
一個簡單的pingpong程式測試mpi訊息通訊的開銷
阿新 • • 發佈:2018-10-31
一個簡單的pingpong程式測試mpi訊息通訊的開銷
隨著科技的進步,叢集單節點計算能力的提高,似乎通訊開銷成了平行計算中dominant,再提高計算能力對於並行的增益似乎效果不明顯,限制性能的瓶頸從處理器計算能力上轉移到通訊開銷上。顯然,此時設法降低MPI訊息通訊帶來的時間消耗,成為了當務之急。
因此,寫了一個極其簡單的pingpong並行程式來測試訊息通訊帶來的開銷。
基本思想
所謂的pingpong,顧名思義就是找一個數據包不斷地在兩個節點之間丟來丟去,想打乒乓球一樣。
我們在程式中定義兩重迴圈,外重迴圈定義資料量大小,從1kb到100m,漲幅為100kb,內層迴圈對於每一固定大小的資料跑100個來回,最後取平均值,作為這個大小的資料的傳輸時間。最後,以資料量大小為橫軸,時間為縱軸,plot一下。
準備工作
我們連線了機房的兩臺電腦,作為實驗環境。主要設定了SSH免密登入和NFS共享目錄。
一個簡單的程式碼如下:
/** * pingpong程式,用於測試點點傳送的速度 */ //32位系統中,一個int佔4B(sizeof(int)),1KB=250int,1M=250000int //1M=1000kb,100M = 10e5kb #include <stdio.h> #include <stdlib.h> #include <mpi.h> //#define N 4 //外層迴圈資料量大小改變,使用動態陣列來實現 #define m 100 #define debugflag 0 int main (int argc, char *argv[]) { int myrank,i,nprocs; double pingpongSize,aver_tcost,total_t,Ts[m]; double st, et, time_cost; int N; int *pingpong; MPI_Init(&argc, &argv);//初始化MPI環境 MPI_Comm_size(MPI_COMM_WORLD, &nprocs);//獲取總程序數 MPI_Comm_rank (MPI_COMM_WORLD, &myrank);//獲取本地程序編號 MPI_Status status; //int opposite_rank; opposite_rank = (myrank == 0) ? (1) : (0); // for(N=1; N<=1e4; N=N+1e3) { for(N=1; N<=1e5; N=N+1e2){ total_t = 0.0; pingpong = (int*)malloc( N*1000); if(!pingpong) { printf("建立pingpong失敗!\n"); exit(1); } // int pingpong[N] = {0};//隨便賦值 for(i=0;i<N;i++) { pingpong[i] = 999; // printf("%d,%d",i,pingpong[i]); } // pingpong[0] = 999; if(myrank==0) { printf("開始 %dkb/1e5kb 資料傳送……\n",N); } for(i=0; i<m; i++) { st = MPI_Wtime(); if(myrank==0) { MPI_Send (pingpong, N, MPI_INT, 1, i, MPI_COMM_WORLD); #if debugflag printf("第%d回合:%d傳送資料完成……\n",i+1,myrank); #endif } if(myrank==1) { MPI_Recv (pingpong, N, MPI_INT, 0, i, MPI_COMM_WORLD, &status); MPI_Send (pingpong, N, MPI_INT, 0, i, MPI_COMM_WORLD); #if debugflag printf("第%d回合:%d接收和傳送資料完成……\n",i+1,myrank); #endif } if(myrank==0) { MPI_Recv (pingpong, N, MPI_INT, 1, i, MPI_COMM_WORLD, &status); #if debugflag printf("第%d回合:%d接收資料完成……\n",i+1,myrank); printf("第%d回合succeed! The time of cost is %lf\n\n",i+1,time_cost); // printf("一個int佔用:%ld B",sizeof(myrank)); #endif } et = MPI_Wtime(); time_cost = et-st; total_t = total_t+time_cost; Ts[i] = time_cost; } aver_tcost = total_t/m; pingpongSize = N/1e3; // printf("%d個int的資料量大小為%lf M!\n",N,pingpongSize); FILE *fp; fp=fopen("data.txt","a+"); fprintf(fp,"%lf,%lf\n",pingpongSize,aver_tcost); fclose(fp); free(pingpong); if(myrank == 0){ printf("%lfM 資料包傳送接收回合完成……\n",pingpongSize); printf("%dkb 的資料量的傳送時間平均時間為: %lf \n\n",N,aver_tcost); } } MPI_Finalize ();//結束MPI環境 return 0; }
實驗和結果
這個實驗結果,其實心裡有點虛,因為跑100M的資料,時間卻不到0.01s,這個速度讓我懷疑我哪裡出問題了。一個可能是造資料造得不對,還有一個可能是訊息傳遞的時候出問題了。
Anyway,先將結果畫一下圖,如下:
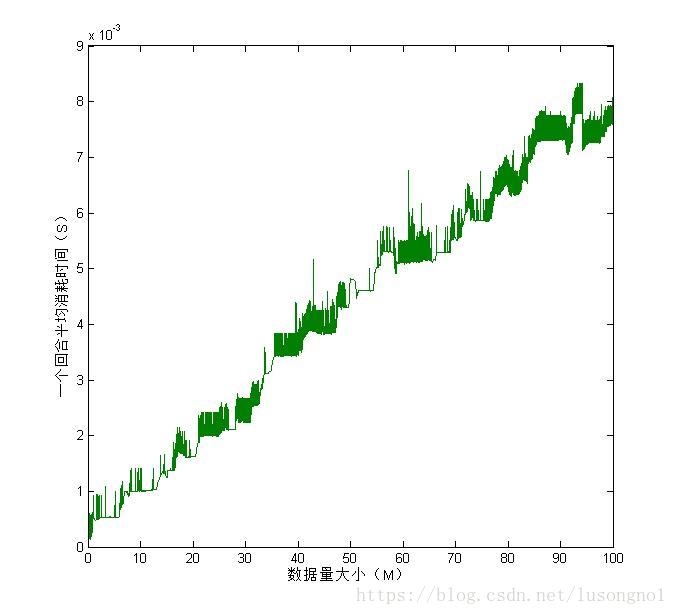
從結果上可以看到,通訊開銷隨著資料量大小呈現一個“區域性震盪,整體近似線性增長”的關係,我們可以很容易地用線性函式去做線性fit,得到了T = 7.79e-5X+0.00041這個這樣一個關係,可靠程度:誤差平方和為0.0001721,均方根誤差為0.000333,確定係數約為0.9787。這裡的確定係數已經很接近1了,說明這個擬合是很可靠的。
分析一波這個擬合結果,我們大概能知道每增加100m的資料,大概需要增加7.8ms,快得令人難以置信,這也是我懷疑我的結果的原因。錯歸錯,時間寶貴,總不能將青春都浪費在debug上面。