
線程安全策略
線程限制:
- 一個被線程限制的對象,由線程獨占,並且只能被占有它的線程修改
共享只讀:
- 一個共享只讀的對象,在沒有額外同步的情況下,可以被多個線程並發訪問,但是任何線程都不能修改它
線程安全對象:
- 一個線程安全的對象或者容器,在內部通過同步機制來保證線程安全,所以其他線程無需額外的同步就可以通過公共接口隨意訪問它
被守護對象:
- 被守護對象只能通過獲取特定的鎖來訪問
不可變對象
有一種對象發布了就是安全的,這就是不可變對象,本小節簡單介紹一下不可變對象。不可變對象可以在多線程在保證線程安全,不可變對象需要滿足的條件:
- 對象創建以後其狀態就不能修改
- 對象所有域都是final類型
- 對象是正確創建的(在對象創建期間,this引用沒有逸出)
創建不可變對象的方式(參考String):
- 將類聲明成final類型,使其不可以被繼承
- 將所有的成員設置成私有的,使其他的類和對象不能直接訪問這些成員
- 對變量不提供set方法
- 將所有可變的成員聲明為final,這樣只能對他們賦值一次
- 通過構造器初始化所有成員,進行深度拷貝
- 在get方法中,不直接返回對象本身,而是克隆對象,返回對象的拷貝
提到不可變的對象就不得不說一下final關鍵字,該關鍵字可以修飾類、方法、變量:
- 修飾類:不能被繼承(final類中的所有方法都會被隱式的聲明為final方法)
- 修飾方法:
- 1、鎖定方法不被繼承類修改;
- 2、可提升效率(private方法被隱式修飾為final方法)
- 修飾變量:基本數據類型變量(初始化之後不能修改)、引用類型變量(初始化之後不能再修改其引用)
- 修飾方法參數:同修飾變量
通常我們會使用一些工具類來完成不可變對象的創建:
- Collections.unmodifiableXXX:Collection、List、Set、Map...
- Guava:ImmutableXXX:Collection、List、Set、Map...
由於這些工具類的存在,所以我們創建不可變對象並不是很費勁,而且其實現源碼也不會很難懂。所以如果需要自定義不可變對象,也可以參考這些工具類的實現源碼去進行實現。接下來我們看一下如何使用Collections.unmodifiableXXX方法將map轉換為一個不可變的對象,代碼如下:
@Slf4j
public class ImmutableExample2 {
private static Map<Integer, Integer> map = Maps.newHashMap();
static {
map.put(1, 2);
// 轉換成不可變對象
map = Collections.unmodifiableMap(map);
}
public static void main(String[] args) {
// 此時map就是不可變對象了,修改會報錯
map.put(1, 3);
log.info("{}", map.get(1));
}
}我們來看看是如何將map轉換為不可變對象的,源碼如下:
/**
* Returns an <a href="Collection.html#unmodview">unmodifiable view</a> of the
* specified map. Query operations on the returned map "read through"
* to the specified map, and attempts to modify the returned
* map, whether direct or via its collection views, result in an
* {@code UnsupportedOperationException}.<p>
*
* The returned map will be serializable if the specified map
* is serializable.
*
* @param <K> the class of the map keys
* @param <V> the class of the map values
* @param m the map for which an unmodifiable view is to be returned.
* @return an unmodifiable view of the specified map.
