
MySQL高可用MHA集群
MHA(Master High Availability)它由日本DeNA公司youshimaton開發,是一套優秀的作為MySQL高可用性環境下故障切換和主從提升的高可用軟件。在MySQL故障切換過程中,MHA能做到在0~30秒之內自動完成數據庫的故障切換操作,並且在進行故障切換的過程中,MHA能在最大程度上保證數據的一致性,以達到真正意義上的高可用。
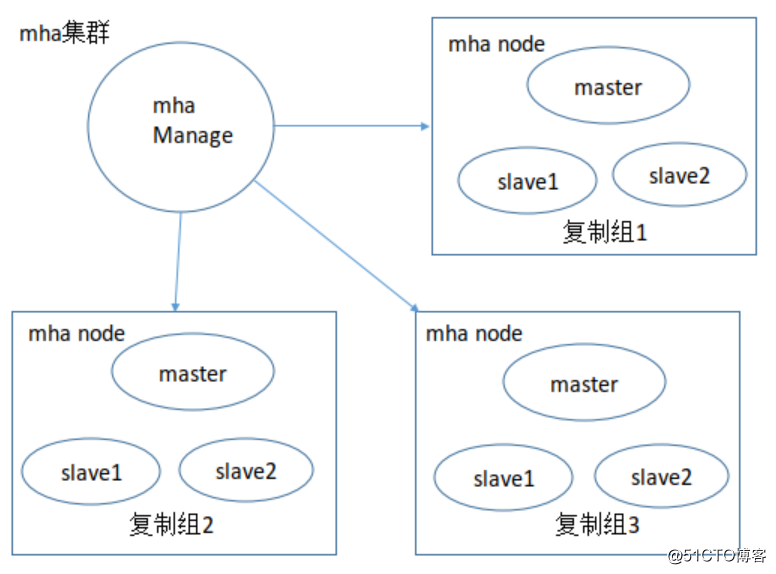
MHA軟件由兩部分組成:MHA Manager(管理節點)和MHA Node(數據節點)。MHA Manager可以單獨部署在一臺獨立的機器上管理多個master-slave集群,也可以部署在一臺slave節點上。MHA Node運行在每臺MySQL服務器上,MHA Manager會定時探測集群中的master節點,當master出現故障時,它可以自動將最新數據的slave提升為新的master,然後將所有其他的slave重新指向新的master。整個故障轉移過程對應用程序完全透明。
MHA工作原理
從宕機崩潰的master保存二進制日誌事件(binlog events)
識別含有最新更新的slave
應用差異的中繼日誌(relay log)到其他的slave
應用從master保存的二進制日誌事件(binlog events)
提升一個slave為新的master
使其他的slave連接新的master進行復制
MHA工具
masterha_check_ssh 檢查MHA的SSH配置狀況
masterha_check_repl 檢查MySQL復制狀況
masterha_manger 啟動MHA
masterha_check_status 檢測當前MHA運行狀態
masterha_master_switch 故障轉移(自動或手動)
masterha_conf_host 添加或刪除配置的server信息
MHA集群的搭建及恢復
環境準備:
- 4臺centos 7主機,
172.18.153.7做mha manage主機
172.18.153.17做MySQL master主機
172.18.153.27做MySQL slave1主機
172.18.153.37做MySQL slave2主機 - mha manage服務器 安裝mha4mysql-manager-0.56-0.el6.noarch.rpm和mha4mysql-node-0.56-0.el6.noarch.rpm,節點機安裝mha4mysql-node-0.56-0.el6.noarch.rpmmha下載
實驗步驟
- 配置時間同步
#mha服務器上ntpServer [root@localhost ~]# vim /etc/ntp.conf restrict 127.0.0.1 #限制可以同步的主機 restrict ::1 restrict 172.18.153.0 mask 255.255.255.0 server 127.127.1.0 #以該主機的時間為標準 [root@localhost ~]#systemctl restart ntpd [root@localhost ~]#systemctl restart ntpd #開機自啟動 #其他主機ntpclient [root@localhost ~]# vim /etc/ntp.conf server 172.18.153.7 iburst #確認ntpserver [root@localhost ~]# ntpdate 172.18.153.7 #生效 - 配置ssh的等效性(免密登陸)
#mha manage [root@localhost ~]# cd .ssh/ [root@localhost .ssh]# ssh-keygen [root@localhost .ssh]# ssh-copy-id localhost [root@localhost ~]# rsync -rav /root/.ssh [email protected]:/root/ [root@localhost ~]# rsync -rav /root/.ssh [email protected]:/root/ [root@localhost ~]# rsync -rav /root/.ssh [email protected]:/root/ #其他主機 [root@localhost ~]# vim /etc/ssh/ssh_config StrictHostKeyChecking no #ssh首次連接某主機不要詢問yes|no - 配置主從服務器
