
002_阿裏監控平臺的“打怪升級”之路
阿裏巴巴監控平臺經過了這麽多年的發展,與時俱進從最開始的簡單自動化到現在的人工智能的系統運維。在這個人叫做容器下的 AIOps論壇上面,阿裏巴巴集團監控負責人進行了精彩的演講,主題是自動化到智能化的阿裏監控發展之路。這次演講主要分三部分分別是打怪升級、修煉內功、仰望星空。
打怪升級

和大多數的公司一樣,阿裏巴巴最初也采用的是 Nagios+Cacti 的開源模式。
這個組合的最大問題是:不能規模化,一旦數據量達到規模級別之後,就會出現各式各樣的問題。
另外,由於我們對該開源的組合未做深入研究,因此無法對它們進行定制與修改。到了 2009 年,我們決定廢棄該組合,準備自己做一套監控系統。
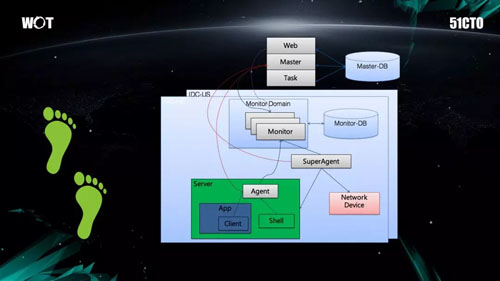
如上圖所示,這個系統支撐了阿裏巴巴後續的五年發展,有一部分到現在還在用。
由於引入了域的概念,即:Monitor Domain。該監控系統的亮點是解決了數據量的問題,並能夠支持水平擴展。在數據庫方面,由於當時尚無 HBase 和 NoSQL 等解決方案,因此我們采用的是 MySQL。但是眾所周知,MySQL 對於監控方面的支持並不好。
後來,在 HBase 成熟之後,我們就把整個數據庫切換到了 HBase 之上。這對開發團隊而言,帶來了許多便利,同時整個系統的監控質量也提升了不少。
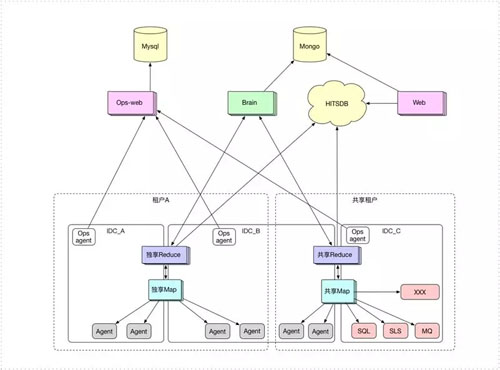
上圖是阿裏巴巴如今最新的一代、也是最重要的監控平臺 Sunfire。在存儲方面,我們之前用的是 HBase,現在則轉為 HiTSDB(High-Performance Time Series Database,高性能時間序列數據庫)。另外在數據采集方面,原來采用是在機器上安裝 Agent 的方式,而現在的系統則主要采集的是日誌,包括:業務方的日誌、系統的日誌、消息隊列的日誌等。
通過對接 SQL,我們將數據接入層抽象出來,同時保持上層的不變,此舉的好處在於體現了“租戶”的概念。
和許多采用推(Push)數據方式的監控系統不同,我們的這套架構是從上往下進行拉(Pull)數據的。
這一點,我們和普羅米修斯系統(Prometheus,它支持多維度的指標數據模型,服務端通過 HTTP 協議定時拉取數據的方式,靈活進行查詢,從而實現監控目的)有著相似之處,不過我們在後臺上會略強一些。
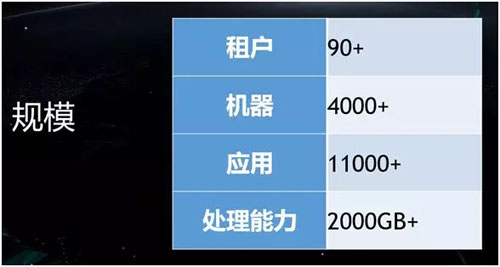
這套系統當前的規模反映在如下方面:
-
內部租戶數為 90 多個。這裏的租戶是指:天貓、淘寶、盒馬、優酷、高德等應用系統。
-
機器數為 4000 多臺。這是去年雙十一時的數量,其中後臺並非純粹是物理機,而是大多數為 4 核 8G 的虛擬機。
-
應用數為 11000 多個。
-
處理能力為每分鐘大概 2 個 T 的數據量。當然,這同樣也是去年雙十一的數值。
修煉內功

下面我們來看看阿裏巴巴現役監控系統的具體特征和能夠解決的業務痛點:
