
揭開Java 泛型類型擦除神秘面紗
大家可能會有疑問,我為什麽叫做泛型是一個守門者。這其實是我個人的看法而已,我的意思是說泛型沒有其看起來那麽深不可測,它並不神秘與神奇。泛型是 Java 中一個很小巧的概念,但同時也是一個很容易讓人迷惑的知識點,它讓人迷惑的地方在於它的許多表現有點違反直覺。
文章開始的地方,先給大家奉上一道經典的測試題。
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass());
請問,上面代碼最終結果輸出的是什麽?不了解泛型的和很熟悉泛型的同學應該能夠答出來,而對泛型有所了解,但是了解不深入的同學可能會答錯。
正確答案是 true。
上面的代碼中涉及到了泛型,而輸出的結果緣由是類型擦除。先好好說說泛型。
泛型是什麽?
泛型的英文是 generics,generic 的意思是通用,而翻譯成中文,泛應該意為廣泛,型是類型。所以泛型就是能廣泛適用的類型。
但泛型還有一種較為準確的說法就是為了參數化類型,或者說可以將類型當作參數傳遞給一個類或者是方法。
那麽,如何解釋類型參數化呢?
public class Cache {
Object value;
public Object getValue() {return value;
}
public void setValue(Object value) {
this.value = value;
}
}
假設 Cache 能夠存取任何類型的值,於是,我們可以這樣使用它。
Cache cache = new Cache();
cache.setValue(134);
int value = (int) cache.getValue();
cache.setValue("hello");
String value1 = (String) cache.getValue();
使用的方法也很簡單,只要我們做正確的強制轉換就好了。
但是,泛型卻給我們帶來了不一樣的編程體驗。
public class Cache<T> {
T value;
public Object getValue() {
return value;
}
public void setValue(T value) {
this.value = value;
}
}
這就是泛型,它將 value 這個屬性的類型也參數化了,這就是所謂的參數化類型。再看它的使用方法。
Cache<String> cache1 = new Cache<String>();
cache1.setValue("123");
String value2 = cache1.getValue();
Cache<Integer> cache2 = new Cache<Integer>();
cache2.setValue(456);
int value3 = cache2.getValue();
最顯而易見的好處就是它不再需要對取出來的結果進行強制轉換了。但,還有另外一點不同。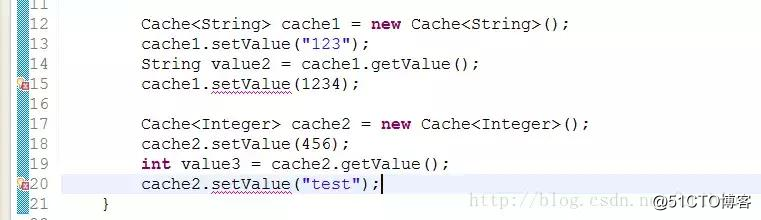
泛型除了可以將類型參數化外,而參數一旦確定好,如果類似不匹配,編譯器就不通過。
上面代碼顯示,無法將一個 String 對象設置到 cache2 中,因為泛型讓它只接受 Integer 的類型。
所以,綜合上面信息,我們可以得到下面的結論。
與普通的 Object 代替一切類型這樣簡單粗暴而言,泛型使得數據的類別可以像參數一樣由外部傳遞進來。它提供了一種擴展能力。它更符合面向抽象開發的軟件編程宗旨。
當具體的類型確定後,泛型又提供了一種類型檢測的機制,只有相匹配的數據才能正常的賦值,否則編譯器就不通過。所以說,它是一種類型安全檢測機制,一定程度上提高了軟件的安全性防止出現低級的失誤。
泛型提高了程序代碼的可讀性,不必要等到運行的時候才去強制轉換,在定義或者實例化階段,因為 Cache<String> 這個類型顯化的效果,程序員能夠一目了然猜測出代碼要操作的數據類型。
下面的文章,我們正常介紹泛型的相關知識。
泛型的定義和使用
泛型按照使用情況可以分為 3 種。
-
泛型類。
-
泛型方法。
- 泛型接口。
泛型類
我們可以這樣定義一個泛型類。
public class Test<T> {
T field1;
}
尖括號 <> 中的 T 被稱作是類型參數,用於指代任何類型。事實上,T 只是一種習慣性寫法,如果你願意。你可以這樣寫。
public class Test<Hello> {
Hello field1;
}
但出於規範的目的,Java 還是建議我們用單個大寫字母來代表類型參數。常見的如:
-
T 代表一般的任何類。
-
E 代表 Element 的意思,或者 Exception 異常的意思。
-
K 代表 Key 的意思。
-
V 代表 Value 的意思,通常與 K 一起配合使用。
- S 代表 Subtype 的意思,文章後面部分會講解示意。
如果一個類被 <T> 的形式定義,那麽它就被稱為是泛型類。
那麽對於泛型類怎麽樣使用呢?
