
Elasticsearch介紹和安裝與使用
1.Elasticsearch介紹和安裝
1.1.簡介
1.1.1.Elastic
Elastic官網:https://www.elastic.co/cn/
Elastic有一條完整的產品線:Elasticsearch、Kibana、Logstash等,前面說的三個就是大家常說的ELK技術棧。

1.1.2.Elasticsearch
Elasticsearch官網:https://www.elastic.co/cn/products/elasticsearch

如上所述,Elasticsearch具備以下特點:
- 分散式,無需人工搭建叢集(solr就需要人為配置,使用Zookeeper作為註冊中心)
- Restful風格,一切API都遵循Rest原則,容易上手
- 近實時搜尋,資料更新在Elasticsearch中幾乎是完全同步的。
1.1.3.版本
目前Elasticsearch最新的版本是6.2.4,我們就使用這個版本
需要JDK1.8及以上
1.2.安裝和配置
###1.2.1 下載
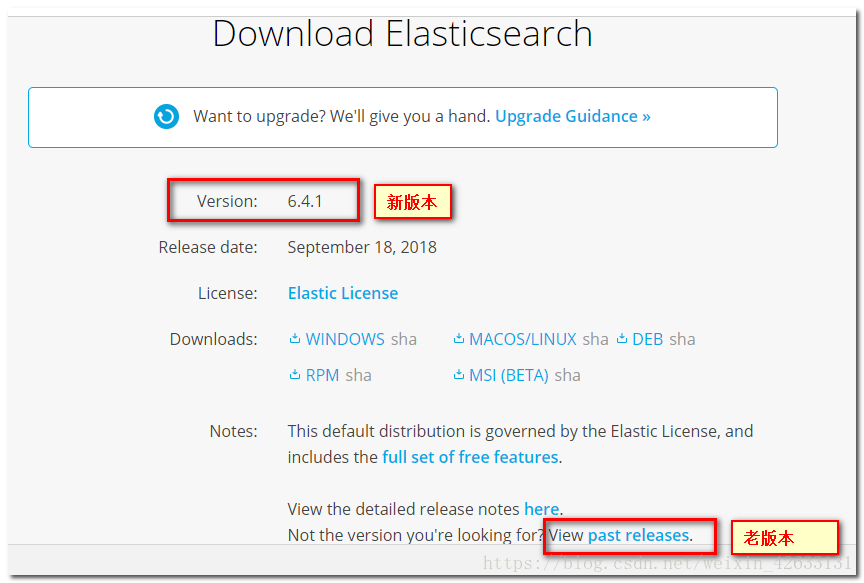
下載地址:https://www.elastic.co/downloads/past-releases
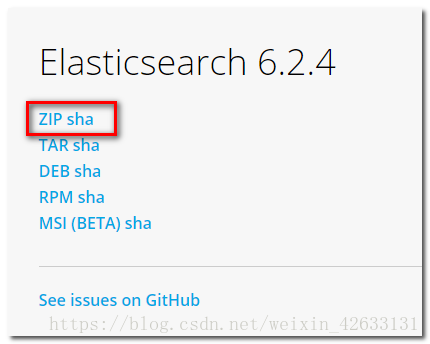
1.2.2 安裝
elasticsearch無需安裝,解壓即用。

1.3.執行
進入elasticsearch/bin目錄,可以看到下面的執行檔案:
雙擊執行
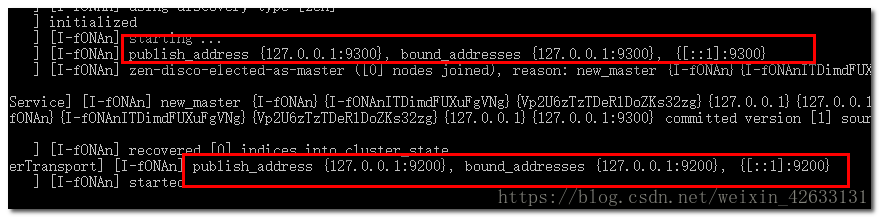
可以看到綁定了兩個埠:
- 9300:java程式訪問的斷就
- 9200:瀏覽器、postman訪問介面
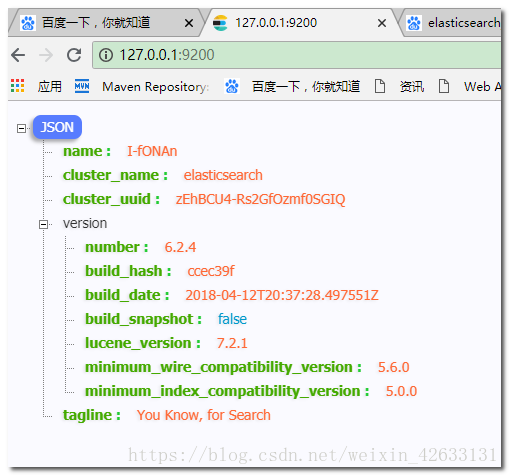
我們在瀏覽器中訪問:http://127.0.0.1:9200
1.4.安裝Head外掛
1.4.1.什麼是Head
ealsticsearch只是後端提供各種api,那麼怎麼直觀的使用它呢?elasticsearch-head將是一款專門針對於elasticsearch的客戶端工具
elasticsearch-head配置包,下載地址:https://github.com/mobz/elasticsearch-head
1.4.2.安裝
- es5以上版本安裝head需要安裝node和grunt
第一步:從地址:https://nodejs.org/en/download/ 下載相應系統的msi,雙擊安裝。
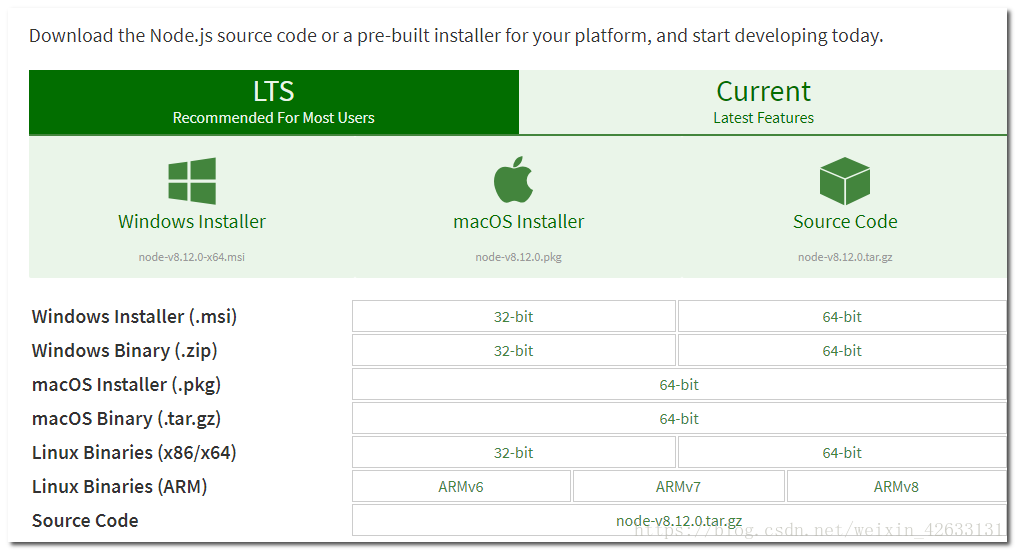
第二步:安裝完成用cmd進入安裝目錄執行 node -v可檢視版本號
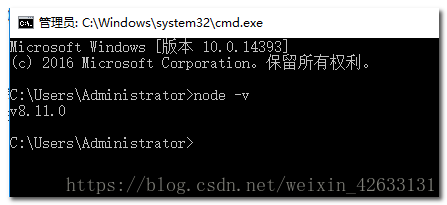
第三步:執行 npm install -g grunt-cli 安裝grunt ,安裝完成後執行grunt -version檢視是否安裝成功,會顯示安裝的版本號
1.4.3.配置執行
第一步:進入es安裝目錄下的config目錄,修改elasticsearch.yml檔案.在檔案的末尾加入以下程式碼
http.cors.enabled: true
http.cors.allow-origin: "*"
node.master: true
node.data: true
然後去掉network.host: 192.168.0.1的註釋並改為network.host: 0.0.0.0,去掉cluster.name;node.name;http.port的註釋(也就是去掉#)(!!!如果出現bat閃退的現象,註釋就別去掉)
第二步:雙擊elasticsearch.bat重啟es
第三步:在https://github.com/mobz/elasticsearch-head中下載head外掛,選擇下載zip
