
Java中的線程池——ThreadPoolExecutor的原理
向線程池提交一個任務後,它的主要處理流程如下圖所示
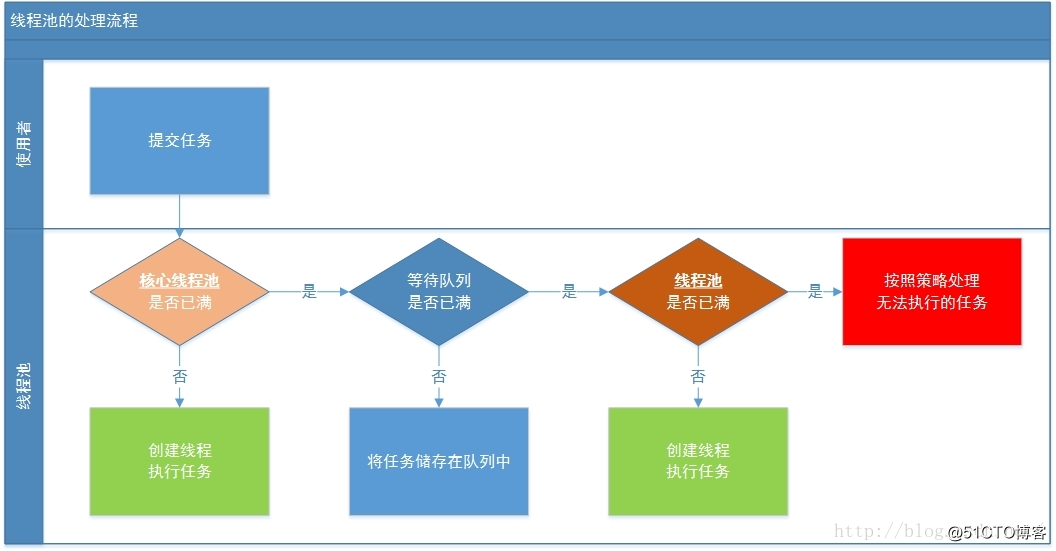
一個線程從被提交(submit)到執行共經歷以下流程:
線程池判斷核心線程池裏是的線程是否都在執行任務,如果不是,則創建一個新的工作線程來執行任務。如果核心線程池裏的線程都在執行任務,則進入下一個流程
線程池判斷工作隊列是否已滿。如果工作隊列沒有滿,則將新提交的任務儲存在這個工作隊列裏。如果工作隊列滿了,則進入下一個流程。
線程池判斷其內部線程是否都處於工作狀態。如果沒有,則創建一個新的工作線程來執行任務。如果已滿了,則交給飽和策略來處理這個任務。
線程池在執行excute方法時,主要有以下四種情況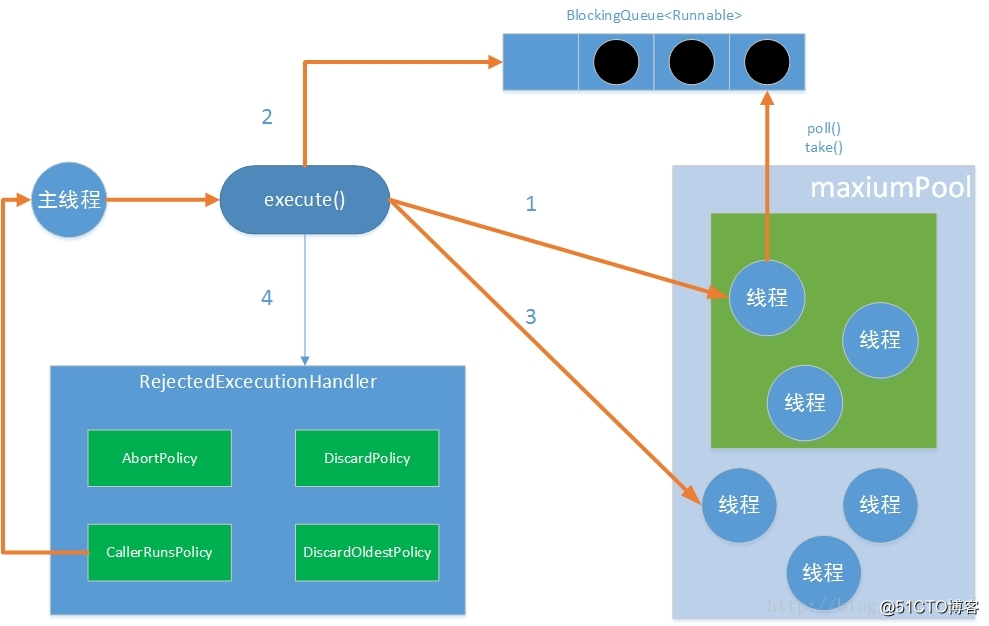
1 如果當前運行的線程少於corePoolSize,則創建新線程來執行任務(需要獲得全局鎖)
3 如果無法將任務加入BlockingQueue(隊列已滿),則創建新的線程來處理任務(需要獲得全局鎖)
4 如果創建新線程將使當前運行的線程超出maxiumPoolSize,任務將被拒絕,並調用RejectedExecutionHandler.rejectedExecution()方法。
線程池采取上述的流程進行設計是為了減少獲取全局鎖的次數。在線程池完成預熱(當前運行的線程數大於或等於corePoolSize)之後,幾乎所有的excute方法調用都執行步驟2。
2 線程池的源碼分析
2.1 定義的幾個變量
private final AtomicInteger ctl = new AtomicInteger(ctlOf(RUNNING, 0)); private static final int COUNT_BITS = Integer.SIZE - 3; private static final int CAPACITY = (1 << COUNT_BITS) - 1; // runState is stored in the high-order bits private static final int RUNNING = -1 << COUNT_BITS; private static final int SHUTDOWN = 0 << COUNT_BITS; private static final int STOP = 1 << COUNT_BITS; private static final int TIDYING = 2 << COUNT_BITS; private static final int TERMINATED = 3 << COUNT_BITS; // Packing and unpacking ctl private static int runStateOf(int c) { return c & ~CAPACITY; } private static int workerCountOf(int c) { return c & CAPACITY; } private static int ctlOf(int rs, int wc) { return rs | wc; }
在分析源碼前有必要理解一個變量ctl。這是Java大神們為了把工作線程數量和線程池狀態放在一個int類型變量裏存儲而設置的一個原子類型的變量。 在ctl中,低位的29位表示工作線程的數量,高位用來表示RUNNING、SHUTDOWN、STOP等狀態。 因此一個線程池的數量也就變成了(2^29)-1,大約500 million,而不是(2^31)-1,2billion。上面定義的三個方法只是為了計算得到線程池的狀態和工作線程的數量。
2.2 Execute 方法提交任務
2.2.1 Execute方法
public void execute(Runnable command) {
//如果提交了空的任務 拋出異常
if (command == null)
