
探索性數據分析EDA綜述
目錄
1. 數據探索的步驟和準備
2. 缺失值處理
- 為什麽需要處理缺失值
- Why data has missing values?
-
缺失值處理的技術
3. 異常值檢測和處理
- What is an outlier?
- What are the types of outliers?
- What are the causes of outliers?
- What is the impact of outliers on dataset?
- How to detect outlier?
-
How to remove outlier?
4. 特征工程的藝術
- 特征工程是什麽
- 特征工程的過程
- 變量變換是什麽
- 怎麽使用変量変換
- 變量變換的通用方法
-
What is feature variable creation and its benefits?
1. 數據探索的步驟和準備
Garbage in, Garbage out
數據理解、處理涉及的步驟:
- 變量表示(Variable Identification)
- 單變量分析(Univariate Analysis)
- 多變量分析(Bi-variate Analysis)
- 缺失值處理(Missing values treatment)
- 異常值處理(Outlier treatment)
- 變量變換(Variable transformation)
- Variable creation
最後,為了得到更好的模型,需要數次叠代步驟4-7
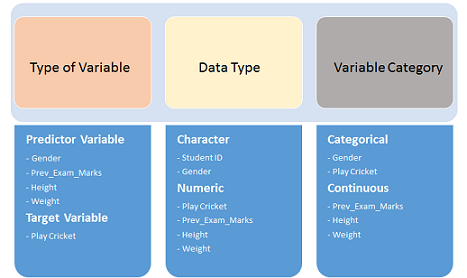
變量表示 Variable Identification
標識特征(Predictor, Input)和目標值(Target, output)
標識數據類型(type)和類別(category)
變量可以被定義為不同的分類:
單變量分析
在這個階段,先一個個的分析變量。具體的分析方法由變量是離散的(categorical)或是連續的(continuous)決定。
連續變量:對於連續變量,需要了解它的集中趨勢(central tendency)和散布情況(spread)。可以使用如下的統計指標和可視化方法:

離散變量:對於離散變量,通常需要了解其值的頻數或頻率 —— Count & Count%。可以使用Bar chart 對其可視化。
多變量分析 Bi-variate Analysis
在預先定義的顯著性水平上,尋找變量間的關系。變量對可以是離散的vs.離散的、連續的vs.連續的、離散的vs.連續的,具體分析方法由變量類型決定
Continuous & Continuous
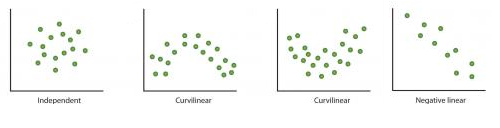
分析連續變量之間的關系,我們可以直接觀察變量間的散點圖。對於尋找連續變量關系,這是一個簡潔的方法,因為散點圖展示的模式可以表示變量間的關系,而這種關系可以使線性或非線性的:
散點圖能夠看出變量間的關系,但是無法看到具體的相關性強度。為此,引出了相關性度量(Correlation):
- -1: 完全線性負相關
- +1: 完全線性正相關
- 0: 不相關
相關性可以由下式計算:
Correlation = Covariance(X,Y) / SQRT( Var(X)* Var(Y))
Categorical & Categorical
- 雙向表: 行和列分表表示兩個變量,數值表示頻數或頻率
- 堆疊柱狀圖(Stacked Column Chart): 這種方法更多的是雙向表的一種可視化形式

- 卡方檢驗(Chi-Square Test)
卡方檢驗通常用來獲得變量間關系的統計顯著性,它檢驗樣本中表現的特性是否足以反映整體中特性。卡方檢驗基於雙向表中變量的一個或幾個類別的預測頻率和實際頻率之間的差異,它返回指定自由度下的卡方分布的概率
概率1:表示兩個變量是相關的(dependent)
概率0:表示兩個變量是不相關的(independent)
(待續...)
