
Linux系統-CPU中央處理器調優
本文源鏈接地址:https:www.93bok.com
首先來說說CPU處理數據的方式:
1、批處理:順序處理請求(切換次數少,吞吐量高)
2、分時處理:時間片,把請求分為一個一個的時間片,一片一片的分給CPU處理,我們現在使用的x86就是這種架構(如同“獨占”,吞吐量小)
3、實時處理比如:
批處理--------以前的大型機上所采用的系統,需要把一批程序事先寫好,然後計算得出結果 分時處理------現在流行的PC機和服務器都是采用這種運行模式,就是把CPU的運行分成若幹時間片分別處理不同的運算請求 實時處理------一般用於單片機上,比如電梯的上下控制,對於按鍵等動作要求進行實時處理
中斷
中斷是指在計算機執行期間,系統內發生任何非尋常的或非預期的急需處理事件,使得CPU暫時中斷當前正在執行的程序而轉去執行相應的時間處理程序。待處理完畢後又返回原來被中斷處繼續執行或調度新的進程執行的過程。中斷是一種發生了一個外部的事件時調用相應的處理程序的過程。
硬中斷
外圍硬件發給CPU或者內存的異步信號就是硬中斷信號。簡言之:外設對CPU的中斷, 因此具有隨機性和突發性, , 硬件中斷處理程序要確保它能快速地完成它的任務,這樣程序執行時才不會等侍較長時間, 外部設備(如輸入輸出設備)請求引起的中斷,也稱為外部中斷或I/O中斷。例如(鼠標點擊程序"取消")
軟中斷
由軟件本身發給操作系統內核的中斷信號,稱之為軟中斷。通常是由硬中斷處理程序或進程調度程序對操作系統內核的中斷,也就是我們常說的系統調用(System Call)了。軟中斷發生的時間是由程序控制的
計算機為什麽要采用中斷
為了說明這個問題,舉一例子。假設你有一個朋友來拜訪你,但是由於不知道何時到達,你只能在大門等待,於是什麽事情也幹不了。如果在門口裝一個門鈴,你就不必在門口等待而去幹其它的工作,朋友來了按門鈴通知你,你這時才中斷你的工作去開門,這樣就避免等待和浪費時間。計算機也是一樣,例如打印輸出,CPU傳送數據的速度高,而打印機打印的速度低,如果不采用中斷技術,CPU將經常處於等待狀態,效率極低。而采用了中斷方式,CPU可以進行其它的工作,只在打印機緩沖區中的當前內容打印完畢發出中斷請求之後,才予以響應,暫時中斷當前工作轉去執行向緩沖區傳送數據,傳送完成後又返回執行原來的程序。這樣就大大地提高了計算機系統的效率。
查看內核一秒鐘內中斷多少次CPU
grep HZ /boot/config-3.10.0-327.el7.x86_64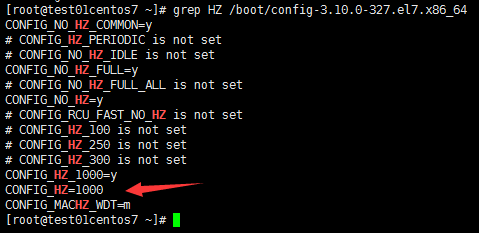
CONFIG_HZ=1000 #1秒鐘有1000次中斷,該參數是編譯內核的時候編譯進去的,改不了的,除非重新編譯一下內核註意:此文件config-3.10.0-327.el7.x86_64是編譯內核的參數文件
調整進程優先級使用更多CPU
可以調整nice值,讓進程使用更多的CPU
nice值的範圍:-20~19 #數值越小優先級越高
nice作用:以什麽優先級運行程序。默認優先級是0
nice語法:nice -n 優先級數值 命令 例如:
nice -n -1 vim a.txt # vim進程以-1級別運行查看
ps -ef | grep vim
top -p 2814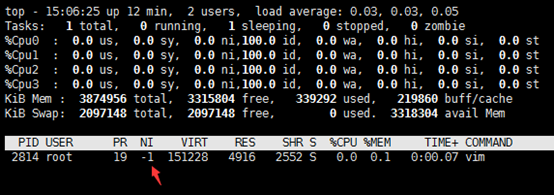
renice #修改正在運行的進程的優先級
renice語法:
renice –n -6 PID例如:

renice -n -6 2520
top -p 2520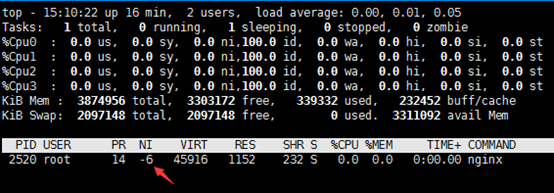
CPU親和力
CPU親合力就是指在Linux系統中能夠將一個或多個進程綁定到一個或多個處理器上運行.