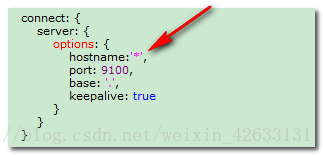
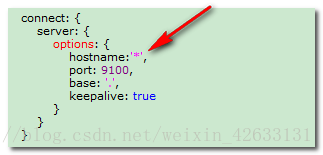
第四步:解壓到指定資料夾下,D:\environment\elasticsearch-head-master 進入該資料夾,修改D:\environment\elasticsearch-head-master\Gruntfile.js 在對應的位置加上hostname:’*’、
第五步:在D:\environment\elasticsearch-head-master 下執行npm install 安裝完成後執行grunt server 或者npm run start 執行head外掛,如果不成功重新安裝grunt。成功如下
1.4.4.成功
1.5.安裝ik分詞器
ElasticSearch 預設採用分詞器, 單個字分詞 ,效果很差
搜尋【IK Analyzer 3.0】
http://www.oschina.net/news/2660
Lucene的IK分詞器早在2012年已經沒有維護了,現在我們要使用的是在其基礎上維護升級的版本,並且開發為Elasticsearch的整合外掛了,與Elasticsearch一起維護升級,版本也保持一致,最新版本:6.2.4

1.5.1. 下載
原始碼下載地址:https://github.com/medcl/elasticsearch-analysis-ik/tree/6.2.x
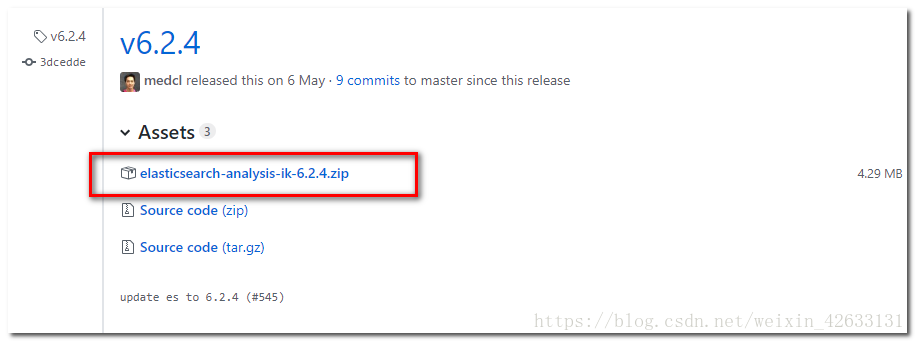
jar包下載地址:https://github.com/medcl/elasticsearch-analysis-ik/releases

1.5.1.安裝
無需安裝,解壓即可使用
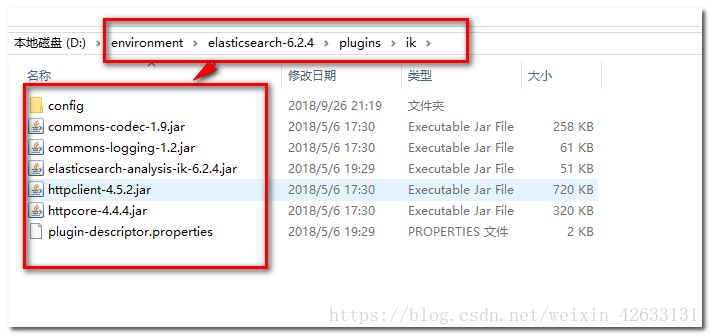
我們將其改名為ik,並複製到elasticsearch的解壓目錄,如下圖所示
然後重啟elasticsearch:
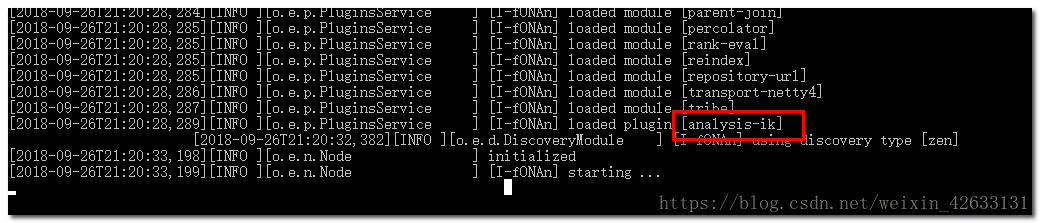
1.5.2.擴充套件詞和停用詞
擴充套件詞和停用詞檔案:
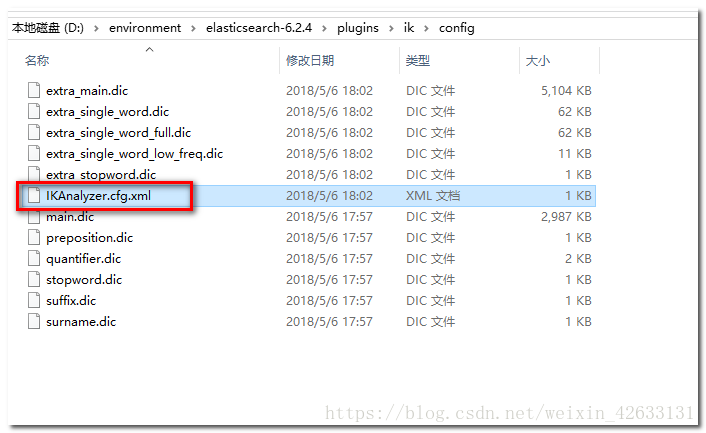

###1.5.4 測試
2.SprignBoot整合Spring Data Elasticsearch
Elasticsearch提供的Java客戶端有一些不太方便的地方:
- 很多地方需要拼接Json字串,在java中拼接字串有多恐怖你應該懂的
- 需要自己把物件序列化為json儲存
- 查詢到結果也需要自己反序列化為物件
因此,我們這裡就不講解原生的Elasticsearch客戶端API了。
而是學習Spring提供的套件:Spring Data Elasticsearch
2.1.簡介
Spring Data Elasticsearch是Spring Data專案下的一個子模組。
檢視 Spring Data的官網:http://projects.spring.io/spring-data/
Spring Data 是的使命是給各種資料訪問提供統一的程式設計介面,不管是關係型資料庫(如MySQL),還是非關係資料庫(如Redis),或者類似Elasticsearch這樣的索引資料庫。從而簡化開發人員的程式碼,提高開發效率。
包含很多不同資料操作的模組:

Spring Data Elasticsearch的頁面:https://projects.spring.io/spring-data-elasticsearch/
特徵:

- 支援Spring的基於
@Configuration的java配置方式,或者XML配置方式 - 提供了用於操作ES的便捷工具類**
ElasticsearchTemplate**。包括實現文件到POJO之間的自動智慧對映。 - 利用Spring的資料轉換服務實現的功能豐富的物件對映