Test<String> test1 = new Test<>();
Test<Integer> test2 = new Test<>();
只要在對泛型類創建實例的時候,在尖括號中賦值相應的類型便是。T 就會被替換成對應的類型,如 String 或者是 Integer。你可以相像一下,當一個泛型類被創建時,內部自動擴展成下面的代碼。
public class Test<String> {
String field1;
}
當然,泛型類不至接受一個類型參數,它還可以這樣接受多個類型參數。
public class MultiType <E,T>{
E value1;
T value2;
public E getValue1(){
return value1;
}
public T getValue2(){
return value2;
}
}
泛型方法
public class Test1 {
public <T> void testMethod(T t){
}
}
泛型方法與泛型類稍有不同的地方是,類型參數也就是尖括號那一部分是寫在返回值前面的。<T> 中的 T 被稱為類型參數,而方法中的 T 被稱為參數化類型,它不是運行時真正的參數。
當然,聲明的類型參數,其實也是可以當作返回值的類型的。
public <T> T testMethod1(T t){
return null;
}
泛型類與泛型方法的共存現象
public class Test1<T>{
public void testMethod(T t){
System.out.println(t.getClass().getName());
}
public <T> T testMethod1(T t){
return t;
}
}
上面代碼中,Test1<T> 是泛型類,testMethod 是泛型類中的普通方法,而 testMethod1 是一個泛型方法。而泛型類中的類型參數與泛型方法中的類型參數是沒有相應的聯系的,泛型方法始終以自己定義的類型參數為準。
所以,針對上面的代碼,我們可以這樣編寫測試代碼。
Test1<String> t = new Test1();
t.testMethod("generic");
Integer i = t.testMethod1(new Integer(1));
泛型類的實際類型參數是 String,而傳遞給泛型方法的類型參數是 Integer,兩者不想幹。
但是,為了避免混淆,如果在一個泛型類中存在泛型方法,那麽兩者的類型參數最好不要同名。比如,Test1<T> 代碼可以更改為這樣
public class Test1<T>{
public void testMethod(T t){
System.out.println(t.getClass().getName());
}
public <E> E testMethod1(E e){
return e;
}
}
泛型接口
泛型接口和泛型類差不多,所以一筆帶過。
public interface Iterable<T> {
}
通配符 ?
除了用 <T> 表示泛型外,還有 <?> 這種形式。? 被稱為通配符。
可能有同學會想,已經有了 <T> 的形式了,為什麽還要引進 <?> 這樣的概念呢?
class Base{}
class Sub extends Base{}
Sub sub = new Sub();
Base base = sub;
上面代碼顯示,Base 是 Sub 的父類,它們之間是繼承關系,所以 Sub 的實例可以給一個 Base 引用賦值,那麽
List<Sub> lsub = new ArrayList<>();
List<Base> lbase = lsub;
最後一行代碼成立嗎?編譯會通過嗎?