Categorical & Continuous
可以通過box plot來可視化分析離散vs連續的數據。
但如果離散變量的取值太小,則不會具有_統計顯著性_。為了計算統計顯著性,可以使用Z-test, T-test或者ANOVA。
-
Z-test / T-test : 評估兩組變量的均值之間的差異是否具有統計意義
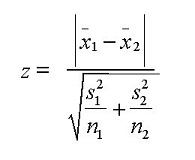
如果Z的概率小於兩個均值則更有意義。T檢驗和Z檢驗很相似,但它用在兩個類別之間的樣本小於30的情況

-
ANOVA : 評估兩組變量的均值之間的差異是否具有統計意義
2. 缺失值處理
為什麽要處理缺失值
訓練數據中的缺失值會降低模型的泛化能力,或者得到一個有偏差的(biased)模型,這是因為我們沒有能夠準確地分析變量之間的關系。這會導致預測或分類錯誤。
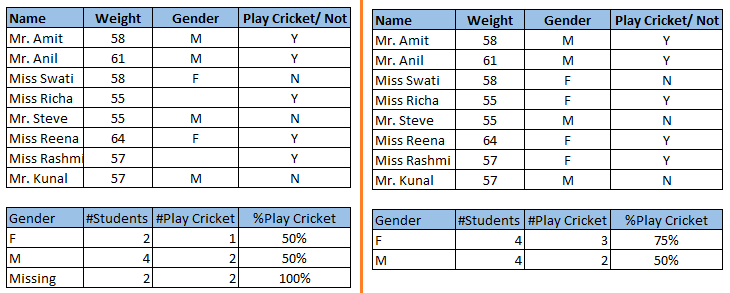
上圖左右兩邊顯示了未處理缺失值和處理缺失值的兩種情況,他們會得到完全不一樣的結論。
為什麽數據集中出現了缺失值
在數據分析的兩個階段會產生缺失值:
- 數據抽取: 數據抽取過程中的錯誤容易產生缺失值。但這類產生缺失值錯誤很容易被發現並被正確的處理過程代替。
- 數據采集: 數據采集階段產生的錯誤很難被修正,可以將其概括為以下四類:
- 完全隨機的missing
當樣本缺失的概率和所有觀測值一樣時。比如在調研過程中,受訪者隨機的回答問題 - 隨機缺失
有時候變量缺失值產生是隨機的,並且缺失頻率在不同的值之間又是不一樣的。例如有些情況,在女性樣本中年齡和性別的缺失值會比男性的多 - 缺失值依賴於某些未觀察到的變量
在這種情況下缺失值的產生不是隨機的,而是依賴於某些我們未能觀察到的(輸入)變量。例如:“身體不適”會是某些特別的診斷的原因,但除非我們能把“身體不適”加入輸入變量當中,否則就有可能產生“隨機”的缺失。 - 缺失值依賴於缺失值本身
例如:那些收入很高或者非常低的人通常不會提供自己的收入信息
- 完全隨機的missing
缺失值的處理方法
- 刪除(Deletion)
- 刪除有缺失值的樣本
- 刪除缺失值本身,然後用樣本剩余數據進行訓練,這樣不同的變量可能會有不同的樣本大小
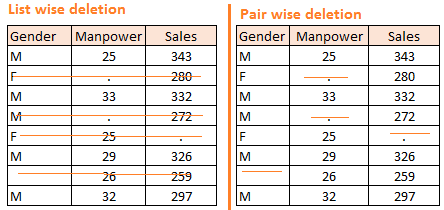
當數據缺失是隨機產生時,可以考慮使用刪除的方法。
- 均值/眾數/中位數填充
使用均值/眾數/中位數填充缺失值的方法。其目標是使用能夠從數據集中的有效值中識別出的關系來評估缺失值。
- 整體填充:利用統一的指標(均值/中位數等)填充缺失值
- 相似填充:對於其他維度相似的樣本,采用相同的值進行填充。如:對於不同性別采用不同的統計量進行缺失值填充
- 使用預測模型
利用預測模型對缺失值進行估計的方法。
將不含缺失值的數據集作為訓練集,含有缺失值的樣本作為測試集,而含有缺失值的變量則是目標變量。可以使用回歸,ANOVA,logistic回歸等方法進行預測。但這種方法有兩個缺點:- 模型估計值通常會比實際值更加整齊(well-behaved)
- 如果變量間並沒有關系,那麽模型的預測值可能是不準確的