- 基於註解的元資料對映方式,而且可擴充套件以支援更多不同的資料格式
- 根據持久層介面自動生成對應實現方法,無需人工編寫基本操作程式碼(類似mybatis,根據介面自動得到實現)。當然,也支援人工定製查詢
2.2.建立Demo工程
我們新建一個demo,學習Elasticsearch
pom依賴:
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0" xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.czxy</groupId>
<artifactId>bos-es</artifactId>
<version>0.0.1-SNAPSHOT</version>
<packaging>jar</packaging>
<name>bos-es</name>
<description>Demo project for Spring Boot</description>
<parent>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-parent</artifactId>
<version>2.0.4.RELEASE</version>
<relativePath/> <!-- lookup parent from repository -->
</parent>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<project.reporting.outputEncoding>UTF-8</project.reporting.outputEncoding>
<java.version>1.8</java.version>
</properties>
<dependencies>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-elasticsearch</artifactId>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-maven-plugin</artifactId>
</plugin>
</plugins>
</build>
</project>
application.properties檔案配置:
spring.data.elasticsearch.repositories.enabled = true
spring.data.elasticsearch.cluster-nodes =127.0.0.1:9300
2.3.索引操作
2.3.1.建立索引和對映
SpringBoot-data-elasticsearch提供了面向物件的方式操作elasticsearch
業務:建立一個商品物件,有這些屬性:
答:id,title,category,brand,price,圖片地址
在SpringDataElasticSearch中,只需要操作物件,就可以操作elasticsearch中的資料
實體類
首先我們準備好實體類:
public class Item {
private Long id;
private String title; //標題
private String category;// 分類
private String brand; // 品牌
private Double price; // 價格
private String images; // 圖片地址
}
對映—註解
Spring Data通過註解來宣告欄位的對映屬性,有下面的三個註解:
@Document作用在類,標記實體類為文件物件,一般有兩個屬性- indexName:對應索引庫名稱
- type:對應在索引庫中的型別
- shards:分片數量,預設5
- replicas:副本數量,預設1