#mysql master [root@localhost ~]# vim /etc/my.cnf [mysqld] server_id=1 datadir=/mysql/data innodb_file_per_table socket=/var/lib/mysql/mysql.sock log_bin=/mysql/logbin/master-bin binlog_format=row skip_name_resolve [root@localhost ~]# systemctl restart mariadb.service [root@localhost ~]# mysql MariaDB [(none)]> show master status; +-------------------+-----------+ | Log_name | File_size | +-------------------+-----------+ | master-bin.000001 | 245 | +-------------------+-----------+ MariaDB [(none)]> grant replication slave on *.* to repluser@‘172.18.153.%‘ identified by ‘centos‘; #MySQL slave1與MySQLslave2一樣 [root@localhost ~]# vim /etc/my.cnf [mysqld] [mysqld] server_id=2 datadir=/mysql/data log_bin=/mysql/logbin/slave-log read_only=1 relay_log_purge=0 skip_name_resolve=1 [root@localhost ~]# systemctl restart mariadb.service [root@localhost ~]# mysql MariaDB [(none)]> CHANGE MASTER TO -> MASTER_HOST=‘172.18.153.17‘, -> MASTER_USER=‘repluser‘, -> MASTER_PASSWORD=‘centos‘, -> MASTER_PORT=3306, -> MASTER_LOG_FILE=‘master-bin.000001‘, -> MASTER_LOG_POS=245, -> MASTER_CONNECT_RETRY=10; MariaDB [(none)]> start slave; MariaDB [(none)]> show slave status\G; - 配置mha
#mha manage安裝mha manage 和mha node [root@localhost ~]# yum -y localinstall mha4mysql-* #安裝軟件 #其他主機安裝mha node [root@localhost ~]# yum localinstall mha4mysql-node-0.56-0.el6.noarch.rpm #mha managae [root@localhost ~]# mysql MariaDB [(none)]> grant all on *.* to mhauser@‘172.18.153.%‘ identified by ‘centos‘; [root@localhost ~]# mkdir /etc/mha [root@localhost ~]# vim /etc/mha/app1.conf [server default] user=mhauser password=centos manager_workdir=/data/mastermha/app1/ manager_log=/data/mastermha/app1/manager.log master_binlog_dir=/mysql/logbin remote_workdir=/data/mastermha/app1/ ssh_user=root repl_user=repluser repl_password=centos ping_interval=1 [server1] hostname=172.18.153.17 candidate_master=1 [server2] hostname=172.18.153.27 candidate_master=1 [server3] hostname=172.18.153.37mha 參數說明:
hostname
配置MySQL服務器的機器名或是IP地址,這個配置項是必須的,而且只能配置在[server_xxx]這個塊下面。
candidate_master
這個參數的作用是當設計candidate_master = 1時,這個服務器有較高的優先級提升為新的master(還要具備: 開啟binlog, 復制沒有延遲)。 所以當設置了candidate_master = 1的機器在master故障時必然成為新的master. 但這是很有用的設置優先級的一個參數。
如果設置了多臺機器的caddidate_master = 1 , 優先策略依賴於塊名字([server_xxx]). [server_1] 優銜權高於[server_2].user
用於管理MySQL的用戶名。這個最後需要root用戶,因為它需要執行:stop slave; change master to , reset slave.