Zero-Copy
因此我們通過優化,讓各臺受監控主機上的 Agent,不再調用任何業務資源、也不做任何處理,直接將原始數據匯聚並“拉”到中心節點。“用帶寬換CPU”這就是我們在設計監控系統的 Agent 時的一個原則。
根據過往的監控經歷,當業務方發現采集到的 CPU 抖動指標居然是監控系統所致的話,他們會寧可不要監控系統。而且,我們甚至都不會對日誌進行壓縮,因為壓縮操作同樣也會用到各個主機的 CPU。
Light-Akka
在框架方面,考慮到 Akka 先進的設計理念和不錯的性能,我們曾使用它來進行構建。
但是後來發現由於它是用 Scala 語言編寫的,消息不能“有且只有一次”進行傳遞,即無法保證 100% 可達。因此我們將自己最需要的部分抽取出來,用 Java 重新予以了實現。
Full-Asynchronous
由於數據量比較大,監控系統在運行的時候,任何一個節點一旦出現阻塞都是致命的。
我們通過將任務下發到 RegisterMapper,來“異步化”該架構的關鍵核心鏈路。
為了使得監控系統的全鏈路都實現“異步化”核心操作,我們可以使用網絡傳輸中的 Unity和 Java 的異步 Http Client 等技術。大家只要稍作修改,便可達到全異步的效果。
LowPower-Agent
由於 Agent 的主要任務就是獲取日誌,因此我們通過不斷地猜測日誌的周期,根據上一次日誌所記錄的“遊標”,以時序的方式記住它們,便可大幅減少 CPU 的消耗,從而實現低功耗的 Agent。
上圖中 MQL 和 Self-Ops 也是兩個重要的方面,我們來繼續深入討論:
由於各種服務的功能眾多,需要監控的數據量巨大,而且數據種類與格式也都比較復雜,因此大家異曲同工地采用了各種 API 的調用方式。
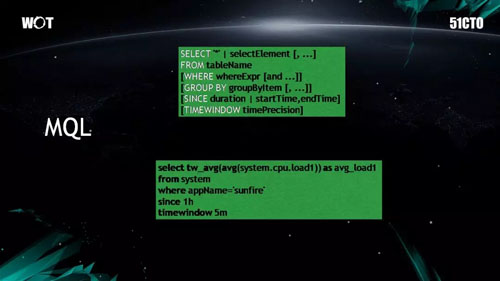
對於阿裏巴巴而言,我們在內部按照標準的 SQL 語法,做了一套監控數據的查詢語言:Monitor Query Language–MQL。它可以統一不同種類的需求,進而實現對所有監控系統的查詢。
從理論上說,無論請求有多復雜,MQL 都可以用一種 SQL 語言來表達。而且語法是由我們自行定義的,如上圖中白色文字所示。
上圖的下方是一個真實的例子,它查詢的是從 1 小時前開始,時間窗口為 5 分鐘間隔的 CPU 數據。
可見它實現起來非常簡單,大家一目了然。熟悉 SQL 的人基本上不學都會寫。
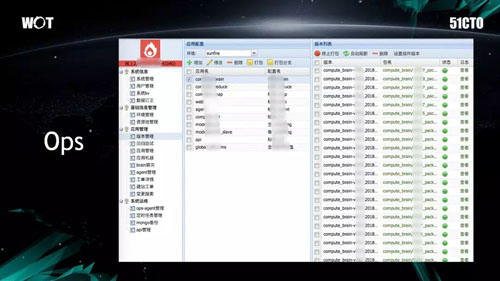
上圖是 Self-Ops 的界面,由於它是我們內部自用的,因此略顯有些粗糙。
對於每天 4000 臺機器的運維工作量,雖然不同的業務系統都有各自不同的監控工具,但是我們覺得有必要將自己的監控做成一個可自運維的系統。
因此,我們從機器的管理角度出發,自行建立了內部的 CMDB,其中包括軟件版本控制、發布打包等功能。
籍此,我們不再依賴於各種中間件等組件,同時也奠定了監控系統的整體穩定性。另外,該系統也給我們帶來了一些額外的好處。