@Id作用在成員變數,標記一個欄位作為id主鍵@Field作用在成員變數,標記為文件的欄位,並指定欄位對映屬性:- type:欄位型別,是是列舉:FieldType,可以是text、long、short、date、integer、object等
- text:儲存資料時候,會自動分詞,並生成索引
- keyword:儲存資料時候,不會分詞建立索引
- Numerical:數值型別,分兩類
- 基本資料型別:long、interger、short、byte、double、float、half_float
- 浮點數的高精度型別:scaled_float
- 需要指定一個精度因子,比如10或100。elasticsearch會把真實值乘以這個因子後儲存,取出時再還原。
- Date:日期型別
- elasticsearch可以對日期格式化為字串儲存,但是建議我們儲存為毫秒值,儲存為long,節省空間。
- index:是否索引,布林型別,預設是true
- store:是否儲存,布林型別,預設是false
- analyzer:分詞器名稱,這裡的
ik_max_word即使用ik分詞器
- type:欄位型別,是是列舉:FieldType,可以是text、long、short、date、integer、object等
示例:
@Document(indexName = "item",type = "docs", shards = 1, replicas = 0)
public class Item {
@Id
private Long id;
@Field(type = FieldType.Text, analyzer = "ik_max_word")
private String title; //標題
@Field(type = FieldType.Keyword)
private String category;// 分類
@Field(type = FieldType.Keyword)
private String brand; // 品牌
@Field(type = FieldType.Double)
private Double price; // 價格
@Field(index = false, type = FieldType.Keyword)
private String images; // 圖片地址
}
建立索引
ElasticsearchTemplate中提供了建立索引的API:
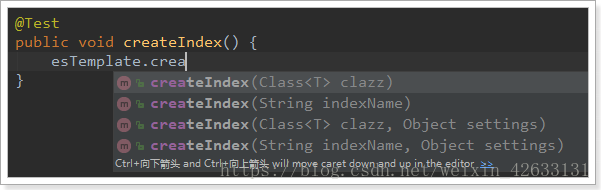
- 可以根據類的資訊自動生成,也可以手動指定indexName和Settings
對映
對映相關的API:
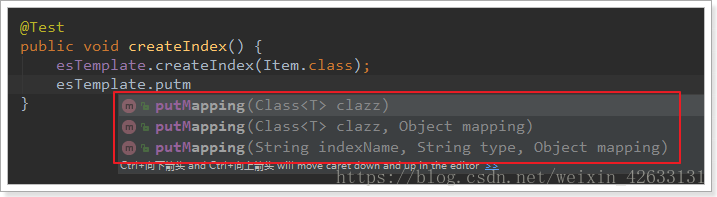
- 一樣,可以根據類的位元組碼資訊(註解配置)來生成對映,或者手動編寫對映
我們這裡採用類的位元組碼資訊建立索引並對映:
@Test
public void createIndex() {
// 建立索引,會根據Item類的@Document註解資訊來建立
esTemplate.createIndex(Item.class);
// 配置對映,會根據Item類中的id、Field等欄位來自動完成對映
esTemplate.putMapping(Item.class);
}
索引資訊:

2.3.2.刪除索引
刪除索引的API:
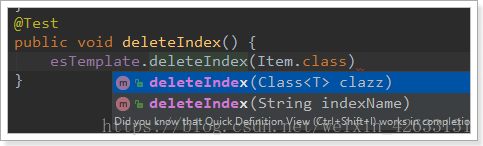
可以根據類名或索引名刪除。
示例:
@Test
public void deleteIndex() {
esTemplate.deleteIndex(Item.class);
// 根據索引名字刪除
//esTemplate.deleteIndex("item1");
}
結果:OK
2.4.新增文件資料
2.4.1.Repository介面
Spring Data 的強大之處,就在於你不用寫任何DAO處理,自動根據方法名或類的資訊進行CRUD操作。只要你定義一個介面,然後繼承Repository提供的一些子介面,就能具備各種基本的CRUD功能。
