
記一次不太成功的爬取dingtalk上的企業的信息
阿新 • • 發佈:2018-09-24
原來 oda gen 鏈接 master ref apc rate oss 首先打開這個鏈接
所以,我們的思路就很明確了,通過
企業的URL已經獲取到了,然後再訪問企業的URL,看看能否獲取到企業的信息。
沒有。
寫請求頭,請求頭包含兩項,一個是cookie,一個user-agent。加上請求頭再試試看,有了。

發現企業信息在js代碼裏,寫正則表達式
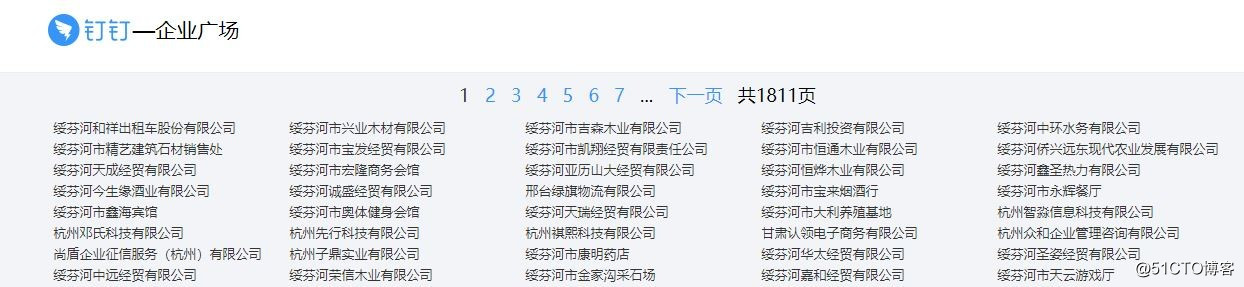
https://www.dingtalk.com/qiye/1.html,可以網頁列出了很多企業,點擊企業,就看到了企業的信息。所以,我們的思路就很明確了,通過
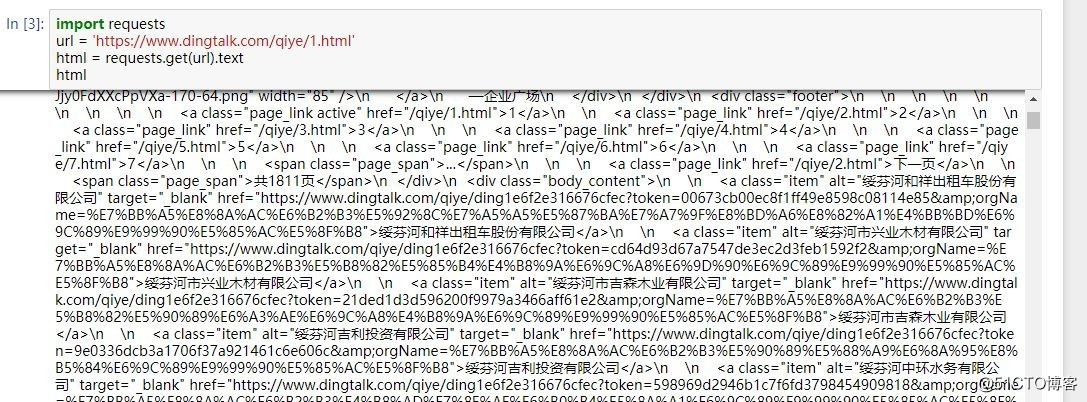
https://www.dingtalk.com/qiye/1.html這個入口鏈接獲取企業的URL,然後通過訪問企業的URL獲取企業的信息。在jupyter notebook中試一下。企業的URL已經獲取到了,然後再訪問企業的URL,看看能否獲取到企業的信息。
沒有。
寫請求頭,請求頭包含兩項,一個是cookie,一個user-agent。加上請求頭再試試看,有了。
發現企業信息在js代碼裏,寫正則表達式
patterns = r‘"businessInfoData":{"enterpriseName":"(.*?)","frName":"(.*?)","enterpriseType":"(.*?)","enterpriseStatus":"(.*?)","regCap":"(.*?)","regCapCur":"(.*?)","esDate":"(.*?)","regOrg":"(.*?)","operateScope":"(.*?)","address":"(.*?)","regNo":"(.*?)","creditCode":"(.*?)","region":"(.*?)"}‘ results = re.findall(patterns, html)
ok,成功匹配出來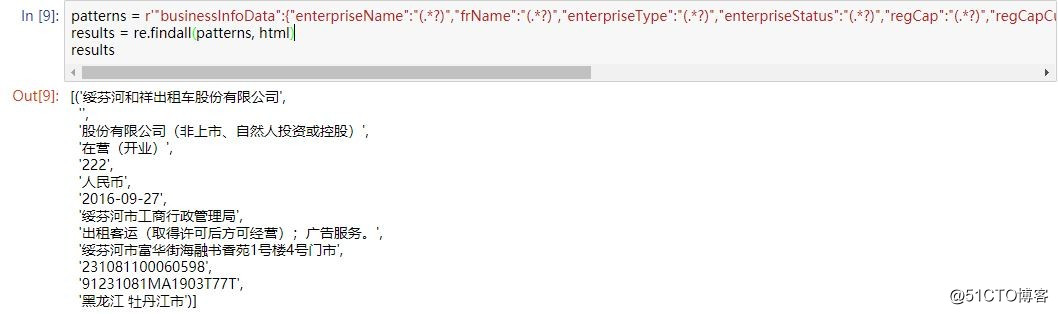
到此,發現很簡單了,立馬就把代碼給寫了出來,但發現一些問題,只有一部分企業的信息爬取了出來,大部分企業信息都獲取失敗了。這是咋回事呢,原來啊,有的企業URL源碼裏有企業信息,而有的沒有。

然後,我查看完整企業信息,發現這個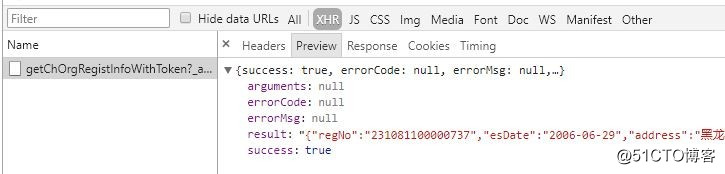
但是,我無法構造這個鏈接,憂傷。
所以,整個爬蟲到此為止。寫代碼的時候,原本想用入口鏈接不斷下一頁獲取所有企業URL,但一想,算了吧,直接簡單粗暴一點。然後呢,爬取的時候,爬取速度好慢。
最後,附上垃圾的源碼github。
記一次不太成功的爬取dingtalk上的企業的信息