*/
public static <K,V> Map<K,V> unmodifiableMap(Map<? extends K, ? extends V> m) {
return new UnmodifiableMap<>(m);
}
/**
* @serial include
*/
private static class UnmodifiableMap<K,V> implements Map<K,V>, Serializable {
private static final long serialVersionUID = -1034234728574286014L;
private final Map<? extends K, ? extends V> m;
UnmodifiableMap(Map<? extends K, ? extends V> m) {
if (m==null)
throw new NullPointerException();
this.m = m;
}
public int size() {return m.size();}
public boolean isEmpty() {return m.isEmpty();}
public boolean containsKey(Object key) {return m.containsKey(key);}
public boolean containsValue(Object val) {return m.containsValue(val);}
public V get(Object key) {return m.get(key);}
public V put(K key, V value) {
throw new UnsupportedOperationException();
}
public V remove(Object key) {
throw new UnsupportedOperationException();
}
... 可以看到,實際上unmodifiableMap方法裏是返回了一個內部類UnmodifiableMap的實例。而這個UnmodifiableMap類實現了Map接口,並且在構造器中將我們傳入的map對象賦值到了final修飾的屬性m中。在該類中除了一些“查詢”方法,其他涉及到修改的方法都會拋出UnsupportedOperationException異常,這樣外部就無法修改該對象內的數據。我們在調用涉及到修改數據的方法都會報錯,這樣就實現了將一個可變對象轉換成一個不可變的對象。
除了以上示例中所使用的unmodifiableMap方法外,還有許多轉換不可變對象的方法,如下: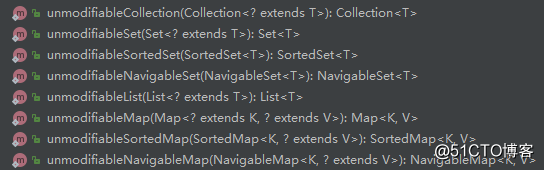
然後我們再來看看Guava中創建不可變對象的方法,示例代碼如下:
@Slf4j
public class ImmutableExample3 {
/**
* 不可變的list
*/
private final static List<Integer> list = ImmutableList.of(1, 2, 3);
/**
* 不可變的set
*/
private final static Set<Integer> set = ImmutableSet.copyOf(list);
/**
* 不可變的map,需要以k/v的形式傳入數據,即奇數位參數為key,偶數位參數為value
*/
private final static Map<Integer, Integer> map = ImmutableMap.of(1, 1, 2, 2, 3, 3);
/**
* 通過builder調用鏈的方式構造不可變的map
*/
private final static Map<Integer, Integer> map2 = ImmutableMap.<Integer, Integer>builder()
.put(1, 1).put(2, 2).put(3, 3).build();
public static void main(String[] args) {
// 修改對象內的數據就會拋出UnsupportedOperationException異常
list.add(4);
set.add(5);
map.put(1, 2);
map2.put(1, 2);
}
}不可變對象的概念也比較簡單,又有那麽多的工具類可供使用,所以學習起來也不是很困難。由於Guava中實現不可變對象的方式和Collections差不多,所以這裏就不對其源碼進行介紹了。
線程封閉
在上一小節中,我們介紹了不可變對象,不可變對象在多線程下是線程安全的,因為其避開了並發,而另一個更簡單避開並發的的方式就是本小節要介紹的線程封閉。
線程封閉最常見的應用就是用在數據庫連接對象上,數據庫連接對象本身並不是線程安全的,但由於線程封閉的作用,一個線程只會持有一個連接對象,並且持有的連接對象不會被其他線程所獲取,這樣就不會有線程安全的問題了。
線程封閉概念:
- 把對象封裝到一個線程裏,只有這個線程能看到這個對象。那麽即便這個對象本身不是線程安全的,但由於線程封閉的關系讓其只能在一個線程裏訪問,所以也就不會出現線程安全的問題了
實現線程封閉的方式:
- Ad-hoc 線程封閉:完全由程序控制實現,最糟糕的方式,忽略
