
Tesseract-OCR-03-圖片文字識別
阿新 • • 發佈:2018-09-07
目錄名 sso 搜集 命令 發出 維護 結果 rac class
Tesseract-OCR-03-圖片文字識別
本篇介紹使用 Tesseract-OCR 做圖片文字識別,識別手寫文字的時候,正確率能達到 90%,當訓練後正確率是極高的。這裏介紹的圖片文字識別,可以識別英文,數字和中文等
Tesseract-OCR 圖片文字識別
- Tesseract:一款由HP實驗室開發由Google維護的開源OCR,我們可以不斷的訓練的庫,使圖像轉換文本的能力不斷增強;如果團隊深度需要,還可以以它為模板,開發出符合自身需求的OCR引擎
- 如果還沒有安裝 Tesseract-OCR 請參考:
- Windows下 Tesseract-OCR 的安裝與 環境變量配置
https://blog.csdn.net/qq_40147863/article/details/82285920
- Windows下 Tesseract-OCR 的安裝與 環境變量配置
- 當然配置環境也都下載上面那篇文章了,一步一圖很詳細
正題 圖片文字識別
- 我搜集了幾個素材,懶得找可以直接下載:
- https://pan.baidu.com/s/10XxYJa19KIa8-ENdQkhhHg
- 這裏我是將圖片放在了:D:\p
- 我們需要在 cmd 進入此目錄
- 使用 cd 目錄名 進入目錄
- 使用 cd.. 返回上一級目錄
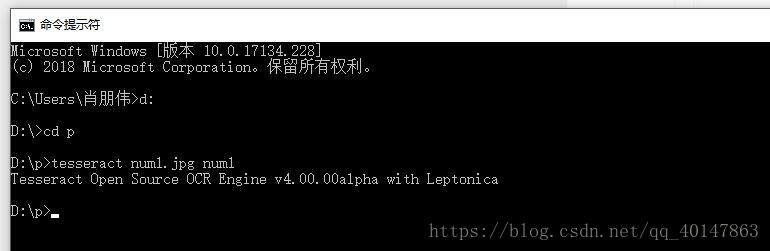
使用 Tesseract 命令:
tesseract 文件名 保存的txt文件名 -l eng 例:tesseract num1.jpg num1
- 這裏 -l eng 是設置語言,不寫的話,默認是 eng 也就是英語
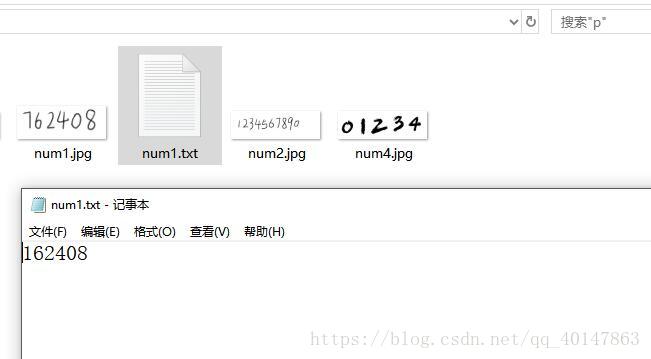
- 結果:
- 註意:
- 1.這裏如果報錯 Tesseract 不是內部或外部命令,就是環境變量沒有配置好參照:https://blog.csdn.net/qq_40147863/article/details/82285920
- 2.如果識別的圖片文字是中文會提示,0個文字
- 1.這裏如果報錯 Tesseract 不是內部或外部命令,就是環境變量沒有配置好參照:
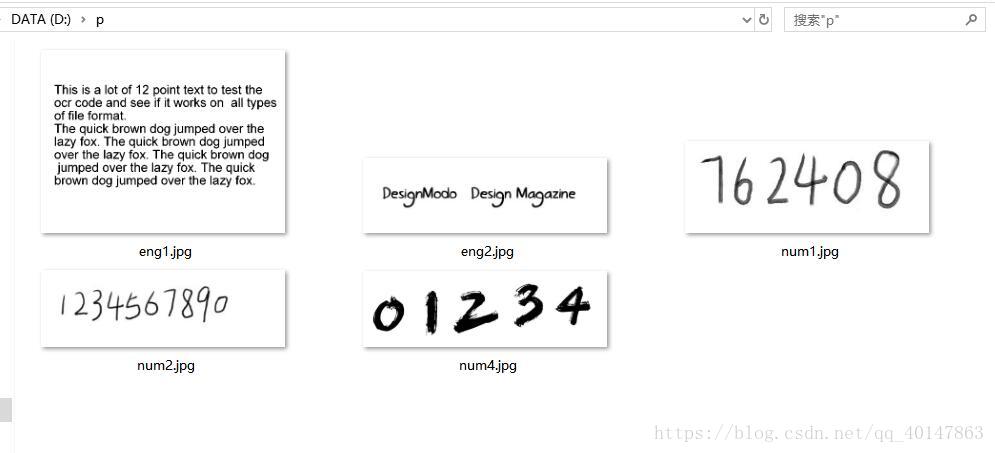
識別手寫英文
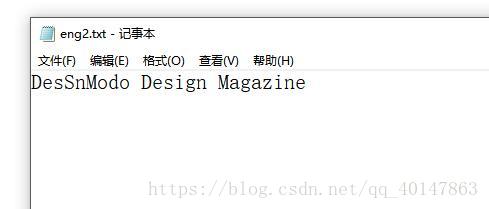
- 識別圖片 eng2.jpg
- 輸入命令:保存為 eng2.txt
- 我們對比一下結果:
- 這裏是識別錯了一個字母,把 ig 錯誤的識別成 S,包括上面那張 數字也是錯了一個
- 那也就是我們要努力的方向了


