
OpenTSDB 生產應用與思考(轉)
轉自:https://yq.aliyun.com/articles/623275
OpenTSDB 官方介紹
http://opentsdb.net/overview.html
這裏就不翻譯了。
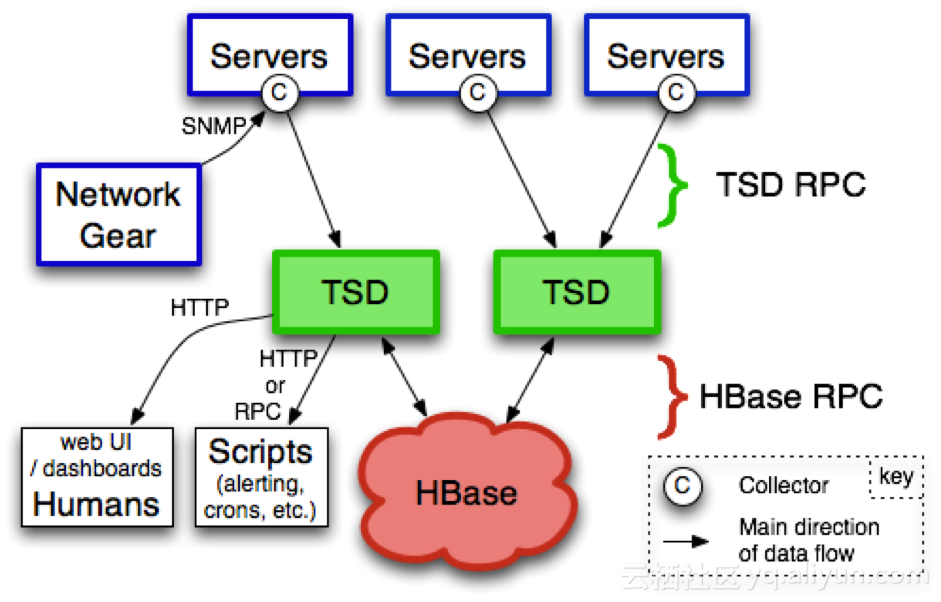
OpenTSDB 應用場景與數據量級
現在的時間序列數據庫不僅僅可以提供原始數據的查詢,而且要支持對原始數據的聚合能力,支持過濾、過濾之後的聚合計算,這些功能OpenTSDB 都有。架構設計也好,中間件也好,還是數據庫,在實際生產場景中,都繞不開數據量級的考慮。OpenTSDB 在數據量小時是可用的,在千萬級、億級中提取幾萬條數據,比如某個指標半年內的5分鐘級別的數據,還是很快響應的。但如果再提取多點數據,幾十萬,百萬這樣的量級,又或者提取後再做個聚合運算,OpenTSDB 就勉為其難啦,原因有幾點:
【1】OpenTSDB 目前還是單點做聚合運算,我所知道的大的雲商如阿裏雲HiTSDB、數據庫在這點做了改造,解決了這個瓶頸。
【2】這樣的量級數據從HBase 中提取到單節點內存中進行聚合運算,在資源消耗方面不可忽視。
【3】一個查詢一旦提取的量級大,OpenTSDB 向HBase 發起RPC 請求(OpenTSDB 一次請求默認128行)次數也必然增加,十幾秒、幾十秒的響應時間,這就限制了它的應用場景。
架構中應用OpenTSDB 需要事先考慮
【1】OpenTSDB 只有4 張HBase 表,其中一張是存放數據。所有的數據都存放在一張表,這就意味應用在OpenTSDB 這個層級上是無法更小的粒度來區別對待不同業務(比如想把WebApp 性能指標放在一張表上,OS 性能指標放在一張表上),很難根據業務類別自身特點進行差異化對待後續的運維(比如不同類別設置不同的TTL,數據刪除,遷移操作等等)。除非再部署多套OpenTSDB 來對待,這是另外一個話題。
【2】OpenTSDB 不支持二級索引,只有一個基於HBase的RowKey。結合業務場景的查詢維度,設計好RowKey 是應用好OpenTSDB 的關鍵!提前評估好metric + tag 背後掃描的數據量。比如將high-cardinality tag 調整到metric 中,減少掃描的數據量。
【3】OpenTSDB 能實時聚合計算功能,但基於單點運算能力有限,建議這種聚合在入庫階段完成的。比如將1 分鐘粒度聚合、5分鐘粒度聚合提前通過KafkaStream,Spark 等運算,將聚會結果存入OpenTSDB 供查詢。
【4】Tcollector采集數據上報給OpenTSDB,建議在中間加一層Kafka 。一來解偶兩者之間的強依賴性,同時保存一段時間采集數據,在OpenTSDB、HBase 不可用(計劃性運維、集群故障)時不至於丟失數據,對運維來說也增強了操作上的靈活性。二來可以對采集的原始數據進行二次加工再入OpenTSDB,如粒度聚合運算。
【5】關於salt 啟用