- KNN填充
利用和包含缺失值的樣本最為相似的樣本的屬性值填充缺失值。相似度由距離度量。- 優點
- KNN能夠預測定性和定量的屬性
- 不需要構建預測模型
- 有多個缺失值的屬性也很容易處理
- 數據集中屬性間的相關關系也被考慮其中
- 缺點
- KNN算法在處理大數據集時需要很多時間,它遍歷整個數據集以尋找和目標最接近的樣本
- k值的選擇對最終的結果影響很大
- 優點
3. 異常值檢測和處理方法
異常值
那些遠離整體模式的樣本
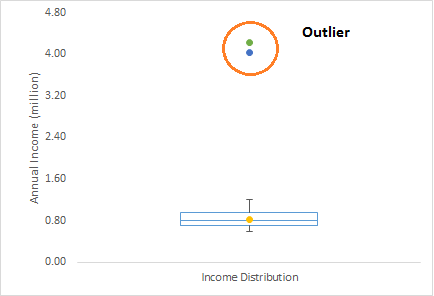
異常值類型
- 單變量異常值:通過觀察單變量的分布情況就能看到
- 多變量異常值:n維空間中的異常值
一個多變量異常值的例子:
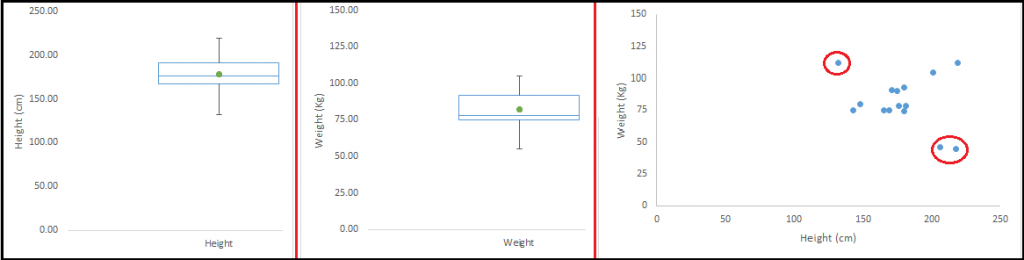
異常的原因
不管在什麽情形下碰到異常值,理想的處理方法都是找到產生異常值的原因,異常值的處理方法也依賴於異常值產生的原因。異常值產生的原因通常有兩大類:
- 人為的錯誤 / Non-Natural
- Natural
異常值產生的具體原因:
- 數據錄入錯誤:數據采集過程中的人為誤差
- 測量錯誤:測量工具的錯誤產生了異常值。例如:有10個秤,其中有一個是壞的……
- 實驗誤差
- 有意的異常:這經常出現在那些調研工具中。例如:青少年通常不會填寫自己實際的飲酒量,而那些如實填寫的則有可能成了異常值……
- 數據處理誤差
- 采樣誤差
- Natural Outlier:這些離群點是真實的而不是由其他錯誤產生的
異常值的影響
異常值會顯著地改變數據分析和統計建模的結果
- 增加了錯誤的誤差,降低了統計檢驗的效果(power of statistical tests)
- 如果異常值不是隨機分布的,會降低Normality
- 異常值會對數據集本身的性質產生影響
- 異常值會影響回歸分析,ANOVA以及其他統計模型的基本假設
異常值影響統計結果的例子:
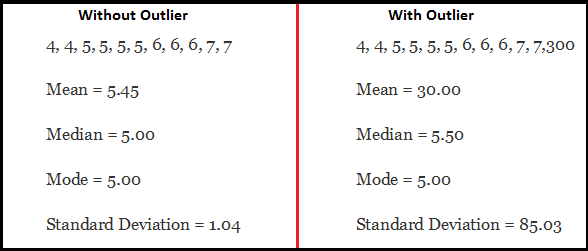
異常值檢測
異常值檢測的通用方法是數據可視化:Box-plot, Histogram, Scatter Plot
其他的常用規則:
- 超過 -1.5 x IQR ~ 1.5 x IQR 的任意值
- 覆蓋方法:任何超過 小於5% 或 大於95%百分位的值都認為是異常值
- 距離均值3倍標註差的數據點
- 異常值檢測是有影響力的數據點的特殊測試情況,其依賴於具體的商業問題理解
- 多變量離群點通常使用影響力、權重或者距離等指標來標識,常用的指數是Mahalanobis’ distance 以及 Cook’s D
異常值處理
大部分異常值的處理方法和缺失值類似,將異常值刪除、轉換、二值化,將其當做一個單獨的分組,填充值或者其他的統計處理方法。
刪除異常樣本
在異常原因是數據錄入錯誤、數據處理錯誤或者異常樣本很少的情況下,考慮刪除異常值
變量變換和二值化
對數化能夠降低數據的方差
二值化可以使得決策樹能夠更好地處理異常值
可以為不同的樣本賦予不同的權重
填充
單獨處理
