
03-數據庫必會問題
1、msyql引擎,區別,適用場景
存儲引擎:如何存儲data,為存儲的data建立索引,如何更新、查詢data等技術的實現方法
數據庫的表有不同的類型,對應mysql不同的存取機制,表類型又稱存儲引擎
- InnoDB存儲引擎
- 支持事務,支持外鍵,
- 行鎖設計,默認讀取操作不會產生鎖
- 查表總行數時,需要全表掃描
- 如果你的數據執行大量的INSERT或UPDATE,出於性能方面的考慮,應該使用InnoDB表
- MyISAM
- 不支持事務,不支持外鍵
- 表鎖設計。插入data時,鎖定整個表
- 查表總行數時,不需要全表掃描
- 如果執行大量的SELECT,MyISAM是更好的選擇
- Memory存儲引擎
- data放在內存中,數據庫重啟或發生崩潰,表中的data消失
- 哈希索引,不是B+樹索引
NDB存儲引擎
是一個集群存儲引擎,類似於 Oracle 的 RAC 集群BLACKHOLE 黑洞存儲引擎
應用於--主備復制中的---分發主庫
2、事務 (存儲過程實現的)
事務(Transaction)是並發控制的基本單位。
將某些操作的多個sql作為原子性操作,這些操作要麽都執行,要麽都不執行,一旦某一個出現錯誤,即可回滾到原來的狀態,從而保證數據庫數據的完整性
ACID
- 原子性(Atomicity):一堆sql語句,要麽不執行,要麽全部執行
- 一致性(Consistency):事務開始前,結束後,數據庫的完整性約束沒有被破壞
- 隔離性(Isolation):多個事務並發訪問時,事務之間是隔離的,鎖實現的
- 持久性(Durability):事務一旦提交,對數據庫中的data改變是永久的,不會被回滾
https://blog.csdn.net/shuaihj/article/details/14163713
事務的三個常用命令
Begin Transaction、Commit Transaction、RollBack Transaction。
3、join什麽時候用?有幾種?區別
多表連接查詢、有外鍵關聯
- inner join(內連接):只匹配2張表中相關聯的記錄。
- left join(外連接之左連接):優先顯示左表全部記錄,在內連接的基礎上增加左表有右表沒有的結果,右表中未匹配到的字段用NULL表示。
- right join(外連接之右連接):優先顯示右表全部記錄,在內連接的基礎上增加右表有左表沒有的結果,左表中未匹配到的字段用NULL表示
- full join(全外連接):內連接基礎,增加左表有右表沒有和右表有左表沒有的結果;連接的表中不匹配的數據全部會顯示出來。
mysql 不支持full join 但是可以用 union - 交叉連接:笛卡爾積,顯示的結果是連接表數的乘積。
4、存儲過程
相當於函數,封裝了,一系列預編譯可執行的sql語句,存放在MySQL中。
直接調用它的名字,可以執行其內部的一堆sql
優點:
1.程序與sql解耦。一個存儲過程替代大量sql語句
2.執行效率高。存儲過程是預編譯的一個代碼塊
3.網絡傳輸量小。傳別名的數據量小,傳sql數據量大
4.確保數據安全。執行存儲過程需要用戶有一定權限
缺點:
1.程序猿拓展功能不方便
2.移植性差create procedure p1()
BEGIN
SELECT * FROM TABLE1;
END
#在mysql中調用
call p1() 5、視圖
視圖是一種虛擬的表,具有和物理表相同的功能。可以對視圖進行增刪改查
create view table1_view as select * from table1; 6、觸發器
觸發器是一種特殊的存儲過程,通過事件來觸發而被執行的。
使用觸發器可以定制用戶對表進行增、刪、改操作前後的行為
create trigger tri_after_insert_table1 after insert on table1 for each row
BEGIN
SELECT * FROM TABLE1;
END7、索引是什麽?什麽時候用?
相當於,新華字典的,音序表
數據庫管理系統中,一個排序好的數據結構,協助快速查詢data,範圍查詢data
create index ix_age on table1(age);
create index 索引名1,索引名2 on 表名('字段1','字段2')優勢
1.可以大大加快數據的檢索速度,(這也是創建索引的最主要的原因)
2.分組和排序,顯著減少時間
3.加速表和表之間的連接
4.創建唯一性索引,保證每一行數據的唯一性
代價
1.增加了數據庫的存儲空間,(每一個索引需要占用物理空間)
2.插入與修改data要花費較多時間,(index索引也跟著變動)什麽時候用?
1. 經常select查詢
2. 表記錄超級多
3. 列。經常搜索的列、主鍵列、外鍵列、排序的列、where上的列、範圍查找的列 age in [20,40]
什麽時候不用?