來看下Repository的繼承關係:
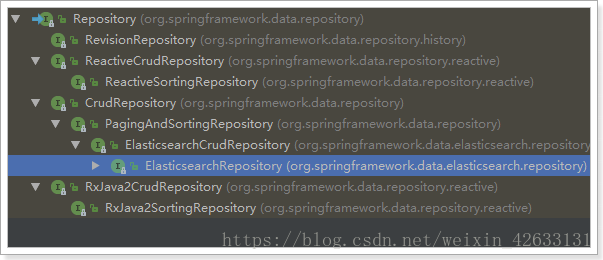
我們看到有一個ElasticsearchCrudRepository介面:
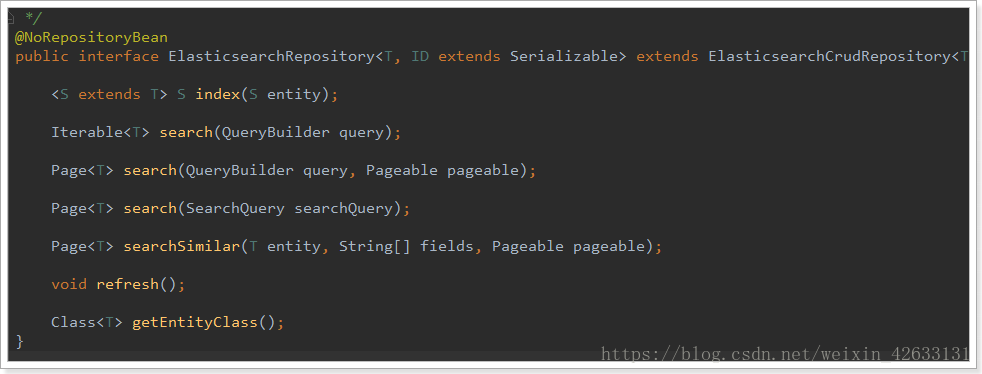
所以,我們只需要定義介面,然後繼承它就OK了。
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
}
接下來,我們測試新增資料:
2.4.2.新增一個物件
@Autowired
private ItemRepository itemRepository;
@Test
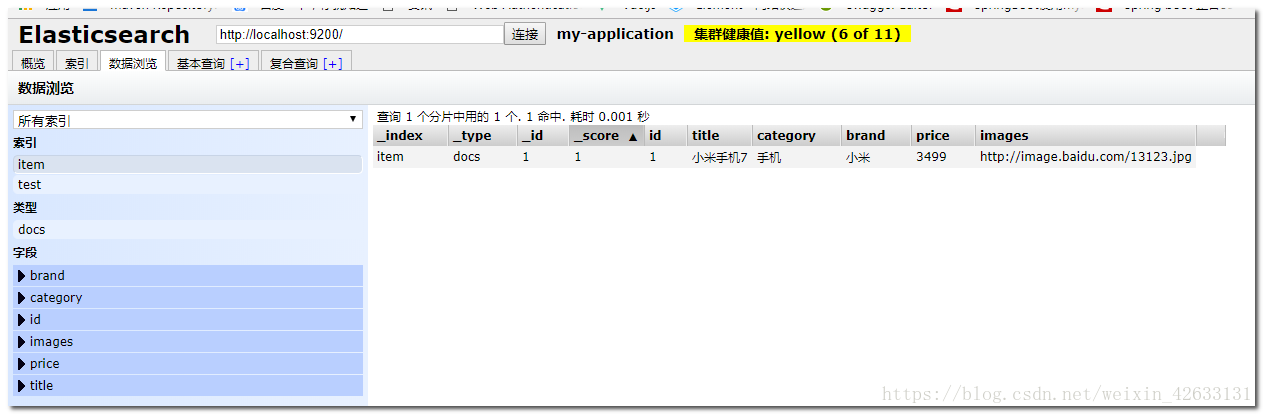
public void index() {
Item item = new Item(1L, "小米手機7", " 手機",
"小米", 3499.00, "http://image.baidu.com/13123.jpg");
itemRepository.save(item);
}
去頁面查詢看看:
2.4.3.批量新增
程式碼:
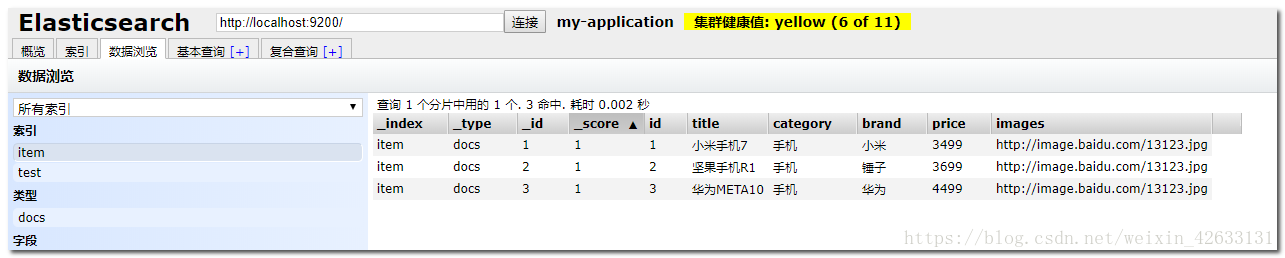
@Test
public void indexList() {
List<Item> list = new ArrayList<>();
list.add(new Item(2L, "堅果手機R1", " 手機", "錘子", 3699.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(3L, "華為META10", " 手機", "華為", 4499.00, "http://image.baidu.com/13123.jpg"));
// 接收物件集合,實現批量新增
itemRepository.saveAll(list);
}
再次去頁面查詢:
2.4.4.修改
elasticsearch中本沒有修改,它的是該是先刪除在新增
修改和新增是同一個介面,區分的依據就是id。
@Test
public void index(){
Item item = new Item(1L, "蘋果XSMax", " 手機",
"小米", 3499.00, "http://image.baidu.com/13123.jpg");
itemRepository.save(item);
}
檢視結果:

2.5.查詢
2.5.1.基本查詢
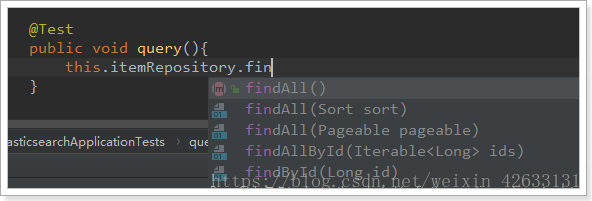
ElasticsearchRepository提供了一些基本的查詢方法:
@Test
public void testQueryAll(){
// 查詢所有
//Iterable<Item> list = this.itemRepository.findAll();
// 對某欄位排序查詢所有 Sort.by("price").descending() 降序
// Sort.by("price").ascending():升序
Iterable<Item> list = this.itemRepository.findAll(Sort.by("price").ascending());
for (Item item:list){
System.out.println(item);
}
}
結果:

2.5.2.自定義方法
Spring Data 的另一個強大功能,是根據方法名稱自動實現功能。
比如:你的方法名叫做:findByTitle,那麼它就知道你是根據title查詢,然後自動幫你完成,無需寫實現類。
當然,方法名稱要符合一定的約定:
| Keyword | Sample |
|---|---|
And |
findByNameAndPrice |
Or |