一個進程的CPU親合力掩碼決定了該進程將在哪個或哪幾個CPU上運行.在一個多處理器系統中,設置CPU親合力的掩碼可能會獲得更好的性能.
我們來分析一下:
1、linux的SMP負載均衡是基於進程數的,每個cpu都有一個可執行進程隊列,只有當其中一個cpu的可執行隊列裏進程數比其他cpu隊列進程數多25%時,才會將進程移動到另外空閑cpu上,也就是說cpu0上的進程數應該是比其他cpu上多,但是會在25%以內
2、我們的業務中耗費cpu的分四種類型,(1)網卡中斷(2)1個處理網絡收發包進程(3)耗費cpu的n個worker進程(4)其他不太耗費cpu的進程基於1中的負載均衡是針對進程數,那麽(1)(2)大部分時間會出現在cpu0上,(3)的n個進程會隨著調度,平均到其他多個cpu上,(4)裏的進程也是隨著調度分配到各個cpu上;
當發生網卡中斷的時候,cpu被打斷了,處理網卡中斷,那麽分配到cpu0上的worker進程肯定是運行不了的
其他cpu上不是太耗費cpu的進程獲得cpu時,就算它的時間片很短,它也是要執行的,那麽這個時候,你的worker進程還是被影響到了;按照調度邏輯,一種非常惡劣的情況是:(1)(2)(3)的進程全部分配到cpu0上,其他不太耗費cpu的進程數很多,全部分配到cpu1,cpu2,cpu3上。。那麽網卡中斷發生的時候,你的業務進程就得不到cpu了
如果從業務的角度來說,worker進程運行越多,肯定業務處理越快,人為的將它捆綁到其他負載低的cpu上,肯定能提高worker進程使用cpu的時間
舉個例子說一下,redis是單進程模型,為了充分利用多核服務器的性能,可以指定不同的redis實例運行在不同的CPU上,這樣也可以減少進程上下文切換。
安裝:
[root@test01centos7 ~]# rpm -qf `which taskset`
util-linux-2.23.2-26.el7.x86_64taskset使用方法
taskset作用:在多核情況下,可以指定一個進程在哪顆CPU上執行程序,減少進程在不同CPU之間切換的開銷
1、指定進程運行在哪些/哪個CPU上
ps -aux | grep mysql
taskset -p 4223
f #說明MySQL在4顆CPU上隨機進行切換
taskset -pc 2 4223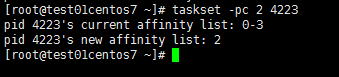
註意:2表示該進程只會運行在第三個CPU上(從0開始計數)
taskset -p 4223
這裏看到了4,有朋友就要說了,你這不對呀,剛剛我明明指定的-pc 2,那從0開始計算,應該是第三顆CPU上運行才對,怎麽會是4呢,說明一下:
8核CPU ID: 7 6 5 4 3 2 1 0
對應的十進制數為:128 64 32 16 8 4 2 1
十六進制: A=10 B=11 C=12 D=13 E=14 F=15從上邊可以看出什麽了麽,我們taskset -p查看時,下邊顯示的4,是十進制數的CPU,4對應的CPU ID為2,從0開始算,那就是第三顆CPU。那之前我們看到的f呢,為什麽代表的是4顆CPU,f=15=1+2+4+8,這樣可以明白f為什麽代表的是4顆CPU了麽
2、進程啟動時指定CPU
taskset -c 3 /a01/apps/nginx/sbin/nginx -c /etc/nginx/nginx.confps -aux | grep nginx
taskset -p 4468
CPU性能的底線是什麽呢
通常,一個被充分利用的CPU,利用率之間的比例應該是:
1、CPU利用率,如果 CPU 有 100% 利用率,那麽應該到達這樣一個平衡:65%-70% User Time,30%-35% System Time,0%-5% Idle Time
2、上下文切換,上下文切換應該和 CPU 利用率聯系起來看,如果能保持上面的 CPU 利用率平衡,大量的上下文切換是可以接受的
3、可運行隊列,每個可運行隊列不應該有超過1-3個線程(每處理器),比如:雙處理器系統的可運行隊列裏不應該超過6個線程。vmstat使用
vmstat 是個查看系統整體性能的小工具,小巧、即使在很 heavy 的情況下也運行良好,並且可以用時間間隔采集得到連續的性能數據。
例一:
vmstat 1
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
4 0 140 2915476 341288 3951700 0 0 0 0 1057 523 19 81 0 0 0
4 0 140 2915724 341296 3951700 0 0 0 0 1048 546 19 81 0 0 0
4 0 140 2915848 341296 3951700 0 0 0 0 1044 514 18 82 0 0 0
4 0 140 2915848 341296 3951700 0 0 0 24 1044 564 20 80 0 0 0