識別中文
- 這裏識別中文只需要將 -l 參數改成 chi_sim 例如:
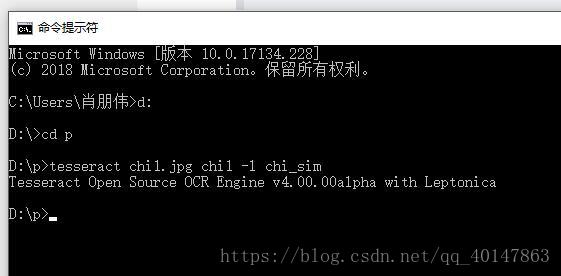
對 有中文文字的圖片 chi1.jpg ,進入圖片路徑,使用一下命令:
tesseract chi1.jpg chi1 -l chi_sim
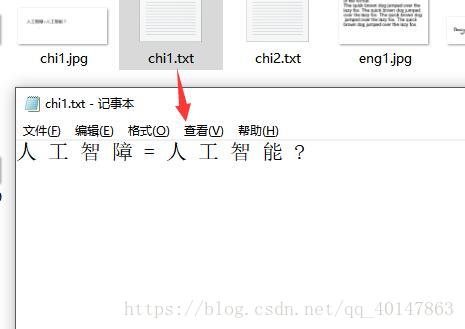
- 圖片樣式:
- 執行命令:
運行結果:

識別英文和數字夾雜驗證碼
- 例如:
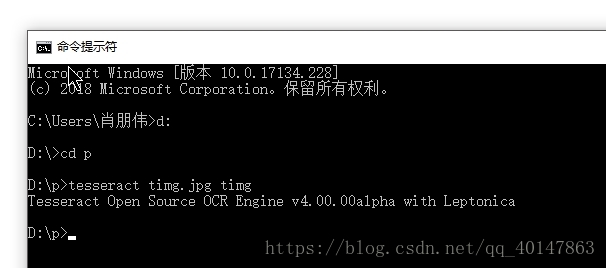
對 圖片 timg.jpg ,進入圖片路徑,使用一下命令:
tesseract timg.jpg timg
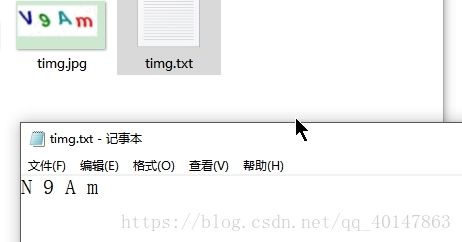
- 圖片樣式:
- 執行命令:
運行結果:

Tesseract 訓練:
- 我們可以通過重復的訓練,用更多的數據去訓練,就可以達到更多高的識別正確率
- 我們使用 jTessBoxEditor 訓練
- 由於 jTessBoxEditor 的安裝和訓練,內容比較多,我再整理一篇
更多文章鏈接:Tesseract 隨筆
- 本筆記不允許任何個人和組織轉載
Tesseract-OCR-03-圖片文字識別