findByNameOrPrice |
Is |
findByName |
Not |
findByNameNot |
Between |
findByPriceBetween |
LessThanEqual |
findByPriceLessThan |
GreaterThanEqual |
findByPriceGreaterThan |
Before |
findByPriceBefore |
After |
findByPriceAfter |
Like |
findByNameLike |
StartingWith |
findByNameStartingWith |
EndingWith |
findByNameEndingWith |
Contains/Containing |
findByNameContaining |
In |
findByNameIn(Collection<String>names) |
NotIn |
findByNameNotIn(Collection<String>names) |
Near |
findByStoreNear |
True |
findByAvailableTrue |
False |
findByAvailableFalse |
OrderBy |
findByAvailableTrueOrderByNameDesc |
例如,我們來按照價格區間查詢,定義這樣的一個方法:
public interface ItemRepository extends ElasticsearchRepository<Item,Long> {
/**
* 根據價格區間查詢
* @param price1
* @param price2
* @return
*/
List<Item> findByPriceBetween(double price1, double price2);
}
然後新增一些測試資料:
@Test
public void indexList() {
List<Item> list = new ArrayList<>();
list.add(new Item(1L, "小米手機7", "手機", "小米", 3299.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(2L, "堅果手機R1", "手機", "錘子", 3699.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(3L, "華為META10", "手機", "華為", 4499.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(4L, "小米Mix2S", "手機", "小米", 4299.00, "http://image.baidu.com/13123.jpg"));
list.add(new Item(5L, "榮耀V10", "手機", "華為", 2799.00, "http://image.baidu.com/13123.jpg"));
// 接收物件集合,實現批量新增
itemRepository.saveAll(list);
}
不需要寫實現類,然後我們直接去執行:
@Test
public void queryByPriceBetween(){
List<Item> list = this.itemRepository.findByPriceBetween(2000.00, 3500.00);
for (Item item : list) {
System.out.println("item = " + item);
}
}
結果:

2.5.3.自定義查詢
先來看最基本的match query:
@Test
public void search(){
// 構建查詢條件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 新增基本分詞查詢