throw new NullPointerException();
int c = ctl.get();//獲取當前線程池的狀態
//檢查當前工作線程數量是否小於核心線程數量
if (workerCountOf(c) < corePoolSize) {
//通過addWorker方法提交任務
if (addWorker(command, true))
return;
c = ctl.get();//如果提交失敗 需要二次檢查狀態
}
//向工作線程提交任務
if (isRunning(c) && workQueue.offer(command)) {
// 再次檢查狀態
int recheck = ctl.get();
if (! isRunning(recheck) && remove(command))
reject(command);
else if (workerCountOf(recheck) == 0)
addWorker(null, false);
}
//擴容失敗 則拒絕任務
else if (!addWorker(command, false))
reject(command);
}從源碼中可以看到提交任務的這一過程基本與第二個圖的四個流程是一致的,需要檢查的是當前工作線程的數量與核心線程數量的關系,來決定提交任務的方式或者是拒絕任務提交。而具體任務的提交工作是在addWorker方法中。在這裏面看到了recheck這樣的變量,這是在執行了一些動作失敗後再次檢查線程池的狀態,因為在這期間可能有線程池關閉獲得線程池飽和等狀態的改變。
2.2.2 addWorker方法
這個方法是任務提交的一個核心方法。在裏面完成了狀態檢查、新建任務、執行任務等一系列動作。它有兩個參數,第一個參數是提交的任務,第二個參數是一個標識符,標識在檢查工作線程數量的時候是應該與corePoolSize對比還是應該maximumPoolSize對比。
private boolean addWorker(Runnable firstTask, boolean core) {
retry:
//死循環更新狀態
for (;;) {
int c = ctl.get();
int rs = runStateOf(c);//獲取運行狀態
//檢查線程池是否處於關閉狀態
if (rs >= SHUTDOWN &&
! (rs == SHUTDOWN &&
firstTask == null &&
! workQueue.isEmpty()))
return false;
for (;;) {
//獲取當前工作線程數量
int wc = workerCountOf(c);
//如果已經超過corePoolSize獲取maximumPoolSize 返回false
if (wc >= CAPACITY ||
wc >= (core ? corePoolSize : maximumPoolSize))
return false;
//CAS增加一個工作線程
if (compareAndIncrementWorkerCount(c))
break retry;
//再次獲取狀態
c = ctl.get(); // Re-read ctl
//如果狀態更新失敗 則循環更新
if (runStateOf(c) != rs)
continue retry;
// else CAS failed due to workerCount change; retry inner loop
}
}
boolean workerStarted = false;
boolean workerAdded = false;
Worker w = null;
try {
w = new Worker(firstTask);//初始化一個工作線程
final Thread t = w.thread;
if (t != null) {
//獲得鎖
final ReentrantLock mainLock = this.mainLock;
mainLock.lock();
try {
// Recheck while holding lock.