- 堆棧封閉:局部變量,當多個線程訪問同一個方法的時候,方法內的局部變量都會被拷貝一份副本到線程的棧中,所以局部變量是不會被多個線程所共享的,因此無並發問題。所以我們在開發時應盡量使用局部變量而不是全局變量
- ThreadLocal 線程封閉:每個Thread線程內部都有個map,這個map是以線程本地對象作為key,以線程的變量副本作為value。而這個map是由ThreadLocal來維護的,由ThreadLocal負責向map裏設置線程的變量值,以及獲取值。所以對於不同的線程,每次獲取副本值的時候,其他線程都不能獲取當前線程的副本值,於是就形成了副本的隔離,多個線程互不幹擾。所以這是特別好的實現線程封閉的方式
ThreadLocal 應用的場景也比較多,例如在經典的web項目中,都會涉及到用戶的登錄。而服務器接收到每個請求都是開啟一個線程去處理的,所以我們通常會使用ThreadLocal存儲登錄的用戶信息對象,這樣我們就可以方便的在該請求生命周期內的任何位置獲取到用戶對象,並且不會有線程安全問題。示例代碼如下:
@Slf4j
public class RequestHolder {
private final static ThreadLocal<Long> REQUEST_HOLDER = new ThreadLocal<>();
/**
* 添加數據
*
* @param id id
*/
public static void add(User user) {
// ThreadLocal 內部維護一個map,key為當前線程id,value為當前set的變量
REQUEST_HOLDER.set(user);
}
/**
* 會通過當前線程id獲取數據
*
* @return id
*/
public static Long getId() {
return REQUEST_HOLDER.get();
}
/**
* 移除變量信息
* 如果不移除,那麽變量不會釋放掉,會造成內存泄漏
*/
public static void remove() {
REQUEST_HOLDER.remove();
}
}常見的線程不安全的類與寫法
所謂線程不安全的類,是指該類的實例對象可以同時被多個線程共享訪問,如果不做同步或線程安全的處理,就會表現出線程不安全的行為。
1.字符串拼接,在Java裏提供了兩個類可完成字符串拼接,就是StringBuilder和StringBuffer,其中StringBuilder是線程不安全的,而StringBuffer是線程安全的
StringBuffer之所以是線程安全的原因是幾乎所有的方法都加了synchronized關鍵字,所以是線程安全的。但是由於StringBuffer 是以加 synchronized 這種暴力的方式保證的線程安全,所以性能會相對較差,在堆棧封閉等線程安全的環境下應該首先選用StringBuilder。
2.SimpleDateFormat
SimpleDateFormat 的實例對象在多線程共享使用的時候會拋出轉換異常,正確的使用方法應該是采用堆棧封閉,將其作為方法內的局部變量而不是全局變量,在每次調用方法的時候才去創建一個SimpleDateFormat實例對象,這樣利於堆棧封閉就不會出現並發問題。另一種方式是使用第三方庫joda-time的DateTimeFormatter類(推薦使用)
錯誤寫法:
@Slf4j
public class DateFormatExample1 {
private static SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
private static void parse() {
try {
// 多線程訪問下會報錯
simpleDateFormat.parse("2018-02-08");
} catch (ParseException e) {
log.error("ParseException", e);
}
}
}正確寫法:
@Slf4j
public class DateFormatExample1 {
private static void parse() {
try {
// 在多線程下使用SimpleDateFormat的正確方式,利用堆棧封閉特性
SimpleDateFormat simpleDateFormat = new SimpleDateFormat("yyyy-MM-dd");
simpleDateFormat.parse("2018-02-08");
} catch (ParseException e) {
log.error("ParseException", e);
}
}
}推薦使用DateTimeFormatter類:
@Slf4j
public class DateFormatExample3 {
private static DateTimeFormatter dateTimeFormatter = DateTimeFormat.forPattern("yyyy-MM-dd");
private static void parse() {
Date date = DateTime.parse("2018-02-08", dateTimeFormatter).toDate();
}