4 0 140 2915848 341296 3951700 0 0 0 0 1060 546 18 82 0 0 0從上面的數據可以看出幾點:
1. interrupts(in)非常高,context switch(cs)比較低,說明這個 CPU 一直在不停的請求資源;
2. user time(us)一直保持在 80% 以上,而且上下文切換較低(cs),說明某個進程可能一直霸占著 CPU;
3. run queue(r)剛好在4個。例二:
procs -----------memory---------- ---swap-- -----io---- --system-- -----cpu------
r b swpd free buff cache si so bi bo in cs us sy id wa st
14 0 140 2904316 341912 3952308 0 0 0 460 1106 9593 36 64 1 0 0
17 0 140 2903492 341912 3951780 0 0 0 0 1037 9614 35 65 1 0 0
20 0 140 2902016 341912 3952000 0 0 0 0 1046 9739 35 64 1 0 0
17 0 140 2903904 341912 3951888 0 0 0 76 1044 9879 37 63 0 0 0
16 0 140 2904580 341912 3952108 0 0 0 0 1055 9808 34 65 1 0 0從上面的數據可以看出幾點:
1. context switch(cs)比 interrupts(in)要高得多,說明內核不得不來回切換進程;
2. 進一步觀察發現 system time(sy)很高而 user time(us)很低,而且加上高頻度的上下文切換(cs),說明正在運行的應用程序調用了大量的系統調用(system call);
3. run queue(r)在14個線程以上,按照這個測試機器的硬件配置(四核),應該保持在12個以內。例三:
r b swpdfree buff cache si so bi bo in cs us sy wa id
2 1 207740 98476 81344 180972 0 0 2496 0 900 2883 4 12 57 27
0 1 207740 96448 83304 180984 0 0 1968 328 810 2559 8 9 83 0
0 1 207740 94404 85348 180984 0 0 2044 0 829 2879 9 6 78 7
0 1 207740 92576 87176 180984 0 0 1828 0 689 2088 3 9 78 10
2 0 207740 91300 88452 180984 0 0 1276 0 565 2182 7 6 83 4
3 1 207740 90124 89628 180984 0 0 1176 0 551 2219 2 7 91 01、上下文切換數目高亍中斷數目,說明當前系統中運行著大量的線程,kernel 中相當數量的時間都開銷在線程的”上下文切換“。
2、大量的上下文切換將導致 CPU 利用率丌均衡.很明顯實際上等待 io 請求的百分比(wa)非常高,以及 user time 百分比非常低(us). 說明磁盤比較慢,磁盤是瓶頸
3、因為 CPU 都阻塞在 IO 請求上,所以運行隊列裏也有相當數量的可運行狀態線程在等待執行.參數介紹:
? r,可運行隊列的線程數,這些線程都是可運行狀態,只不過 CPU 暫時不可用;
? b,被 blocked 的進程數,正在等待 IO 請求;
? in,被處理過的中斷數
? cs,系統上正在做上下文切換的數目
? us,用戶占用 CPU 的百分比
? sy,內核和中斷占用 CPU 的百分比
? wa,所有可運行的線程被 blocked 以後都在等待 IO,這時候 CPU 空閑的百分比
? id,CPU 完全空閑的百分比CPU性能調校總結
首先要確認系統性能問題是由CPU導致的而不是其他子系統。如果處理器為服務器瓶頸,可以通過相應調整來改善性能,這包括:
?使用ps -ef命令確保沒有不必要的程序在後臺運行。如果發現有不必要的程序,將其停止並使用cron將其安排在非高峰期運行。
? 通過使用top命令找出非關鍵性且消耗CPU較多的進程,並使用renice命令修改它們的優先級。
? 在基於SMP的機器中,嘗試使用taskset將進程綁定到指定的CPU,確保進程不需要在處理器間忙碌,從而導致多次cache清空。
? 對於正在運行的應用程序,最好的辦法是縱向升級(提升CPU頻率)而不是橫向升級(增加CPU數量)。這取決於你的應用程序是否能使用到多個處理器。例如一個單線程應用程序的升級方式最好是更換成更快的CPU而不是增加為多個CPU。
? 通常的做法還包括確認你所使用的是最新的驅動程序和韌體,因為這會影響CPU的負載。Linux系統-CPU中央處理器調優