
記一次由tcp_tw_recycle參數引發的血案
從昨天開始,在值班群中陸續值班人員反映系統後臺存在卡頓問題,如下圖:
而且在卡頓的同時登陸服務器也會卡好久。此現象只在一臺服務器有出現。
二,故障分析:
1,登陸服務器查看資源使用top,vmstat等命令查看了一番發現服務器各項指標都沒有異常。於是將問題轉向了網絡層。
2,客戶端端值班人員反映只有在訪問系統後臺的時候才會出現卡頓,訪問其他網站正常。
3,本地使用ping服務器外網ip正常返回,無丟包,延遲也正常。
4,使用http-ping工具時,問題出現了,會經常性的出現連接失敗:
(http-ping工具下載地址https://www.softpedia.com/get/Network-Tools/IP-Tools/http-ping.shtml)
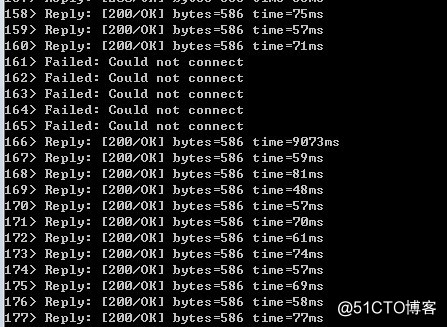
為什麽會連接失敗呢?
5,使用tcpdump抓包在卡頓的時候會抓到大量的syn請求,但服務器沒有響應:
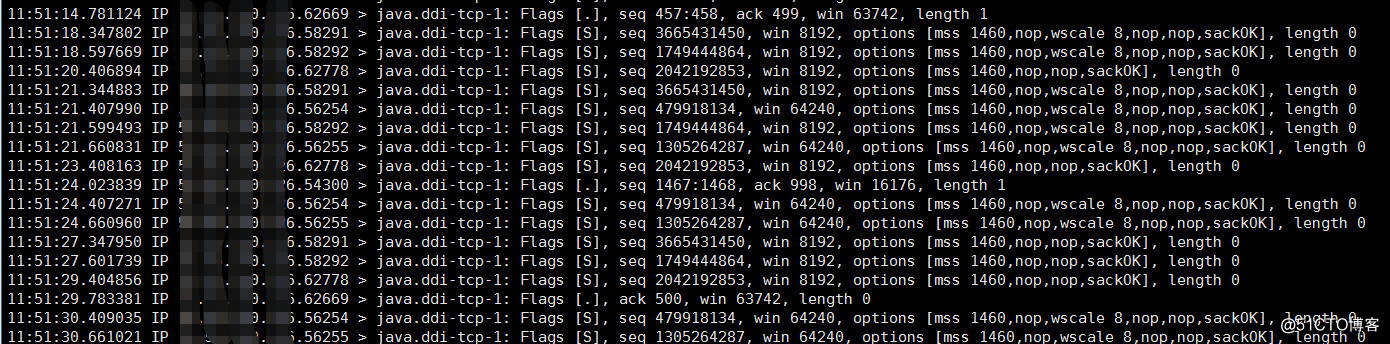
6,登錄服務器查看tcp相關數據
$ netstat -s | grep -i listen
326 times the listen queue of a socket overflowed
751346 SYNs to LISTEN sockets dropped發現在卡頓時有大量tcp syn包被丟棄,數值一直在增長。
三,故障處理:
在查閱資料並結合實際情況後,發現該服務器同時啟用了 tcp_timestamps和tcp_tw_recycle參數。
後想起,之前同事為改善time_wait連接數過多問題曾改過該內核參數。
$ vi /etc/sysctl.conf
#修改為如下
net.ipv4.tcp_tw_recycle = 0
#保存退出,使之生效
$ sysctl -p再觀察,發現服務已正常,卡頓現象消失。
四,總結:
我們先來man一下這兩個參數(man tcp):
tcp_timestamps (Boolean; default: enabled; since Linux 2.2)
Enable RFC 1323 TCP timestamps.tcp_timestamp 是 RFC1323 定義的優化選項,主要用於 TCP 連接中 RTT(Round Trip Time) 的計算,開啟 tcp_timestamp 有利於系統計算更加準確的 RTT,也就有利於 TCP 性能的提升。(默認開啟)
tcp_tw_recycle (Boolean; default: disabled; since Linux 2.4)
Enable fast recycling of TIME_WAIT sockets. Enabling this option is not recommended since this causes problems when working with NAT (Network Address
Translation).開啟tcp_tw_recycle會啟用tcp time_wait的快速回收,這個參數不建議在NAT環境中啟用,它會引起相關問題。
tcp_tw_recycle是依賴tcp_timestamps參數的,在一般網絡環境中,可能不會有問題,但是在NAT環境中,問題就來了。比如我遇到的這個情況,辦公室的外網地址只有一個,所有人訪問後臺都會通過路由器做SNAT將內網地址映射為公網IP,由於啟用了tcp_timestamps,所以客戶端會在頭部中增加時間戳信息,而在服務器看來,同一客戶端的時間戳必然是線性增長的,但是,由於我的客戶端網絡環境是NAT,因此每臺主機的時間戳都是有差異的,在啟用tcp_tw_recycle後,一旦有客戶端斷開連接,服務器可能就會丟棄那些時間戳較小的客戶端的SYN包,這也就導致了網站訪問極不穩定。
經過此次故障,告誡我們在處理線上問題時,不能盲目修改參數,一定要經過測試,確認無誤後,再應用於生產環境。同時,也要加深對相關內核參數的認識和理解。
記一次由tcp_tw_recycle參數引發的血案