password
MySQL的管理用戶的密碼
repl_user
MySQL用於復制的用戶,也是用於生成CHANGE MASTER TO 每個slave使用的用戶。 這個用戶必須有REPLICATION SLAVE權限在新的Master上。
master_binlog_dir
master上用於存儲binary日誌的全路徑。這個參數用於當master上mysql死掉後,通過ssh連到mysql服務器上,找到需要binary日誌事件
manager_workdir
用於指定mha manager產生相關狀態文件全路徑。 如果沒設置 默認是/var/tmp
manager_log
指定mha manager的絕對路徑的文件名日誌文件
ping_interval
這個參數設置MHA Manager多長時間去ping一下master(執行一些SQL語句). 當失去和master三次償試,MHA Manager會認為MySQL Master死掉了。也就是說,最大的故障切換時間是4次ping_interval的時間,默認是3秒。
remote_workdir
用於指定mha node產生相關狀態文件全路徑
- 檢查mha
#mha manage [root@localhost ~]# masterha_check_ssh --conf=/etc/mha/app1.conf [root@localhost ~]# masterha_check_repl --conf=/etc/mha/app1.conf - 運行mha
#mha manage [root@localhost ~]# nohup masterha_manager --conf=/etc/mha/app1.conf > mharun.log & #放到後端運行,把運行結果放到文件裏,檢測文件 - 模擬故障,直接關掉mysql master
#mha manage上,監控日誌文件,MySQL master 關閉以後日誌文件立馬刷新 [root@localhost ~]# tailf /data/mastermha/app1/manager.log Started automated(non-interactive) failover. The latest slave 172.18.153.27(172.18.153.27:3306) has all relay logs for recovery. Selected 172.18.153.27(172.18.153.27:3306) as a new master. 172.18.153.27(172.18.153.27:3306): OK: Applying all logs succeeded. 172.18.153.37(172.18.153.37:3306): This host has the latest relay log events. Generating relay diff files from the latest slave succeeded. 172.18.153.37(172.18.153.37:3306): OK: Applying all logs succeeded. Slave started, replicating from 172.18.153.27(172.18.153.27:3306) 172.18.153.27(172.18.153.27:3306): Resetting slave info succeeded. Master failover to 172.18.153.27(172.18.153.27:3306) completed successfully. [root@localhost ~]# tailf mharun.log Tue Oct 16 20:10:15 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Oct 16 20:10:15 2018 - [info] Reading application default configuration from /etc/mha/app1.conf.. Tue Oct 16 20:10:15 2018 - [info] Reading server configuration from /etc/mha/app1.conf.. Tue Oct 16 20:15:12 2018 - [warning] Global configuration file /etc/masterha_default.cnf not found. Skipping. Tue Oct 16 20:15:12 2018 - [info] Reading application default configuration from /etc/mha/app1.conf.. Tue Oct 16 20:15:12 2018 - [info] Reading server configuration from /etc/mha/app1.conf.. - 在切換成功後,再開啟舊的主,將舊的主設置為從。
[root@localhost ~]# vim /etc/my.cnf #增加兩行配置 [mysqld] read_only=ON relay_log_purge=0 [root@localhost ~]# systemctl restart mariadb.service [root@localhost ~]# mysql Master [(none)]> CHANGE MASTER TO -> MASTER_HOST=‘172.18.153.27‘, -> MASTER_USER=‘repluser‘, -> MASTER_PASSWORD=‘centos‘, -> MASTER_PORT=3306, -> MASTER_LOG_FILE=‘slave-log.000003‘, -> MASTER_LOG_POS=245, -> MASTER_CONNECT_RETRY=10; Master [(none)]> start slave; Master [(none)]> show slave status\G; - 完成了mha數據庫集群搭建和MySQL主從數據庫破壞後的恢復。
錯誤解決
錯誤1:檢查數據庫復制情況的時候報錯
Mon Jun 29 18:02:41 2015 - [error][/usr/local/share/perl5/MHA/ServerManager.pm, ln255] Got MySQL error when connecting 192.168.0.4(192.168.0.4:3306) :1045:Access denied for user ‘monitor‘@‘192.168.0.4‘ (using password: YES), but this is not mysql crash. Check MySQL server settings.
解決方法:所有數據庫節點都要創建監控用戶,監控用戶必須要
只在master上創建監控用戶:但是會被復制,在MySQL主從服務器中執行
grant all on . to mhauser@‘172.18.153.%‘ identified by ‘centos‘;
錯誤2:檢查數據庫復制情況的時候報錯
Tue Oct 16 20:06:17 2018 - [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln122] Got error when getting nod
Tue Oct 16 20:06:17 2018 - [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln123]
bash: apply_diff_relay_logs: command not found
Tue Oct 16 20:06:17 2018 - [error][/usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm, ln150] node version on 172.18.153age installed ?
at /usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 374.
Tue Oct 16 20:06:17 2018 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln424] Error happened on checki on 172.18.153.27 not found! Is MHA Node package installed ?
at /usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm line 374.
...propagated at /usr/share/perl5/vendor_perl/MHA/ManagerUtil.pm line 151.
Tue Oct 16 20:06:17 2018 - [error][/usr/share/perl5/vendor_perl/MHA/MasterMonitor.pm, ln523] Error happened on monito
Tue Oct 16 20:06:17 2018 - [info] Got exit code 1 (Not master dead).
MySQL Replication Health is NOT OK!
解決方法:你的mha node服務器中沒有檢測到mha4mysql-node,重新安裝即可,yum -y localinstall mha4mysql-node-0.56-0.el6.noarch.rpm
錯誤3:檢查數據庫復制情況的時候報錯
Mon Apr 13 20:02:15 2015 - [warning] relay_log_purge=0 is not set on slave vdbsrv2(172.16.16.12:3306).
解決方法:在MySQL從服務器上mysql -e ‘set global relay_log_purge=0‘
relay_log_purge:是否自動清空不再需要中繼日誌時。默認值為1(啟用)。
MySQL高可用MHA集群