答案是否定的。
編譯器不會讓它通過的。Sub 是 Base 的子類,不代表 List<Sub> 和 List<Base> 有繼承關系。
但是,在現實編碼中,確實有這樣的需求,希望泛型能夠處理某一範圍內的數據類型,比如某個類和它的子類,對此 Java 引入了通配符這個概念。
所以,通配符的出現是為了指定泛型中的類型範圍。
通配符有 3 種形式。
<?> 被稱作無限定的通配符。
<? extends T> 被稱作有上限的通配符。
<? super T> 被稱作有下限的通配符。
無限定通配符
public void testWildCards(Collection<?> collection){
}
上面的代碼中,方法內的參數是被無限定通配符修飾的 Collection 對象,它隱略地表達了一個意圖或者可以說是限定,那就是 testWidlCards() 這個方法內部無需關註 Collection 中的真實類型,因為它是未知的。所以,你只能調用 Collection 中與類型無關的方法。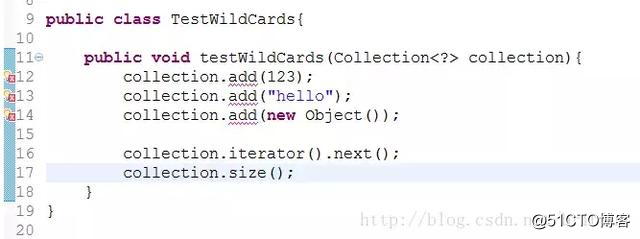
我們可以看到,當 <?> 存在時,Collection 對象喪失了 add() 方法的功能,編譯器不通過。
我們再看代碼。
List<?> wildlist = new ArrayList<String>();
wildlist.add(123);// 編譯不通過
有人說,<?> 提供了只讀的功能,也就是它刪減了增加具體類型元素的能力,只保留與具體類型無關的功能。它不管裝載在這個容器內的元素是什麽類型,它只關心元素的數量、容器是否為空?我想這種需求還是很常見的吧。
有同學可能會想,<?> 既然作用這麽渺小,那麽為什麽還要引用它呢?
個人認為,提高了代碼的可讀性,程序員看到這段代碼時,就能夠迅速對此建立極簡潔的印象,能夠快速推斷源碼作者的意圖。
<? extends T>
<?> 代表著類型未知,但是我們的確需要對於類型的描述再精確一點,我們希望在一個範圍內確定類別,比如類型 A 及 類型 A 的子類都可以。
public void testSub(Collection<? extends Base> para){
}
上面代碼中,para 這個 Collection 接受 Base 及 Base 的子類的類型。
但是,它仍然喪失了寫操作的能力。也就是說
para.add(new Sub());
para.add(new Base());
仍然編譯不通過。
沒有關系,我們不知道具體類型,但是我們至少清楚了類型的範圍。
<? super T>
這個和 <? extends T> 相對應,代表 T 及 T 的超類。
<? super T> 神奇的地方在於,它擁有一定程度的寫操作的能力。
public void testSuper(Collection<? super Sub> para){
para.add(new Sub());//編譯通過
para.add(new Base());//編譯不通過
}
通配符與類型參數的區別
一般而言,通配符能幹的事情都可以用類型參數替換。
比如
public void testWildCards(Collection<?> collection){}
可以被
public <T> void test(Collection<T> collection){}
取代。
值得註意的是,如果用泛型方法來取代通配符,那麽上面代碼中 collection 是能夠進行寫操作的。只不過要進行強制轉換。
public <T> void test(Collection<T> collection){
collection.add((T)new Integer(12));
collection.add((T)"123");
}
需要特別註意的是,類型參數適用於參數之間的類別依賴關系,舉例說明。public class Test2 <T,E extends T>{
T value1;
E value2;
}public <D,S extends D> void test(D d,S s){
}
E 類型是 T 類型的子類,顯然這種情況類型參數更適合。
有一種情況是,通配符和類型參數一起使用。
public <T> void test(T t,Collection<? extends T> collection){
}
如果一個方法的返回類型依賴於參數的類型,那麽通配符也無能為力。
public T test1(T t){
return value1;
}
類型擦除
泛型是 Java 1.5 版本才引進的概念,在這之前是沒有泛型的概念的,但顯然,泛型代碼能夠很好地和之前版本的代碼很好地兼容。
這是因為,泛型信息只存在於代碼編譯階段,在進入 JVM 之前,與泛型相關的信息會被擦除掉,專業術語叫做類型擦除。
通俗地講,泛型類和普通類在 java 虛擬機內是沒有什麽特別的地方。回顧文章開始時的那段代碼
List<String> l1 = new ArrayList<String>();
List<Integer> l2 = new ArrayList<Integer>();
System.out.println(l1.getClass() == l2.getClass());
打印的結果為 true 是因為 List<String> 和 List<Integer> 在 jvm 中的 Class 都是 List.class。
泛型信息被擦除了。
可能同學會問,那麽類型 String 和 Integer 怎麽辦?
