
Java快速入門-04-Java.util包簡單總結
學Java的程序員,lang包和util包最好是要過一遍的。
建議大家都序下載一個離線版開發文檔,查閱非常方便,我給大家提供一個中文版 jdk1.8 離線文檔,查看:JAVA - JDK 1.8 API 幫助文檔-中文版
1. util包的框架
常用的集合類主要實現兩個“super接口”而來:Collection和Map。
1.1 Collection有兩個子接口:List和Set
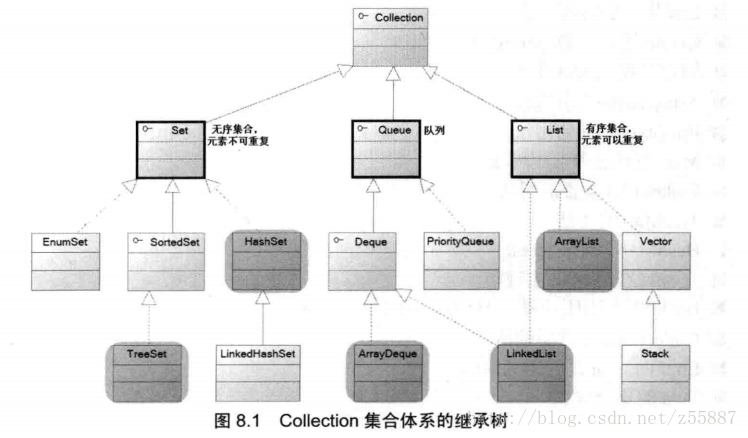
List特點是元素有序,且可重復。實現的常用集合類有ArrayList、LinkedList,和Vector(線程安全)。
Set特點是元素無序,不可重復。實現的常用集合類有HashSet,LinkedHashSet
TreeSet(可排序)
1.2 Map是key、value鍵值對的集合
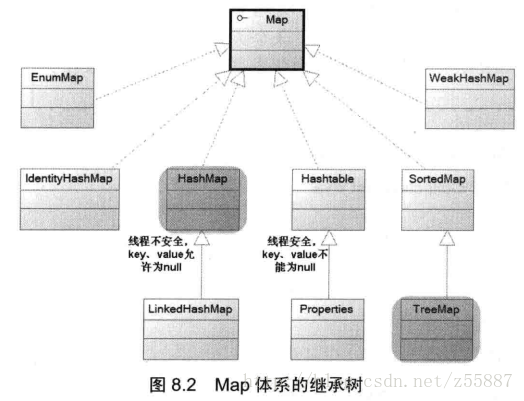
特點是key值無序不可重復,value值可重復(這樣表述其實不太準確,因為實際上key和value是綁定在一起的)。常用的有HashMap,HashTable(線程安全),TreeMap(可排序)。
1.3 其余重要接口和類
上面是util包中的集合框架,一般Java教材裏面都會講到。但我們深入研究一下,會發現還有其余幾個重要的內容:
- Iterator:叠代接口
集合類實現該接口後便具有了叠代功能。最簡單的叠代實現是ArrayList,叠代過程其實就是數組的叠代。LinkedList、LinkedHashSet和LinkedHashMap叠代過程就是鏈表的叠代。這兩者的叠代效率都很高,叠代時間與容器裏的元素數目成正比。但HashSet、HashMap叠代效率就略低了,因為采用了哈希表,所以元素是散列在數組中的,叠代時必須讀完整個數組,叠代時間與容器的容量成正比。 - Comparator:比較接口
實現該接口後,集合內元素便可比較通過compare()方法實現元素排序 - AbstractXXX:骨架類
所謂骨架類,其實就是不同集合的核心代碼實現,讓繼承這個抽象類的子類少幹點活。例如AbstarctList代表“隨機訪問”集合(底層數組實現)的骨幹代碼實現。AbstractSequentialList代表“連續訪問”(底層鏈表實現)集合的骨幹代碼實現。 - Collections、Arrays
集合工具類和數組工具類。Java中的工具類好像都喜歡在對應的接口或類名稱後,加S來表示其工具類。
接下來給一張比較完整的util包框架圖:
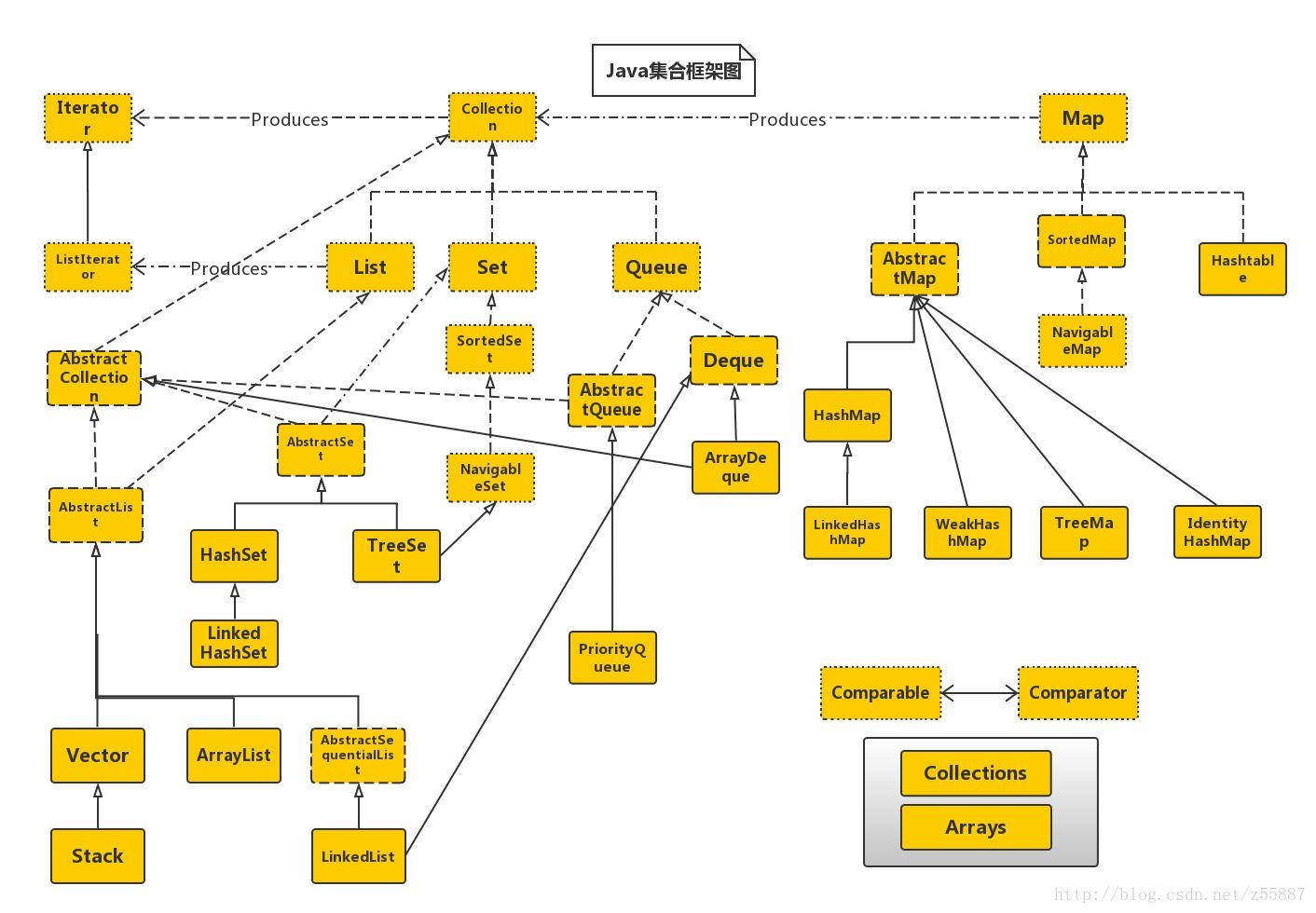
2. 常用集合類原理
2.1 ArrayList