例如:阿裏巴巴可以通過它很容易地“走出去”,接管那些海外收購公司(如 Lazada)的系統。

眾所周知,監控系統一般是在業務系統之後才建立起來的,不同的業務有著不同種類的日誌,而日誌中的相同特征也會有不盡相同的格式表示。
因此,我們在 Agent 上下了不少的功夫,讓自己的系統能夠兼容各種可能性。例如:對於一個日期的表達,不同的系統就有著非常多的可能性。
所以我們在此兼容了七種常用和不常用的日期格式。同時,我們也能兼容不同的日誌目錄的寫法。
可見,大家在準備 Agent 時,不要老想著讓業務方來適應自己,而是要通過適應業務,來體現整套監控系統的核心價值。

如前所述,我們實現了自己的 MQL,而後端卻仍使用的是 HBase。雖然 HBase 非常穩定,但是在面對進一步開發時,就有些“乏力”了。它對於二級緩存的支持十分費勁,更別提各種維度的聚合了。
因此,為了讓 MQL 發揮作用,我們就需要切換到阿裏巴巴內部基於 OpenTSDB 規範所實現的一種 TSDB 數據庫 HiTSDB 之上。
為了適應大規模的監控,我們如今正在努力不斷地去優化 HiTSDB,並預計能在今年的雙十一之前完成。
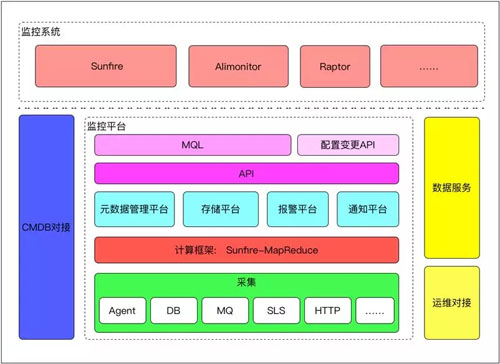
上面就是一個整體的框架圖,我們的監控平臺位於其中上部。當然在阿裏巴巴的內部實際上有著多套不同的監控系統,它們在自己的垂直領域都有其獨特的價值。
鑒於我們的這套系統體量最大,因此我們希望將監控平臺下面的各種技術組件都統一起來。
如圖中紅色的“計算框架”部分所示,它在整個結構中的占比非常大,因此我們將容災、性能監控、以及異步化等全都做到了裏面。
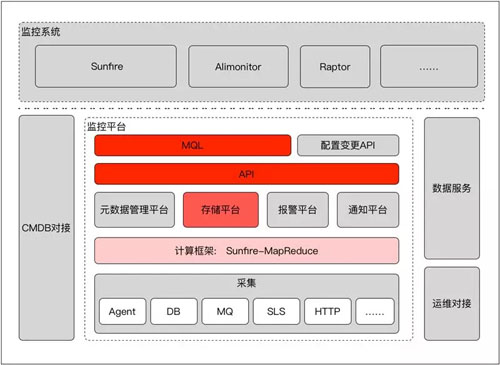
阿裏巴巴如今已經出現了某個單應用涉及到超過一萬臺虛擬機的情況,那麽我們負責收集日誌事件的幾千臺監控機,在收集到該應用的指標之後,又將如何進行 Map,以及直接存入 HBase 中呢?
如今有了 HiTSDB 的解決方案,我們就只要做一次 Map,將日誌數據轉換成為 Key/Value,然後直接扔進 HiTSDB 之中便可,因此也就不再需要 Reduce 層了。總結起來叫做:“把前面做輕,把後面做重”。這也是我們在架構上的一項巨變。
就現在的交易模式而言,每一條交易都會產生一行日誌。我們在一分鐘之內會采集到海量的日誌信息。為了將它們最終轉變成交易數字,大家通常做法是像 Hadoop 的“兩步走”那樣在 Map 層把數字抽取出來,然後在 Reduce 層進行聚合。
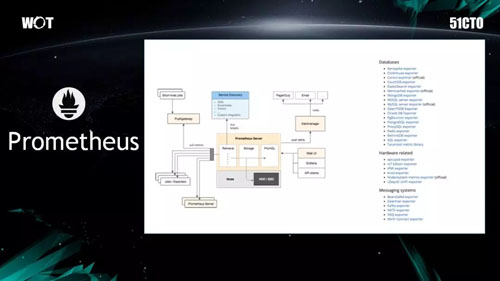
上圖是普羅米修斯的架構圖,它與我們的 Sunfire 大同小異,操作理念都是“拉”的方式。過去那種原封不動地拉取日誌的模式,既消耗帶寬資源,又耗費中心計算的成本。如今根據普羅米修斯的概念則是:統計值,即它只統計單位時間的交易量,因此數據在總量上減少了許多。

對於報警與通知層面,我們通過“切出”的嘗試,實現了如下兩方面的效果:
-
粗剪掉報警和通知裏的誤報。