時間序列數據的寫入,寫熱點是一個不可規避的問題,當某一個metric 下數據點很多時,則該metric 很容易造成寫入熱點。從2.2 開始,OpenTSDB 采取了允許將metric 預分桶,預分桶後的變化就是在rowkey 前會拼上一個桶編號(bucket index)。預分桶後,可將某個熱點metric 的寫壓力分散到多個桶中,避免了寫熱點的產生。而客戶端查詢OpenTSDB 一條數據,OpenTSDB 將這個請求拆成分桶數個查詢到HBase,然後返回桶數個結果集到OpenTSDB 層做合並。對HBase 並發請求相應的也會桶數倍的擴大。
設計時需要結合查詢場景,在查詢性能和後期熱點運維方面,做一個權衡考慮。比如說有個場景,在前端頁面上要查詢一個業務相關的性能指標(以業務為查詢單元),查詢的結果以多個圖形方式展現出來,要求響應時間快。如果這是一個用戶點擊查詢比較頻繁的場景(並發量大),啟動了salt,無形加大OpenTSDB和HBase的壓力。如果完全關閉salt 的話,寫熱點問題就加大HBase 的運維難度,極端的話造成整個集群整體性能下降。如果寫入吞吐量大的話,建議開啟salt,但桶的個數不易太多,2-4個即可,默認是20 個桶。
比如查詢一個業務AAA的數據庫性能指標,如下圖:
【6】OpenTSDB 提供三種途徑寫數據,分別是Telnet API, HTTP API, 批量導入。Telnet 讀寫是異步操作,但是返回的響應混亂的。HTTP API 是同步讀寫操作,成功與否能及時反饋,同時多個數據點能在單個端口發送,節省帶寬。理論上Telnet 速度好於HTTP,但犧牲了數據是否成功寫入的可靠性。在實際生產使用中,建議使用HTTP API,而Telnet API 用於運維。
【7】關於Cache
OpenTSDB 並沒有內建的Cache 來存放數據,截止到2.3 還是只能依賴HBase 的Cache。
OpenTSDB 部署與運維方面
【1】OpenTSDB 是Java 實現的,JVM 方面的參數設置、GC、運維管理同樣是OpenTSDB 需要考慮的。
【2】生產部署時,往往是多臺機器部署,每臺機器部署多個實例,讀寫分離。比如查詢實例端口一律使用4242,寫數據實例端口一律使用4243,然後讀寫請求通過nginx + Consul 均衡到各個實例端口上。
【3】設置tsd.storage.hbase.prefetch_meta = true(默認是false),否則極端情況下會打爆hbase:meta 表請求。
【4】2.2 版本開始,tsd 寫數據到HBase有兩種方式,一種是每來一條數據append 到hbase。另一種是先緩存大量數據到TSD 的內存裏,然後進行compaction,一次性寫入。官方推薦Append 方式。相關參數tsd.storage.enable_appends = true 。
【5】TSDB 在每小時整點的時候將上個小時的數據讀出來(get),然後compact 成一個row,寫入(put)到HBase,然後刪除(delete)原始數據,目的是減少存儲消耗,增大了HBase 壓力,性能平穩上出現一定的波動。
【6】若metric, tag含有中文,編譯時指定字符集為UTF8。
【7】其他一些註意的參數:
tsd.storage.hbase.scanner.maxNumRow
tsd.query.timeout
OpenTSDB 生產應用與思考(轉)