
PaddlePaddle應用於百度視覺技術的工程實踐
深度學習的出現,某種程度上改變了我們對計算機視覺的定義。而PaddlePaddle是百度開源的深度學習框架,它是如何支持百度視覺技術,有哪些工程實踐,這篇文章將由百度視覺技術部主任研發架構師劉國翌為大家解答。
以下為劉國翌老師演講實錄
百度AI視覺能力
百度內部大規模應用計算機視覺的技術分為四個方面,第一是圖像識別,包含圖像分類、文字識別、人臉識別等。第二是圖像檢索,包含圖文、相同圖片、相似圖片和商品圖片檢索。第三是視頻理解,主要涉及視頻分類、目標追蹤、人體姿態跟蹤,應用在商業、監控、安全、新零售等領域,。第四是機器人視覺,包括嵌入式視覺、SLAM、深度傳感器。這是百度計算機視覺整體的劃分,除機器人視覺大量應用深度學習技術,其余三個技術是從傳統的機器視覺的方法逐漸過渡到現在最流行的深度學習的過程,是逐步替代的。
其中,圖像識別是百度應用最廣泛也是最重要的技術,包括無人車、推薦、圖像配圖等等。它的基礎能力包含通用分類、文字識別、圖像檢索、細粒度識別、圖像審核、視頻內容分析六大能力。

圖一:百度識圖基礎能力
? 通用分類:在實際應用中,我們需要處理上萬類的通用分類以及各種各樣的目標檢測,因此百度內部建設自己的分類體系。
? 文字識別:和人臉識別一樣,是圖像識別的最主要的指令,是編碼和解碼的過程,方向是目標類檢測。
? 圖像檢索:用以覆蓋廣泛的需求,可以搜到互聯網所有包含這張圖片的網頁,以及跟這張圖片關聯的商品,包括垂類的識別,比如商品、景點、紅酒、外幣等等,這些無法通過一個簡單分類來解決。因此需要通過圖像特征學習,從而實現從圖片到信息的關聯。基於此,圖像檢索技術最關鍵的是圖像深度學習,基於通用分類,提取分到某個中間層,定義圖像不良的相應損失函數,使得相同的或者相類似的問題能得到統一的表達。另外重要的垂類,比如動植物、商標、車型等等,這種采用專用的分類技術或者分類數據,並建設一個分類的數據閉環來持續進行叠代。模型叠代需要解決三個問題,第一個問題是如何在眾多的模型結構裏選擇最適合、最先進、最好的結構。第二個問題是上百個模型如何進行評價,這時我們需要系統的方法。換句話說,第二個問題就是如何快速經濟的復現模型,希望有流程使其自動化和標準化。第三個問題:如何沈澱模型研發中大量的算法經驗。因此視覺研發的實現目標是使得機器學習擁有流程化,標準化,持續快速叠代的能力。
基於PaddlePaddle,如何實現視覺模型研發
現在市場上有各種各樣的不同的框架,不同框架的使用會帶來模型研發、訓練不同實現的問題。因此,百度內部趨向於使用同一種框架和流程,把所有的算法研發經驗,包括數據處理流程都往一個方向去努力。
其中,PaddlePaddle是提供基礎的平臺或架構,它為我們提供了符合論文實現標準的算子的實現。同時,PaddlePaddle復現使用單卡進行訓練,來保證單機單卡以及多機多卡效率互有分工。因此,基於PaddlePaddle,實現了訓練的標準化和自動化以及最底層的訓練框架。
PaddlePaddle訓練平臺中的Paddle Cloud是公司級的平臺,它的數據讀取可以實現從數據倉庫和HDFS、AFS直讀,大家通過這個平臺去共享復現方案以及降低模型復現和訓練的門檻。
目前,PaddlePaddle中已發布的視覺模型有:
?圖像分類:image_classification
?人臉檢測:face_detection
?OCR識別:ocr_recognition
?目標檢測:object_detection