queryBuilder.withQuery(QueryBuilders.matchQuery("title", "小米手機"));
// 搜尋,獲取結果
Page<Item> items = this.itemRepository.search(queryBuilder.build());
// 總條數
long total = items.getTotalElements();
System.out.println("total = " + total);
for (Item item : items) {
System.out.println(item);
}
}
-
NativeSearchQueryBuilder:Spring提供的一個查詢條件構建器,幫助構建json格式的請求體
-
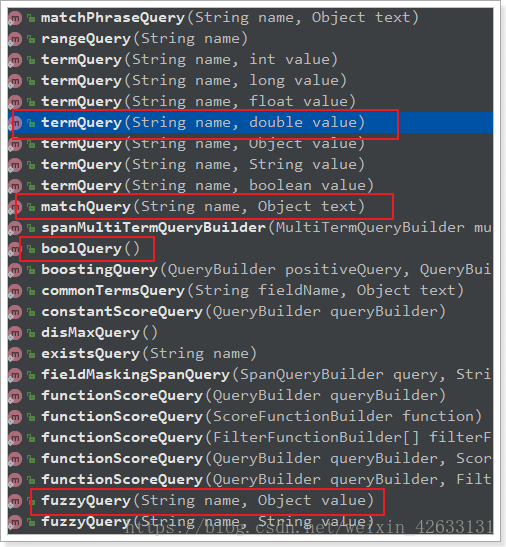
QueryBuilders.matchQuery(“title”, “小米手機”):利用QueryBuilders來生成一個查詢。QueryBuilders提供了大量的靜態方法,用於生成各種不同型別的查詢:
-
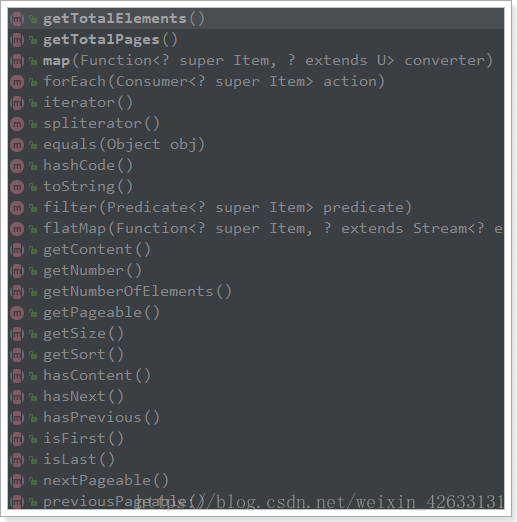
Page<item>:預設是分頁查詢,因此返回的是一個分頁的結果物件,包含屬性:-
totalElements:總條數
-
totalPages:總頁數
-
Iterator:迭代器,本身實現了Iterator介面,因此可直接迭代得到當前頁的資料
-
其它屬性:
-
結果:

總的測試程式碼:
/**
*
* termQuery
* wildcardQuery
* fuzzyquery
* booleanQuery
* numericRangeQuery
*
*/
@Test
public void testMathQuery(){
// 建立物件
NativeSearchQueryBuilder queryBuilder = new NativeSearchQueryBuilder();
// 在queryBuilder物件中自定義查詢
//matchQuery:底層就是使用的termQuery
queryBuilder.withQuery(QueryBuilders.matchQuery("title"
相關推薦
Elasticsearch介紹和安裝與使用
1.Elasticsearch介紹和安裝
1.1.簡介
1.1.1.Elastic
Elastic官網:https://www.elastic.co/cn/
Elastic有一條完整的產品線:Elasticsearch、Kibana、Logstash等,前面說的三
[Success]Elasticsearch介紹和安裝+ik
一.Elasticsearch介紹和安裝
SprignBoot整合Spring Data Elasticsearch 以及使用
1.1.簡介
1.1.1.Elastic
Elastic官網:https://www.elastic.co/cn/
Elastic有
Elasticsearch介紹和安裝
Elasticsearch
1.簡介
1.1基本概念
1.2.Elastic
1.3 Elasticsearch
1.4 版本
1.2.安裝和配置
1.2.1 下載
ElasticSearch 外掛之Kibana的介紹和安裝
1.解壓kibana-6.5.3-linux-x86_64.tar.gz tar -zxvf kibana-6.5.3-linux-x86_64.tar.gz 2.進入解壓後的目錄的config中,修改.yml檔案 server.port: 5601 server.host: “hadoop
ElasticSearch 外掛之head的介紹和安裝
簡介
ElasticSearch-head是一個ElasticSearch的叢集管理工具,它是完全由HTML5編寫的獨立網頁程式,可以通過外掛把它整合ES.
