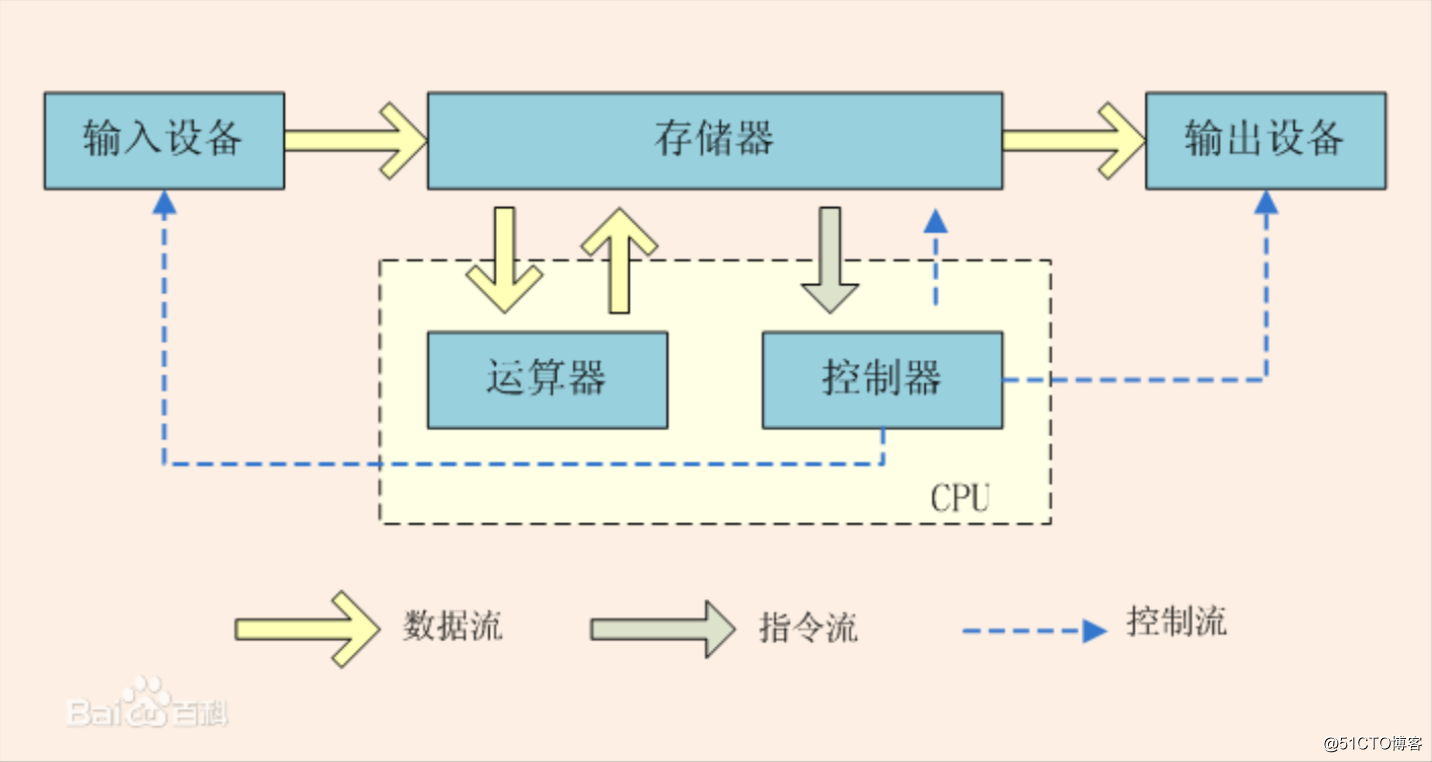
上圖是經典理論-馮.諾依曼體系,計算機硬件由運算器、 控制器、存儲器、輸入設備、輸出設備五大部分組成。不管架構怎麽變化,計算機仍沒有跳出該體系的範疇。
輸入設備的變化
分布式系統架構中,輸入設備可以分兩類:第一類是互相連接的多個節點,在接收其他節點傳來的信息作為該節點的輸入;另一種就是傳統意義上的人機交互的輸入設備了。
輸出設備的變化
分布式系統架構中,輸出也分兩類,一種是系統中的節點向其他節點傳輸信息時,該節點可以看作是輸出設備;另一種就是傳統意義上的人際交互的輸出設備,比如用戶的終端。
控制器的變化
在單機中,控制器指的是 CPU 中的控制器,在分布式系統中,控制器主要的作用是協調或控制節點之間的動作和行為; 比如硬件負載均衡器;LVS 軟負載;規則服務器等等。
運算器
分布式系統中,運算器是由多個節點來組成的。運用多個節點的計算能力來協同完成整個計算任務。
存儲器
分布式系統中,我們需要把承擔存儲功能的多個節點組織在一起, 組成一個整體的存儲器;比如數據庫、redis(key-value 存儲) 。
七、分布式系統的難點
毫無疑問,分布式系統對於集中式系統而言,在實現上會更加 復雜。分布式系統將會是更難理解、設計、構建 和管理的,同 時意味著應用程序的根源問題更難發現。
三態
在集中式架構中,調用一個接口返回的結果只有兩種, 成功或失敗。但是在分布式架構中,會出現“超時”這個狀態。
分布式事務
這其實是一個老生常談的問題,我們都知道事務就是一系列操作的原子性保證,在單機的情況下,我們能夠依靠本機的數據庫連接和組件很輕易的做到事務控制,但在分布式架構下,業務原子性操作很可能是跨服務的,這樣就會導致分布式事務。比如 A 、B 操作分別是在不同服務下的同一個事務內的操作,A 調用 B,如果A可以清楚的知道 B 是否成功提交從而控制自身提交還是回滾,但我們知道在分布式系統調用中會出現一個新狀 態就是超時,就是 A 並無法知道 B 是成功還是失敗,這個時候 A 是提交本地事務還是執行回滾呢?這其實是一個很難的問題,如果要強行保證事務一致性,可以采取分布式鎖,但那樣會增加系統復雜度而且會增大系統的開銷,而且事務跨越的服務越多, 消耗的資源越大,性能越低,那麽最好的解決方案就是避免分布式事務。 