?圖像分割:ICNet
?模型轉換:image_classification/caffe2fluid
同時,還在開發中的模型如下:
?圖像特征學習
?OCR 檢測
?定點化訓練
?視頻分類
?GAN
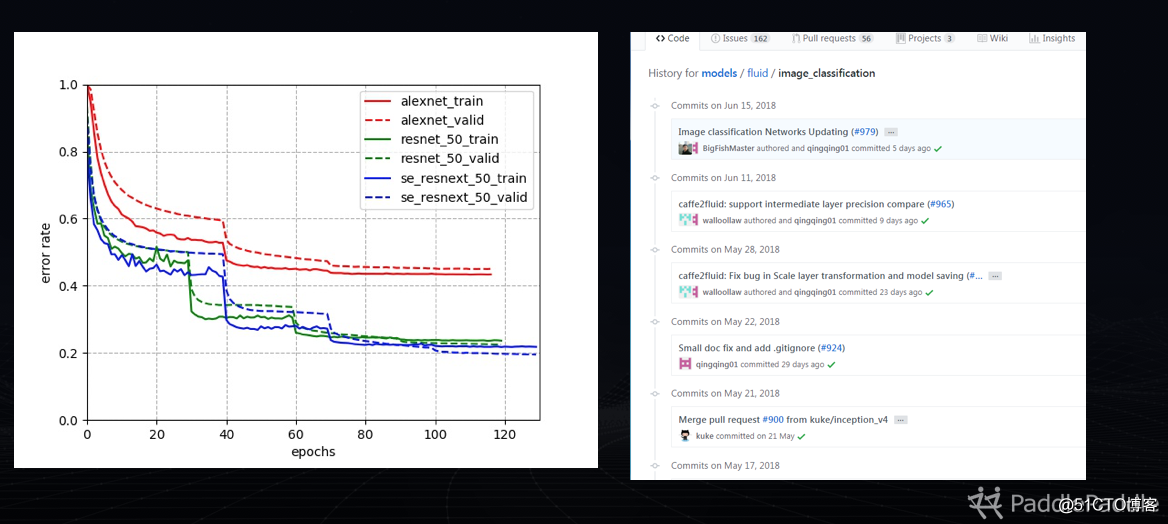
圖二:圖像分類模型的論文結果復現
這是我們在圖像分類模型復現的結果,我們在研發過程中使用的一些數據集,通過提高社區提交代碼文檔和質量的要求,所有代碼進行持續的集成測試,保證隨著版本的叠代,使得穩定性和正確性能保持。
PaddlePaddle涉及大量的基礎算法和優化算法,裏面任何一部分的修改都有可能造成潛在的錯誤,為保證這些修改能持續得到驗證,一方面在公司內部持續使用,另一方面我們會有專門的QA團隊來保證持續叠代的功能,當然,我們也會有專門的團隊來負責PaddlePaddle訓練模型之後的預測優化。所有這些通過分工協作,視覺模型研發及相應預測的優化,更多是接近真正的使用場景。除復現大量經典的模型,我們自己也做一些自研的模型研發,如人臉檢測,大規模分類以及視覺識別方面,在公開數據做到世界領先水平。未來會逐步把這些模型開放出來,跟大家一起去改進和升級這些算法。
工程示例:OCR PaddlePaddle v1 遷移到PaddlePaddle Fluid
OCR長期適用比較老的版本進行模型識別訓練,期望使用最新PaddlePaddle Fluid進行研發,並統一到Paddle Cloud集群訓練,應用最新的模型預測優化。因此成立PaddlePaddle vision聯合項目組,模型研發和對齊並進行訓練遷移和預測遷移。
模型遷移主要有四個步驟:
?完成C++端OP開發。
?完成模型網絡配置,驗證前向網絡
?與舊版本Paddle對齊模型訓練指標。
?對比多種優化方法和學習率動態調整策略。
最終試驗的效果是識別率可以跟以前的版本打平,經過優化,可以有提升的空間。
模型訓練主要有兩個方面的提高:第一實現Fluid框架訓練OCR英文識別模型。與舊版本PaddlePaddle訓練出的模型相比精度相對提升1%;第二在Paddle Cloud上實現afs數據分發,實現Paddle Cloud進行單機單卡,單機多卡訓練OCR識別模型。
以上這些工作和PaddlePaddle技術團隊一起完成,不僅實現了PaddlePaddle的升級,也實現了自己整個訓練方式的升級。
整體實現叠代之後影響面大概是1500萬文本圖像的識別,流量得到了升級。概括來說,我們是基於PaddlePaddle開發了一個流程:首先是基線算法采用公開數據集,實現公開的算法並在社區上提交代碼和文檔,以保證基線模型的正確性,以及跟其他分發的圖像對比。第二是代碼經過反復review,提高了代碼和文檔的質量,也通過社區的反饋,實現了技術的積累以及相應的問題解決。第三基於PaddlePaddle框架,實現了統一的集群訓練方式,實現了標準化、自動化去做機器學習,且一些高級的訓練特性,可以快速集成到框架中去。第四預測框架通過專業專門的團隊,進行優化,可以達到世界領先水平。同時,獨立的訓練QA測試,保證訓練結果隨版本叠代是可復現的。
實錄結束
劉國翌,百度視覺技術部主任研發架構師,百度AI技術部識圖技術負責人,負責研發基於圖像檢索、大規模圖像分類和垂類識別技術的識圖系統,滿足手機拍照場景下的以圖搜圖、以圖搜信息的用戶需求,組織研發並建設了百度視覺技術開放平臺,開放百度的各項視覺能力。
PaddlePaddle應用於百度視覺技術的工程實踐