安裝
注意:先解壓壓縮包 elasticsearch-head-master.zip unzip elasticsearc
ElasticSearch 外掛之bigdesk的介紹和安裝
Bigdesk: 1)主要提供的是節點的實時狀態監控,,包括JVM的情況,linux的情況,Elasticsearch的情況。 2)裡面可以看到叢集名稱,節點列表。記憶體消耗情況,GC回收情況。可以自由的在各個節點之間進行切換,自動的新增或是移除一些舊的節點,同樣可以更改refresh in
ElasticSearch實戰系列九: ELK日誌系統介紹和安裝
## 前言
本文主要介紹的是ELK日誌系統入門和使用教程。
## ELK介紹
ELK是三個開源軟體的縮寫,分別表示:Elasticsearch , Logstash, Kibana , 它們都是開源軟體。新增了一個FileBeat,它是一個輕量級的日誌收集處理工具(Agent),Filebeat佔用資源少
(一)elasticsearch-5.x安裝與配置
head(一)平臺所需的環境OS:CentOS 7.x minimalelasticsearch :elasticsearch-5.4.0版本jdk: 1.8已上版本創建普通用戶:appuser最新的下載路徑地址為:https://www.elastic.co/downloads (二)配置操作系統的環境並
Redis 實踐1- redis介紹和安裝
部分 rdb eve devel 請求 /dev/ 兩種 gcc replay redis是一個key-value存儲系統,官方站點 http://redis.io
和memcached類似,但支持數據持久化
支持更多value類型,除了和string外,還支持hash
2017.8.30 elasticsearch-sql的安裝與使用
elastics 一個 es2017 畫面 方法 方便 127.0.0.1 使用 font 參考來自:
http://blog.csdn.net/u012307002/article/details/52837756
https://github.com/NLPchi
Tomca軟件介紹和安裝
blog 資源 common justify 用戶 sphere orace ren shutdown
Web開發入門
軟件的結構:
C/S (Client - Server 客戶端-服務器端)
典型應用:QQ軟件 ,飛秋,紅蜘蛛。
特點:
1)必須下載特定的客
高性能集群軟件Keepalived的介紹以及安裝與配置
linux 集群 keepalived Keepalived介紹: Keepalived是Linux下一個輕量級的高可用解決方案;起初是為LVS設計的,專門用來監控集群系統中各個服務節點的狀態。它根據TCP/IP參考模型的第三、第四和第五層交換機機制檢測每個服務節點的狀態,如果
Elasticsearch簡介和安裝對比
特殊 字段 tree apache 查看 端口 blog work 分布式搜索 各位小夥伴,又到了本期分享大數據技術的時間,本次給大夥帶來的是Elasticsearch這個技術,閑話不多聊,我們開始進入正題。
一、什麽是elasticsearch
Elasticsearc
(一)Fiddler的介紹和安裝
chm 瀏覽器中 tool nec clas 技術分享 strong HR str 一、Fiddler的介紹和安裝
Fildder是一款免費的web調試代理工具,支持任何瀏覽器、系統或平臺。
官網地址:https://www.telerik.com/fiddler
Fidd
002 activemq的介紹和安裝
就是 放心 我們 一個 企業級 簡單的 activemq 幫助 成了
一 .Activemq介紹
JMS是一個規範,其中Activemq就是一個非常不錯的JMS實現,知道這些就已經足夠了.
我們使用Activemq就是想使用企業級的消息使用.
總的來說Activemq不
Docker系列一:Docker的介紹和安裝
實驗 start ner min docker-ce 周期 com set 自動化測試 Docker介紹
Docker是指容器化技術,用於支持創建和實驗Linux Container。借助Docker,你可以將容器當做重量輕、模塊化的虛擬機來使用,同時,你還將獲得高度的靈活
tomcat介紹和安裝
tcp 程序 個人 aux tcp6 end ext 訪問 ces tomcat介紹tomcat是apache軟件基金會(Apache Softeare Foundation )的jakarta項目中的一個核心項目,由apache、sun和其他的公司和個人共同開發而成jav
Kafka系列一之架構介紹和安裝
環境 指南 ont fcm port 架構 star cfg 自己的 Kafka架構介紹和安裝
寫在前面
還是那句話,當你學習一個新的東西之前,你總得知道這個東西是什麽?這個東西可以用來做什麽?然後你才會去學習它,使用它。簡單來說,kafka既是一個消息隊列,如今,它也演變
SDN控制器之OVN實驗一:介紹和安裝OVN
OVN概覽
OVN是由開發出OVS的那群出色的程式設計師們的另一個優秀的作品。這個網路虛擬化專案從2015初宣告啟動,到不久前才釋出第一個正式版本OVN 2.6 。在這篇文章中,我會配置一個簡單示例:在三個主機之間配置一個layer-2 overlay網路。
首先講一下OVN工作機制中的2種
Git介紹和安裝
Git 是什麼
Git 是 Linus Torvalds 為了幫助管理 Linux 核心開發而開發的一個開放原始碼的分散式版本控制系統。
與常用的版本控制工具 CVS, Subversion 等不同,它採用了分散式版本庫的方式,不必伺服器端軟體支援(注:這得分是用什麼樣的服務端,使用http協議或者git