-
抑制報警和通知的爆發,避免出現報警風暴。
仰望星空
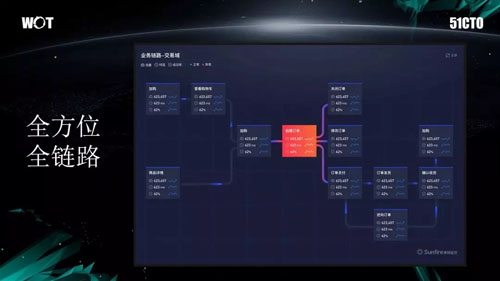
我們希望通過全方位、全鏈路的圖表將各個系統關聯起來。我認為業務的鏈路並非自動化產生的。
如上圖所反映的就是應用與機器之間的關系。但是由於該圖過於復雜、細節化、且沒有分層,因此大多數的應用開發人員都不喜歡使用這張圖。
於是,我們請來業務方人員進行人工繪制,詳略得反映出了他們的關註點。根據他們給出的手繪圖,我們再去做了上面的 Demo 圖。在今年的 618 大促時,我們就是跟據此圖實施的各種系統監控。
雖然我們從事監控工作的,多數出身於原來在運維中做開發、寫腳本的人員,但是大家不要局限於僅解決眼前的各種運維問題,而應當多關心一些業務的方面。
去年阿裏巴巴拆掉了整個運維團隊,並將運維融入了開發之中。通過 DevOps,我們將各個平臺層面、工具層面、自動化、智能等方面都追加了上來。
而在縱向上則包括:網絡質量、應用、線路指標、APM、網絡本身、IDC、以及數據。而這張圖就能起到很好的“串聯”作用。
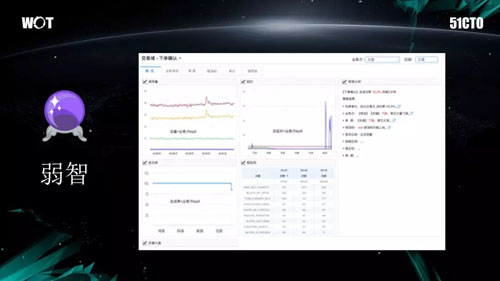
說到 AI,我認為我們還處在“弱智能”的階段,而且是不能直接一步邁到強 AI 狀態的。
有一種說法是:“如今弱智能其實比強智能的需求更多”,可見我們需要有一個過渡的階段。
如果我們將前一頁圖中的那些小方塊的下方點擊開來的話,就會看到出現這張圖(當然真實場景會比該圖更為復雜)。該圖反映了業務指標和系統指標,而右側是做出的智能分析。
在前面“全方位全鏈路”的圖中,曾出現了一張紅色的定單。在傳統模式下,開發人員會在自己的腦子中產生一個排障的流程:從某個指標入手進行檢查,如果它顯示為正常的話,則迅速切換到下一個指標,以此類推下去。
那麽,我們的系統就應該能夠幫助開發人員,將其腦子裏針對某個問題的所有可能性,即上圖中各個相關的指標或框圖,按照我們既定的算法掃描一遍,以檢索出故障點。
此舉雖然簡單,甚至稱不上智能,但著實有效。這也就是我所稱之為的“弱智能”,而且今年我們將會大規模地上線該服務。
可見,此處體現出了“弱智能”比“強智能”更為重要的特點,這也是 AI 在監控領域落地的一個實例。
最後,我希望大家在日常腳踏實地從事開發與運維工作的同時,也能夠擡頭仰望星空。
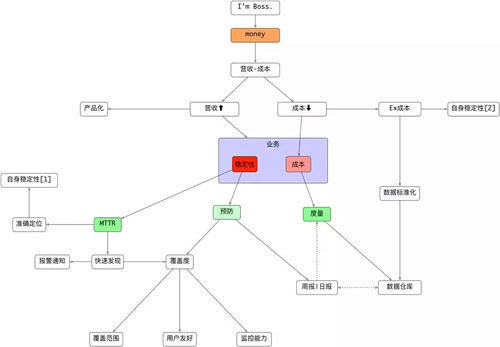
在此,我給大家準備了一張圖,它是從一幅巨大,巨細的總圖中截取出來的。我曾用它向老板匯報 CMDB 的價值所在,且十分有效。
如圖所示,你可以假設自己是一個企業的老板,試著從老板的角度思考對於企業來說,特別是對 IT 而言,如何拉高營收和降低成本。
在一般情況下,監控是不會在阿裏雲上產生直接價值的,這體現的就是營收的維度。而我們要度量的成本還會包括額外成本,即圖中所顯示的“EX成本”。因此,“仰望星空”的“觀測點”可從圖中的三個綠色的點出發,即 MTTR(平均故障恢復時間)、預防和度量。
002_阿裏監控平臺的“打怪升級”之路