
阿裏雲PyODPS 0.7.18發布,針對聚合函數進行優化同時新增對Python 3.7支持
近日,阿裏雲發布PyODPS 0.7.18,主要是針對聚合函數進行優化同時新增對Python 3.7支持。
PyODPS是MaxCompute的Python版本的SDK,SDK的意思非常廣泛,輔助開發某一類軟件的相關文檔、範例和工具的集合都可以叫做“SDK”。 PyODPS在這裏的作用是提供了對MaxCompute對象的基本操作和DataFrame框架,可以輕松地在MaxCompute上進行數據分析。
PyODPS對於MaxCompute來說有多重要?
首先MaxCompute是一種快速、完全托管的GB/TB/PB級數據倉庫解決方案。MaxCompute可以為用戶提供完善的數據導入方案以及多種經典的分布式計算模型,更快速的解決海量數據計算問題,有效降低企業成本,並保障數據安全。
在MaxCompute上,大家有很多種分析和機器學習的方式。大家可以用在數加的web界面編寫SQL,提交SQL作業;可以用console直接執行SQL,等等等。那機器學習呢,大家需要通過PAI命令提交PAI任務,或者在xlab上操作xlib;畫圖呢?導出數據繪圖或者使用xlab。而這一切工具,都是割裂的,你不得不在各個地方進行切換,而且,也沒有傳統的數據分析和機器學習的快感。
那傳統的任務是怎麽做的呢,使用RStudio或者jupyter notebook,但對於Pythoner,用pandas進行數據分析、繪圖,再用scikit-learn執行機器學習算法,在一個notebook裏,能做所有想做的事情,非常高效。
現在呢,整合這一切的就是PyODPS,包含有基礎MaxCompute SDK,因此一切對MaxCompute模型都可以操作。除此之外,還包括了DataFrame框架,和機器學習模塊,這一切操作都進行了整合。
PyODPS具體實操
安裝
PyODPS支持Python2.6以上(包括Python3),系統安裝pip後,只需運行pip install pyodps,PyODPS的相關依賴便會自動安裝。
首先,用阿裏雲賬號初始化一個MaxCompute的入口,如下所示:

根據上述操作初始化後,便可對表、資源、函數等進行操作。
項目空間
項目空間是MaxCompute的基本組織單元,類似於Database的概念。
您可通過 get_project獲取到某個項目空間,如下所示:
表操作
通過調用 list_tables可以列出項目空間下的所有表,如下所示:
通過調用 exist_table可以判斷表是否存在,通過調用 get_table可以獲取表。
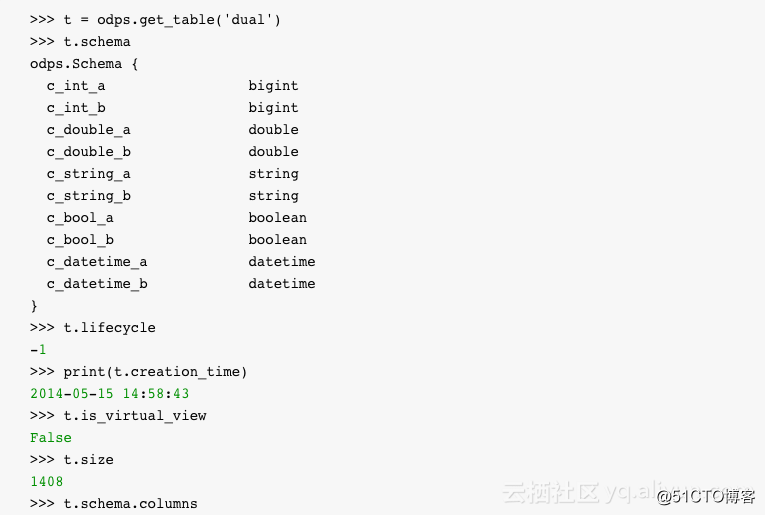
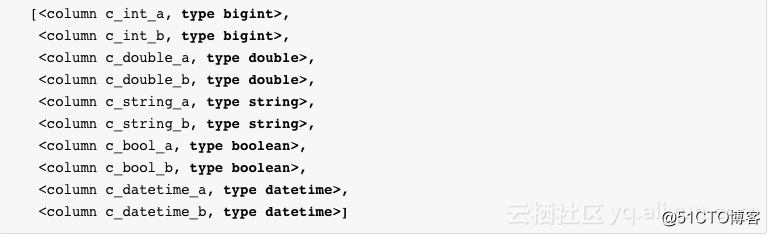
創建表的Schema
初始化的方法有兩種,如下所示:
通過表的列和可選的分區來初始化。
通過調用Schema.from_lists,雖然調用更加方便,但顯然無法直接設置列和分區的註釋。
創建表
您可以使用表的Schema來創建表,操作如下所示:

也可以使用逗號連接的 字段名 字段類型字符串組合來創建表,操作如下所示:
在未經設置的情況下,創建表時,只允許使用bigint、double、decimal、string、datetime、boolean、map和array類型。
如果您的服務位於公共雲,或者支持tinyint、struct等新類型,可以設置 options.sql.use_odps2_extension = True,以打開這些類型的支持,示例如下:
獲取表數據
您可通過以下兩種方法獲取表數據。
通過調用head獲取表數據,但僅限於查看每張表開始的小於1萬條的數據,如下所示:
通過在table上執行open_reader操作,打開一個reader來讀取數據。您可以使用with表達式,也可以不使用。
通過使用Tunnel API讀取表數據,open_reader操作其實也是對Tunnel API的封裝。
寫入數據
類似於 open_reader,table對象同樣可以執行 open_writer來打開writer,並寫數據。如下所示:
同樣,向表中寫入數據也是對Tunnel API的封裝,更多詳情請參見數據上傳下載通道。
刪除表
刪除表的操作,如下所示:

了解更多關於PyODPS 0.7.18詳情請戳:https://help.aliyun.com/document_detail/34615.html?spm=a2c4g.11186623.6.694.175c517cSWoptV
原文鏈接
本文為雲棲社區原創內容,未經允許不得轉載。
阿裏雲PyODPS 0.7.18發布,針對聚合函數進行優化同時新增對Python 3.7支持