}3.ArrayList, HashMap, HashSet 等 Collections 都是線程不安全的
4.有一種寫法需要註意,即便是線程安全的對象,在這種寫法下也可能會出現線程不安全的行為,這種寫法就是先檢查後執行:
if(condition(a)){
handle(a);
}在這個操作裏,可能會有兩個線程同時通過if的判斷,然後去執行了處理方法,那麽就會出現兩個線程同時操作一個對象,從而出現線程不安全的行為。這種寫法導致線程不安全的主要原因是因為這裏分成了兩步操作,這個過程是非原子性的,所以就會出現線程不安全的問題。
同步容器簡介
在上一小節中,我們提到了一些常用的線程不安全的集合容器,當我們在使用這些容器時,需要自行處理線程安全問題。所以使用起來相對會有些不便,而Java在這方面提供了相應的同步容器,我們可以在多線程情況下可以結合實際場景考慮使用這些同步容器。
1.在Java中同步容器主要分為兩類,一類是集合接口下的同步容器實現類:
- List -> Vector、Stack
- Map -> HashTable(key、value不能為null)
註:vector的所有方法都是有synchronized關鍵字保護的,stack繼承了vector,並且提供了棧操作(先進後出),而hashtable也是由synchronized關鍵字保護
但是需要註意的是同步容器也並不一定是絕對線程安全的,例如有兩個線程,線程A根據size的值循環執行remove操作,而線程B根據size的值循環執行執行get操作。它們都需要調用size獲取容器大小,當循環到最後一個元素時,若線程A先remove了線程B需要get的元素,那麽就會報越界錯誤。錯誤示例如下:
@Slf4j
public class VectorExample2 {
private static List<Integer> vector = new Vector<>();
public static void main(String[] args) {
while (true) {
for (int i = 0; i < 10; i++) {
vector.add(i);
}
Runnable thread1 = () -> {
for (int i = 0; i < vector.size(); i++) {
vector.remove(i);
}
};
Runnable thread2 = () -> {
for (int i = 0; i < vector.size(); i++) {
// 當thread2想獲取i=9的元素的時候,而thread1剛好將i=9的元素移除了,就會導致數組越界
vector.get(i);
}
};
new Thread(thread1).start();
new Thread(thread2).start();
}
}
}另外還有一點需要註意的是,當我們使用foreach循環或叠代器去遍歷元素的同時又執行刪除操作的話,即便在單線程下也會報並發修改異常。示例代碼如下:
public class VectorExample3 {
private static void test1(Vector<Integer> v1) {
// 在遍歷的同時進行了刪除的操作,會拋出java.util.ConcurrentModificationException並發修改異常
for (Integer integer : v1) {
if (integer.equals(5)) {
v1.remove(integer);
}
}
}
private static void test2(Vector<Integer> v1) {
// 在遍歷的同時進行了刪除的操作,會拋出java.util.ConcurrentModificationException並發修改異常
Iterator<Integer> iterator = v1.iterator();
while (iterator.hasNext()) {
Integer integer = iterator.next();
if (integer.equals(5)) {
v1.remove(integer);
}
}
}
private static void test3(Vector<Integer> v1) {
// 可以正常刪除
for (int i = 0; i < v1.size(); i++) {
if (v1.get(i).equals(5)) {
v1.remove(i);
}
}
}
public static void main(String[] args) {
Vector<Integer> vector = new Vector<>();
for (int i = 1; i <= 5; i++) {
vector.add(i);
}
test1(vector);
// test2(vector);
// test3(vector);
}
}所以在foreach循環或叠代器遍歷的過程中不能做刪除操作,若需遍歷的同時進行刪除操作的話盡量使用for循環。實在要使用foreach循環或叠代器的話應該先標記要刪除元素的下標,然後最後再統一刪除。如下示例:
private static void test4(Vector<Integer> v1) {
int delIndex = 0;