答案是泛型轉譯。
public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
}
Erasure 是一個泛型類,我們查看它在運行時的狀態信息可以通過反射。
Erasure<String> erasure = new Erasure<String>("hello");
Class eclz = erasure.getClass();
System.out.println("erasure class is:"+eclz.getName());
打印的結果是
erasure class is:com.frank.test.Erasure
Class 的類型仍然是 Erasure 並不是 Erasure<T> 這種形式,那我們再看看泛型類中 T 的類型在 jvm 中是什麽具體類型。
Field[] fs = eclz.getDeclaredFields();
for ( Field f:fs) {
System.out.println("Field name "+f.getName()+" type:"+f.getType().getName());
}
打印結果是
Field name object type:java.lang.Object
那我們可不可以說,泛型類被類型擦除後,相應的類型就被替換成 Object 類型呢?
這種說法,不完全正確。
我們更改一下代碼。
public class Erasure <T extends String>{
// public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
}
現在再看測試結果:
Field name object type:java.lang.String
我們現在可以下結論了,在泛型類被類型擦除的時候,之前泛型類中的類型參數部分如果沒有指定上限,如 <T> 則會被轉譯成普通的 Object 類型,如果指定了上限如 <T extends String> 則類型參數就被替換成類型上限。
所以,在反射中。
public class Erasure <T>{
T object;
public Erasure(T object) {
this.object = object;
}
public void add(T object){
}
}
add() 這個方法對應的 Method 的簽名應該是 Object.class。
Erasure<String> erasure = new Erasure<String>("hello");
Class eclz = erasure.getClass();
System.out.println("erasure class is:"+eclz.getName());
Method[] methods = eclz.getDeclaredMethods();
for ( Method m:methods ){
System.out.println(" method:"+m.toString());
}
打印結果是
method:public void com.frank.test.Erasure.add(java.lang.Object)
也就是說,如果你要在反射中找到 add 對應的 Method,你應該調用 getDeclaredMethod("add",Object.class) 否則程序會報錯,提示沒有這麽一個方法,原因就是類型擦除的時候,T 被替換成 Object 類型了。
類型擦除帶來的局限性
類型擦除,是泛型能夠與之前的 java 版本代碼兼容共存的原因。但也因為類型擦除,它會抹掉很多繼承相關的特性,這是它帶來的局限性。
理解類型擦除有利於我們繞過開發當中可能遇到的雷區,同樣理解類型擦除也能讓我們繞過泛型本身的一些限制。比如
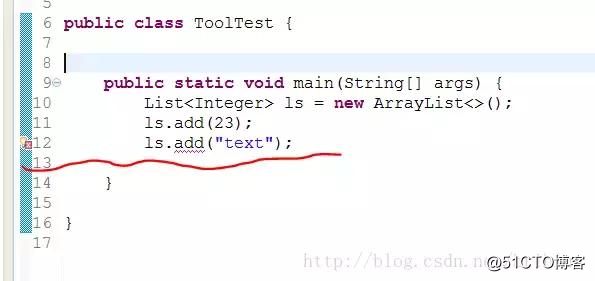
正常情況下,因為泛型的限制,編譯器不讓最後一行代碼編譯通過,因為類似不匹配,但是,基於對類型擦除的了解,利用反射,我們可以繞過這個限制。
public interface List<E> extends Collection<E>{
boolean add(E e);
}
上面是 List 和其中的 add() 方法的源碼定義。
因為 E 代表任意的類型,所以類型擦除時,add 方法其實等同於
boolean add(Object obj);
那麽,利用反射,我們繞過編譯器去調用 add 方法。
public class ToolTest {
public static void main(String[] args) {
List<Integer> ls = new ArrayList<>();
ls.add(23);
// ls.add("text");