還有一種解決方案就是重試機制,但是重試如果不是查詢接口, 久必然涉及到數據庫的變更,如果第一次調用成功但是沒返回成功結果,那調用方第二次調用對調用方來說依然是重試,但是此時對於被調用方來說是重復調用,例如 A 向 B 轉賬,A-100,B + 100,這樣會導致 A 扣了 100,而 B 增加 200。這樣的結果並不是我們期望的,因此需在要寫入的接口做冪等設計(多次調用和單次調用是一樣的效果)。通常可以設置一個唯一鍵,在寫入的時候查詢是否已經存在,避免重復寫入。但是冪等設計的一 個前提就是服務高可用,否則無論怎麽重試都不能調用返回一個明確的結果,那調用方會一直等待,雖然可以限制重試的次數, 但是這已經進入異常狀態了,甚至到了極端情況還需要人肉補償處理。其實根據 CAP 和 BASE 理論,不可能在高可用分布式情況下做到一致性,一般都是最終一致性保證。
負載均衡
為了達到服務高可用,每個服務至少是部署兩臺機器,因為互聯網公司一般使用可靠性不是很高的普通機器, 長期運行宕機概率很高,所以兩臺機器能夠大大降低服務不可用的可能性,而大型項目往往會采用十幾臺甚至上百臺來部署一 個服務,這不僅是保證服務的高可用,更是為了提升服務的 QPS, 但是這樣又帶來一個問題,一個請求過來到底路由到哪臺機器呢? 路由算法很多,有 DNS 路由,如果 session 在本機,還會根據用戶 id 或則 cookie 等信息路由到固定的機器,當然現在應用服務器為了擴展的方便都會設計為無狀態的,session 會保存到專有的 session 服務器,所以一般不會涉及到拿不到 session 問 題。那路由規則是隨機獲取麽?這是一個方法,但是據我所知, 實際情況肯定比這個復雜得多,在一定範圍內隨機,但是在大範圍也會分為很多個域,比如如果為了保證異地多活的多機房, 誇機房調用的開銷太大,肯定會優先選擇同機房的服務,這個 要參考具體的機器分布來考慮。
一致性
數據被分散或者復制到不同的機器上,如何保證各臺主機之間的數據一致性將成為一個難點。
故障的獨立性
分布式系統由多個節點組成,整個分布式系統完全出問題的概率是存在的,但是在實踐中出現更多的是某個節點出問題,其他節點都沒問題。這種情況下我們實現分布式系統時需要考慮得更加全面些。
寫在最後:歡迎留言討論,加關註,持續更新!!!
阿裏P8架構師告訴你什麽是分布式架構