for (Integer integer : v1) {
if (integer.equals(5)) {
delIndex = v1.indexOf(integer);
}
}
v1.remove(delIndex);
}最方便的方式就是使用jdk1.8提供的函數式編程接口:
private static void test5(Vector<Integer> v1){
v1.removeIf((i) -> i.equals(5));
}2.第二類是Collections.synchronizedXXX (list,set,map)方法所創建的同步容器
示例代碼:
public class CollectionsExample{
private static List<Integer> list = Collections.synchronizedList(new ArrayList<>());
private static Set<Integer> set = Collections.synchronizedSet(new HashSet<>());
private static Map<Integer, Integer> map = Collections.synchronizedMap(new HashMap<>());
}並發容器簡介
在上一小節中,我們簡單介紹了常見的同步容器,知道了同步容器是通過synchronized來實現同步的,所以性能較差。而且同步容器也並不是絕對線程安全的,在一些特殊情況下也會出現線程不安全的行為。那麽有沒有更好的方式代替同步容器呢?答案是有的,那就是並發容器,有了並發容器後同步容器的使用也越來越少的,大部分都會優先使用並發容器。本小節將簡單介紹一下並發容器,並發容器也稱為J.U.C,即是其包名:java.util.concurrent。
1.ArrayList對應的CopyOnWriteArrayList:
CopyOnWrite容器即寫時復制的容器。通俗的理解是當我們往一個容器添加元素的時候,不直接往當前容器添加,而是先將當前容器進行Copy,復制出一個新的容器,然後新的容器裏添加元素,添加完元素之後,再將原容器的引用指向新的容器。這樣做的好處是我們可以對CopyOnWrite容器進行並發的讀,而不需要加鎖,因為當前容器不會添加任何元素。所以CopyOnWrite容器也是一種讀寫分離的思想,讀和寫不同的容器。而在CopyOnWriteArrayList寫的過程是會加鎖的,即調用add的時候,否則多線程寫的時候會Copy出N個副本出來。
CopyOnWriteArrayList.add()方法源碼如下(jdk11版本):
/**
* Appends the specified element to the end of this list.
*
* @param e element to be appended to this list
* @return {@code true} (as specified by {@link Collection#add})
*/
public boolean add(E e) {
//1、先加鎖
synchronized (lock) {
Object[] es = getArray();
int len = es.length;
//2、拷貝數組
es = Arrays.copyOf(es, len + 1);
//3、將元素加入到新數組中
es[len] = e;
//4、將array引用指向到新數組
setArray(es);
return true;
}
}讀的時候不需要加鎖,但是如果讀的時候有多個線程正在向CopyOnWriteArrayList添加數據,讀還是會讀到舊的數據,因為寫的時候不會鎖住舊的CopyOnWriteArrayList。CopyOnWriteArrayList.get()方法源碼如下(jdk11版本):
/**
* {@inheritDoc}
*
* @throws IndexOutOfBoundsException {@inheritDoc}
*/
public E get(int index) {
return elementAt(getArray(), index);
}CopyOnWriteArrayList容器有很多優點,但是同時也存在兩個問題,即內存占用問題和數據一致性問題:
-
內存占用問題:
因為CopyOnWriteArrayList的寫操作時的復制機制,所以在進行寫操作的時候,內存裏會同時駐紮兩個對象的內存,舊的對象和新寫入的對象(註意:在復制的時候只是復制容器裏的引用,只是在寫的時候會創建新對象添加到新容器裏,而舊容器的對象還在使用,所以有兩份對象內存)。如果這些對象占用的內存比較大,比如說200M左右,那麽再寫入100M數據進去,內存就會占用300M,那麽這個時候很有可能造成頻繁的Yong GC和Full GC。之前我們系統中使用了一個服務由於每晚使用CopyOnWrite機制更新大對象,造成了每晚15秒的Full GC,應用響應時間也隨之變長。
針對內存占用問題,可以通過壓縮容器中的元素的方法來減少大對象的內存消耗,比如,如果元素全是10進制的數字,可以考慮把它壓縮成36進制或64進制。或者不使用CopyOnWrite容器,而使用其他的並發容器,如ConcurrentHashMap。
- 數據一致性問題:
CopyOnWriteArrayList容器只能保證數據的最終一致性,不能保證數據的實時一致性。所以如果你希望寫入的的數據,馬上能讀到,即實時讀取場景,那麽請不要使用CopyOnWriteArrayList容器。
CopyOnWrite的應用場景:
綜上,CopyOnWriteArrayList並發容器用於讀多寫少的並發場景。不過這類慎用因為誰也沒法保證CopyOnWriteArrayList 到底要放置多少數據,萬一數據稍微有點多,每次add/set都要重新復制數組,這個代價實在太高昂了。在高性能的互聯網應用中,這種操作分分鐘引起故障。
參考文章:
http://ifeve.com/java-copy-on-write/#more-10403
2.HashSet對應的CopyOnWriteArraySet
CopyOnWriteArraySet是線程安全的,它底層的實現使用了CopyOnWriteArrayList,因此和CopyOnWriteArrayList概念是類似的。使用叠代器進行遍歷的速度很快,並且不會與其他線程發生沖突。在構造叠代器時,叠代器依賴於不可變的數組快照,所以叠代器不支持可變的 remove 操作。
CopyOnWriteArraySet適合於具有以下特征的場景:
- set 大小通常保持很小,只讀操作遠多於可變操作,需要在遍歷期間防止線程間的沖突。
CopyOnWriteArraySet缺點:
- 因為通常需要復制整個基礎數組,所以可變操作(add、set 和 remove 等等)的開銷很大。
3.TreeSet對應的ConcurrentSkipListSet
ConcurrentSkipListSet是jdk6新增的類,它和TreeSet一樣是支持自然排序的,並且可以在構造的時候定義Comparator<E> 的比較器,該類的方法基本和TreeSet中方法一樣(方法簽名一樣)。和其他的Set集合一樣,ConcurrentSkipListSet是基於Map集合的,ConcurrentSkipListMap便是它的底層實現
在多線程的環境下,ConcurrentSkipListSet中的contains、add、remove操作是安全的,多個線程可以安全地並發執行插入、移除和訪問操作。但是對於批量操作 addAll、removeAll、retainAll 和 containsAll並不能保證以原子方式執行。理由很簡單,因為addAll、removeAll、retainAll底層調用的還是contains、add、remove的方法,在批量操作時,只能保證每一次的contains、add、remove的操作是原子性的(即在進行contains、add、remove三個操作時,不會被其他線程打斷),而不能保證每一次批量的操作都不會被其他線程打斷。所以在進行批量操作時,需自行額外手動做一些同步、加鎖措施,以此保證線程安全。另外,ConcurrentSkipListSet類不允許使用 null 元素,因為無法可靠地將 null 參數及返回值與不存在的元素區分開來。
4.HashMap對應的ConcurrentHashMap
HashMap的並發安全版本是ConcurrentHashMap,但ConcurrentHashMap不允許 null 值。在大多數情況下,我們使用map都是讀取操作,寫操作比較少。因此ConcurrentHashMap針對讀取操作做了大量的優化,所以ConcurrentHashMap具有很高的並發性,在高並發場景下表現良好。關於ConcurrentHashMap詳細的內容會在後續文章中進行介紹。
5.TreeMap對應的ConcurrentSkipListMap
ConcurrentSkipListMap的底層是通過跳表來實現的。跳表是一個鏈表,但是通過使用“跳躍式”查找的方式使得插入、讀取數據時復雜度變成了O(logn)。
有人曾比較過ConcurrentHashMap和ConcurrentSkipListMap的性能,在4線程1.6萬數據的條件下,ConcurrentHashMap 存取速度是ConcurrentSkipListMap 的4倍左右。
但ConcurrentSkipListMap有幾個ConcurrentHashMap不能比擬的優點:
- ConcurrentSkipListMap 的key是有序的
- ConcurrentSkipListMap 支持更高的並發。ConcurrentSkipListMap的存取時間是O(logn),和線程數幾乎無關。也就是說在數據量一定的情況下,並發的線程越多,ConcurrentSkipListMap越能體現出其優勢
在非多線程的情況下,應當盡量使用TreeMap。此外對於並發性相對較低的並行程序可以使Collections.synchronizedSortedMap將TreeMap進行包裝,也可以提供較好的效率。對於高並發程序,應當使用ConcurrentSkipListMap,能夠提供更高的並發度。
所以在多線程程序中,如果需要對Map的鍵值進行排序時,請盡量使用ConcurrentSkipListMap,可能得到更好的並發度。
註意,調用ConcurrentSkipListMap的size時,由於多個線程可以同時對映射表進行操作,所以映射表需要遍歷整個鏈表才能返回元素個數,這個操作是個O(log(n))的操作。
線程安全策略