// Back out on ThreadFactory failure or if
// shut down before lock acquired.
int rs = runStateOf(ctl.get());
if (rs < SHUTDOWN ||
(rs == SHUTDOWN && firstTask == null)) {
if (t.isAlive()) // precheck that t is startable
throw new IllegalThreadStateException();
//添加工作這到hashset中保存
workers.add(w);
int s = workers.size();
if (s > largestPoolSize)
largestPoolSize = s;
workerAdded = true;
}
} finally {
mainLock.unlock();
}
if (workerAdded) {
//工作線程啟動 執行第一個任務 就是新提交的任務
t.start();
workerStarted = true;
}
}
} finally {
if (! workerStarted)
addWorkerFailed(w);
}
return workerStarted;
}這個方法可以分為兩個階段來看,第一個階段是判斷是否有必要新增一個工作線程,如果有則利用CAS更新工作線程的數量;第二部分是將提交的任務封裝成一個工作線程Worker然後加入到線程池的容器中,開始執行新提交的任務。這個Worker在執行完任務後,還會循環地獲取工作隊列裏的任務來執行。下面來看一下Worker的構造方法就能更好地理解上面的代碼了
/**
- Creates with given first task and thread from ThreadFactory.
- @param firstTask the first task (null if none)
*/
Worker(Runnable firstTask) {
setState(-1); // inhibit interrupts until runWorker
this.firstTask = firstTask;
this.thread = getThreadFactory().newThread(this);
}
2.2.3?runWorker方法
在addWorker方法快要結束的地方,調用了t.start()方法,我們知道它實際執行的就是Worker對象的run()方法,而worker的run()方法是這樣定義的:
/* Delegates main run loop to outer runWorker /
public void run() {
runWorker(this);
}
它實際上是將自己委托給線程池的runWorker方法
final void runWorker(Worker w) {
Thread wt = Thread.currentThread();
Runnable task = w.firstTask;
w.firstTask = null;
w.unlock(); // allow interrupts
boolean completedAbruptly = true;
try {
//不斷地從blockingQueue獲取任務
while (task != null || (task = getTask()) != null) {
w.lock();
// If pool is stopping, ensure thread is interrupted;
// if not, ensure thread is not interrupted. This
// requires a recheck in second case to deal with
// shutdownNow race while clearing interrupt
if ((runStateAtLeast(ctl.get(), STOP) ||
(Thread.interrupted() &&
runStateAtLeast(ctl.get(), STOP))) &&
!wt.isInterrupted())
wt.interrupt();
try {
//執行beforeExecute方法
beforeExecute(wt, task);
Throwable thrown = null;
try {
//調用Runable的run方法
task.run();
} catch (RuntimeException x) {
thrown = x; throw x;
} catch (Error x) {
thrown = x; throw x;
} catch (Throwable x) {
thrown = x; throw new Error(x);
} finally {
// 執行aferExecute方法
afterExecute(task, thrown);
}
} finally {
task = null;
w.completedTasks++;
w.unlock();
}
}
completedAbruptly = false;
} finally {
processWorkerExit(w, completedAbruptly);
}
}這個方法呢也比較好理解,它在不斷執行我們提交的任務的run方法。而這個任務可能是我們新提交的,也有可能是從等待隊列中獲取的。這樣就實現了線程池的完成邏輯。
Java中的線程池——ThreadPoolExecutor的原理