ArrayList的實現最簡單,采用的順序表,底層就是一個Object數組,初始容量為10,每當元素要超過容量時,重新創建一個更大的數組,並把原數據拷到新數組中來。
2.2 LinkedList
LinkedList采用雙向鏈表。集合中的每一個元素都會有兩個成員變量prev和next,分別指向它的前一元素和後一元素。
ArrayList和LinkedList的區別這裏就不詳細討論了,其實就是順序表和鏈表兩種數據結構的區別。之前寫的博文中已經提到(包括ArrayList和LinkedList的詳細實現):
數據結構基礎(一)線性表
2.3 Vector
Vector底層實現和ArrayList類似,區別在於在許多方法上加了synchronized關鍵字,來實現了多線程安全。但代價是性能的降低。由於加鎖的是整個集合,所以並發情況下進行叠代會鎖住很長時間。
2.4 HashMap
HashMap采用的是哈希表結構,用鏈表法來解決hash沖突。這裏不詳細討論,之前的文章寫過:
HashMap原理解析
2.5 HashTable
HashTable的底層實現和HashMap類似,區別也是在許多方法上加了synchronized關鍵字,來實現了多線程安全。
2.6 LinkedHashMap
在HashMap的基礎上加了雙鏈表,該集合中的每個元素也都保留了前一個元素和後一個元素的“指針”。這樣便可以按照插入順序來讀取集合元素。也可設置為按照訪問順序來讀取集合元素。
由於要維護額外的雙鏈表,LinkedHashMap增刪操作會比HashMap慢,但叠代時會比HashMap快。
2.7 TreeMap
采用了紅黑樹數據結構,從而實現了有序集合。這個比較復雜,以後單獨開出一篇來討論,此處略。
2.8 HashSet、LinkedHashSet、TreeSet
Set和Map有千絲萬縷的聯系呀。例如HashSet底層實現其實就是一個固定value的HashMap。LinkedHashSet就是一個value固定的LinkedHashMap,TreeSet就是一個value固定的TreeMap。
3. 集合的並發
3.1 並發類的選擇
講到並發的集合,一般都想到util包中的兩個類:HashTable和Vector。然而實際使用情況中,並不推薦使用這兩個類。
首先,HashTable和Vector是從JDK1.0便存在的“古老”類,當時Collection、Map接口都還沒。這樣導致的問題是,當後來HashTable和Vector實現Map,Collection接口時,出現了許多無用而重復的方法。例如Vector原本有一個addElement()的方法,當實現了Collection接口後,又出現了一個add()方法。而實際上,這兩個方法一模一樣。
替代的這兩個並發類的常見方法是Collections.synchronizedXXX(…),這個方法可以把ArrayList,HashMap等集合變為線程安全的集合類。