1. 經常update、delete、insert
2. 表記錄少
3. 列。不經常使用的列、數據值很少的列(固定電話)、定義為文本,圖片,bit的列、修改性能遠遠大於檢索性能的列B+樹:二叉樹---平衡二叉樹---B樹---B+樹---B-樹---B*樹---紅黑樹
http://www.cnblogs.com/oldhorse/archive/2009/11/16/1604009.html
https://blog.csdn.net/samjustin1/article/details/52664514
https://blog.csdn.net/xiaqunfeng123/article/details/52534468
https://blog.csdn.net/qq_26768741/article/details/53164202
B+樹
用途:用於數據庫索引,操作系統的文件系統中
特點:保持data穩定有序,插入與修改有較穩定的對數時間復雜度O(logN)
1.所有關鍵字的信息,都出現在葉子節點
2.所有非葉子節點,不存儲data,只存儲key,遞增排列
3.為所有葉子節點增加一個鏈指針
4.非葉子節點的key,是其子樹的最大或最小關鍵字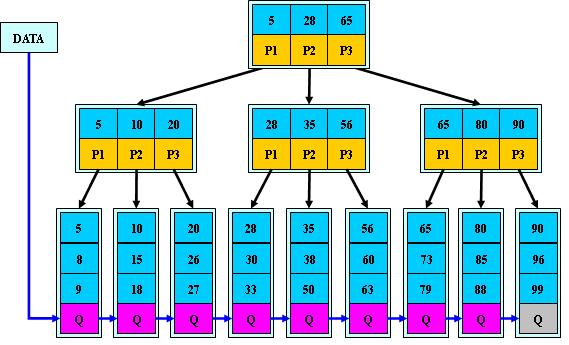
8.Mysql索引用B+樹而不用B-樹或者紅黑樹
Mysql如何衡量查詢效率呢?– 磁盤IO次數
1.B+樹節點小,磁盤I/O次數少
B+樹。葉節點存放data,其他節點用來索引
B-樹。每個索引節點都會有data區域
紅黑樹。樹的深度過大,IO讀寫頻繁
2.B+樹,支持範圍查詢,B樹不支持
所有的葉子節點用指針串起來,遍歷葉子節點,就能獲得全部數據,可以進行區間訪問https://blog.csdn.net/xiedelong/article/details/81417049
9、DDL、DML、DCL
DDL (define) 數據庫定義語言 database、table、view、index、producer、drop
DML(manager) 數據庫操縱語言 insert、delete、update、select
DCL (control) 數據庫控制語言 grant,revoke 權限
10、說一說三個範式。
- 第一範式(1NF):數據庫表中的字段都是單一屬性的,不可再分。
學生信息表,有姓名、年齡、性別、學號等信息組成 - 第二範式(2NF):滿足第一範式,表中的字段必須完全依賴於全部主鍵而非部分主鍵。
要有主鍵,要求其他字段都依賴於主鍵。 - 第三範式(3NF):滿足第二範式,非主鍵外的所有字段必須互不依賴
就是數據只在一個地方存儲,不重復出現在多張表中,可以認為就是消除傳遞依賴
消除傳遞依賴,方便理解,可以看做是“消除冗余”。
所謂傳遞函數依賴,指的是如 果存在"A → B → C"的決定關系,則C傳遞函數依賴於A。
11、drop、delete與truncate簡單說一說區別
SQL中的drop、delete、truncate都表示刪除,但是三者有一些差別
1.delete和truncate只刪除表的數據不刪除表的結構
2.速度,一般來說: drop> truncate >delete
3.delete語句是dml,這個操作會放到rollback segement中,事務提交之後才生效;如果有相應的trigger,執行的時候將被觸發.
4.truncate,drop是ddl, 操作立即生效,原數據不放到rollback segment中,不能回滾. 操作不觸發trigger.
5.安全性:小心使用drop 和truncate,尤其沒有備份的時候 ,不可回滾分別在什麽場景之下使用?
1.不再需要一張表的時候,用drop
2.想刪除部分數據行時候,用delete,並且帶上where子句
3.保留表而刪除所有數據的時候用truncate 12、sql語句
查詢來自杭州,並且訂單數少於2的客戶。
select a.customer_id, count(b.order_id) as total_orders
from table1 as a left join table2 as b
on a.customer_id = b.customer_id
where a.city = 'hangzhou'
group by a.customer_id
having count(b.order_id) < 2
order by total_orders desc
limit 1;13、char與varchar區別
char是固定長度的類型
vachar是可變長度的類型
char(10):定長,字符長度為10,浪費空間,存取速度快
root存成root000000,數據不足時,右邊用空格填充
varchar(10):變長,字符長度10,,精準,節省空間,存取速度慢
存儲數據的真實內容,不會填充,
1-2bytes的數據字節數 + 真實數據root14、數據庫優化問題
(1)服務層面:配置mysql性能優化參數;
(2)系統層面:優化數據表結構、字段類型、字段索引、分表,分庫、讀寫分離等等。
(3)數據庫層面:優化SQL語句,合理使用字段索引。
(4)代碼層面:使用緩存和NoSQL數據庫方式存儲,MongoDB/Memcached/Redis來緩解高並發下數據庫查詢的壓力。
(5)減少數據庫操作次數,盡量使用數據庫訪問驅動的批處理方法。
(6)不常使用的數據遷移備份,避免每次都在海量數據中去檢索。
(7)提升數據庫服務器硬件配置,或者搭建數據庫集群。
(8)編程手段防止SQL註入15、在數據庫中查詢語句速度很慢,如何優化?
1.建索引
2.減少表之間的關聯
3.優化sql,盡量讓sql很快定位數據,不要讓sql做全表查詢,應該走索引,把數據 量大的表排在前面
4.簡化查詢字段,沒用的字段不要,盡量返回少量數據
16、數據庫優化的思路
1.SQL語句優化
用Where子句替換HAVING 子句,因為HAVING 只會在檢索出所有記錄之後才對結果集進行
2.索引優化
看上文索引
3.數據庫結構優化
1)範式優化: 比如消除冗余(節省空間。。)
2)反範式優化:比如適當加冗余等(減少join)
3)拆分表、拆分庫
4)讀寫分離
4.服務器硬件優化17、你了解redis嗎?
- 高性能,非關系型數據庫,內存數據庫,減少磁盤I/O
- key-value類型,hashmap實現,復雜度O(1),查找與操作速度快
- 豐富的數據類型,string,list,set,hash
- 支持事務,操作都是原子性
- 必要時部分存在硬盤上
- 豐富的特性、可用於緩存,消息,按key設置過期時間,過期自動刪除
- mySQL裏有2000w數據,redis中只存20w的熱點數據,內存數據集達到一定大小的時候,施行數據淘汰策略(過期時間、最少使用)
03-數據庫必會問題