如果異常值足夠多,應該在統計建模時將其當做一個單獨的分組。一種方法是將不同分組分開處理,分別建模,然後將結果合並起來
4. 特征工程的藝術
特征工程
特征工程是從已有數據中提取更多信息的技術(science and art)。數據並沒有增加,而是使得已有的數據更加有用了。
例如從數據集的日期信息中,可以得到對應的星期信息和月份信息,這些有可能使得模型更有效。
特征工程的過程
在特征工程之前,需要完成5個探索性數據分析的步驟:
- 變量標識
- 單變量分析
- 多變量分析
- 缺失值處理
- 異常值處理
特征工程可以分為兩步:
- 変量変換
- 特征提取
這兩個步驟在探索數據分析中都很重要,且對預測結果有顯著地影響
變量變換
變量變換可以理解為改變一個變量自身的分布,或者其與其他變量之間的關系
例如:用x??√或者log
代替x
什麽時候需要変量変換
- 當我們需要改變一個變量的取值範圍 (change the scale) 或是對其進行標準化 (standardize) 以期能更好的理解變量的時候
- 當我們能將復雜的非線性關系轉換成線性關系的時候 (transform complex non-linear relationships into linear relationships)。相比於非線性的或是曲線的關系,線性關系更好理解
- 對稱的分布比傾斜的分布更好 (Symmetric distribution is preferred over skewed distribution),因為它的解釋性更好,並且更容易形成推論。一些建模技術需要變量是正態分布的,所以當處理一個傾斜的分布時,考慮使用變量變換降低其傾斜度。
對於右傾斜 (right skewed),可以使用開平方/立方、取對數的方法
對於左傾斜 (left skewed),可以使用取平方/立方或是指數的方法 - 変量変換也要從具體實現的角度考慮 (implementation point of view)。例如按照實際情況,將年齡分為3個更有意義的分組等離散化 (Bining of Variables) 的方法。
常用的変量変換的方法
-
取對數
log常用來處理右傾斜的問題,但不能作用於負數或0 - 開平方/立方
-
離散化
離散化用來分類變量,可以作用於原始數據、百分數或是頻率,分類決策通常取決於具體的問題。也可以基於多個變量產生離散化的結果
特征提取及其意義
特征提取是一個基於已有特征創建新的變量/特征的過程。例如,基於時間變量可以創建其他對應的時間表示:

常用的特征提取的方法包括:
- 創建衍生的變量
- 創建指示變量 (dummy variables)
- 更多的方法: 5 Simple manipulations to extract maximum information out of your data
參考資料
- A Comprehensive Guide to Data Exploration
- 5 Simple manipulations to extract maximum information out of your data
- Dummy variable (statistics)
探索性數據分析EDA綜述