那麽,Vector和Collections.synchronizedXXX(…)的底層實現有什麽區別呢?
我們來看看兩者的add()方法實現:
//Vector
public synchronized boolean add(E e) {
modCount++;
ensureCapacityHelper(elementCount + 1);
elementData[elementCount++] = e;
return true;
}
//Collections.SynchronizedList
public void add(int index, E element) {
synchronized (mutex) {list.add(index, element);}
}可以看出, 兩者實現多線程的方式都是對集合的方法加鎖,區別在於,Vector是對方法加鎖,鎖的是本對象,而Collections.synchronizedXXX(…)是對一個變量加鎖。區別並不大。
那麽,既然Collections.synchronizedXXX(…)比較好,用它創建出線程安全的集合類是不是就一勞永逸的滿足我們所有的需求了呢?很不幸,不完全是。
Collections.synchronizedXXX(…)和HashTable、Vector在高並發時都有著很大的性能缺陷。因為它們的增、刪、取都會鎖住整個集合。想一想,一個線程在叠代十萬個元素的Vector,其余線程對集合的操作時不時就阻塞了,受到了多大的影響啊。
為了解決這兩種方法在高並發下的性能的低下。我們查找一下Java的API,發現在java.util.concurrent裏面有許多針對高並發設計的類,例如:CopyOnWriteArrayList和ConcurrentHashMap。
ConcurrentHashMap的優化原理在於,采用了Segment的機制:
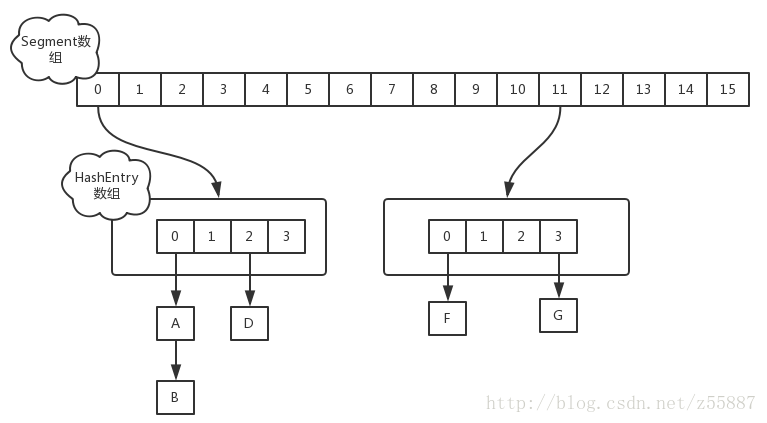
可以看成,ConcurrentHashMap底層每一個Segment都是一個HashMap,這樣增刪取時只需要鎖住一段的Segment,而不是整個集合。從而優化了高並發下的性能。
CopyOnWriteArrayList主要是對高並發下的讀、叠代做優化。實現原理在於每次add,remove操作都是重新創建一個新的數組,等操作結束再把引用指向新的數組。add,remove都是加了鎖的,而get方法沒有加鎖,因為每次叠代時都是在舊的數組上叠代。所以CopyOnWriteArrayList適用於讀多寫少的並發場景。
3.2 叠代fail-fast機制
之前寫的博文:Java叠代foreach原理解析(java.util.ConcurrentModificationException的原因)
Java快速入門-04-Java.util包簡單總結