try {
Method method = ls.getClass().getDeclaredMethod("add",Object.class);
method.invoke(ls,"test");
method.invoke(ls,42.9f);
} catch (NoSuchMethodException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (SecurityException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalAccessException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (IllegalArgumentException e) {
// TODO Auto-generated catch block
e.printStackTrace();
} catch (InvocationTargetException e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
for ( Object o: ls){
System.out.println(o);
}
}
}
打印結果是:
23
test
42.9
可以看到,利用類型擦除的原理,用反射的手段就繞過了正常開發中編譯器不允許的操作限制。
泛型中值得註意的地方
泛型類或者泛型方法中,不接受 8 種基本數據類型。
所以,你沒有辦法進行這樣的編碼。
List<int> li = new ArrayList<>();
List<boolean> li = new ArrayList<>();
需要使用它們對應的包裝類。
List<Integer> li = new ArrayList<>();
List<Boolean> li1 = new ArrayList<>();
對泛型方法的困惑
public <T> T test(T t){
return null;
}
有的同學可能對於連續的兩個 T 感到困惑,其實 <T> 是為了說明類型參數,是聲明,而後面的不帶尖括號的 T 是方法的返回值類型。
你可以相像一下,如果 test() 這樣被調用
test("123");
那麽實際上相當於
public String test(String t);
Java 不能創建具體類型的泛型數組
這句話可能難以理解,代碼說明。
List<Integer>[] li2 = new ArrayList<Integer>[];
List<Boolean> li3 = new ArrayList<Boolean>[];
這兩行代碼是無法在編譯器中編譯通過的。原因還是類型擦除帶來的影響。
List<Integer> 和 List<Boolean> 在 jvm 中等同於List<Object> ,所有的類型信息都被擦除,程序也無法分辨一個數組中的元素類型具體是 List<Integer>類型還是 List<Boolean> 類型。
但是,
List<?>[] li3 = new ArrayList<?>[10];
li3[1] = new ArrayList<String>();
List<?> v = li3[1];
借助於無限定通配符卻可以,前面講過 ? 代表未知類型,所以它涉及的操作都基本上與類型無關,因此 jvm 不需要針對它對類型作判斷,因此它能編譯通過,但是,只提供了數組中的元素因為通配符原因,它只能讀,不能寫。比如,上面的 v 這個局部變量,它只能進行 get() 操作,不能進行 add() 操作,這個在前面通配符的內容小節中已經講過。
泛型,並不神奇
我們可以看到,泛型其實並沒有什麽神奇的地方,泛型代碼能做的非泛型代碼也能做。
而類型擦除,是泛型能夠與之前的 java 版本代碼兼容共存的原因。
可量也正因為類型擦除導致了一些隱患與局限。
但,我還是要建議大家使用泛型,如官方文檔所說的,如果可以使用泛型的地方,盡量使用泛型。
畢竟它抽離了數據類型與代碼邏輯,本意是提高程序代碼的簡潔性和可讀性,並提供可能的編譯時類型轉換安全檢測功能。
類型擦除不是泛型的全部,但是它卻能很好地檢測我們對於泛型這個概念的理解程度。
我在文章開頭將泛型比作是一個守門人,原因就是他本意是好的,守護我們的代碼安全,然後在門牌上寫著出入的各項規定,及“xxx 禁止出入”的提醒。但是同我們日常所遇到的那些門衛一般,他們古怪偏執,死板守舊,我們可以利用反射基於類型擦除的認識,來繞過泛型中某些限制,現實生活中,也總會有調皮搗蛋者能夠基於對門衛們生活作息的規律,選擇性地繞開他們的監視,另辟蹊徑溜進或者溜出大門,然後揚長而去,剩下守衛者一個孤獨的身影。
所以,我說泛型,並不神秘,也不神奇。
揭開Java 泛型類型擦除神秘面紗