
【Caffe學習01】在Caffe中trian MNIST
在上次搭建好Caffe環境的基礎上我們進行第一次實驗,將Caffe自帶的一個Mnist example跑一跑,對其在處理影象方面的能力有個初步瞭解。
如果還沒有搭建好環境的朋友可以看看我的上一篇文章:
http://blog.csdn.net/AkashaicRecorder/article/details/71016942
MNIST簡介
MNIST手寫數字資料庫是另外一個更大的手寫體資料庫NIST的子集,現在已成為影象識別領域用來測試自己的演算法的一個基準資料庫,它的訓練集由60000張手寫數字圖片樣本組成,測試集包含了10000個樣本,其中所有的圖片樣本都經過了尺寸標準化和中心化,圖片的大小固定為28*28。對於想要在實際資料上學習技巧和學習模式識別方法的人來說,這是一個很好的資料庫,同時減少了人們在對素材進行預處理和格式化方面花費的時間。
以下是官網原文的描述:
The MNIST database of handwritten digits, available from this page, has a training set of 60,000 examples, and a test set of 10,000 examples. It is a subset of a larger set available from NIST. The digits have been size-normalized and centered in a fixed-size image.
It is a good database for people who want to try learning techniques and pattern recognition methods on real-world data while spending minimal efforts on preprocessing and formatting.
官網地址,你可以在這裡下載用於訓練的資料集:
http://yann.lecun.com/exdb/mnist/
生成需要的檔案及使用訓練好的模型進行識別
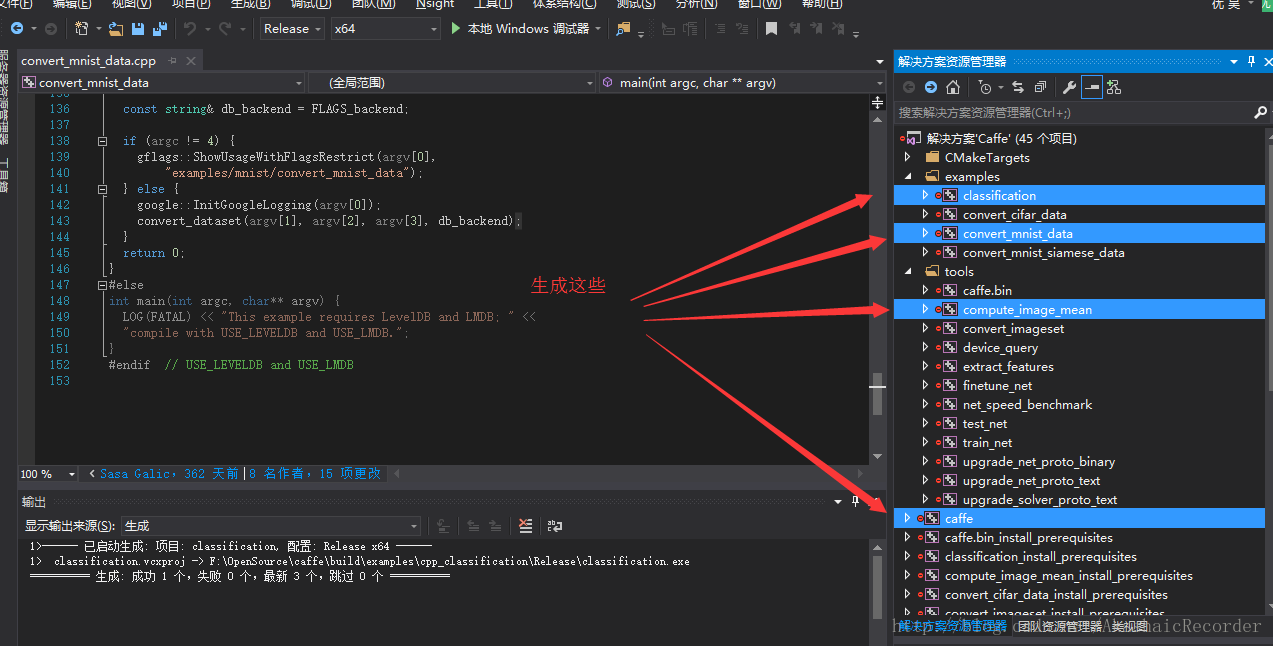
1.要使用這個訓練集,你需要編譯以下幾個專案並使用它們生產的exe
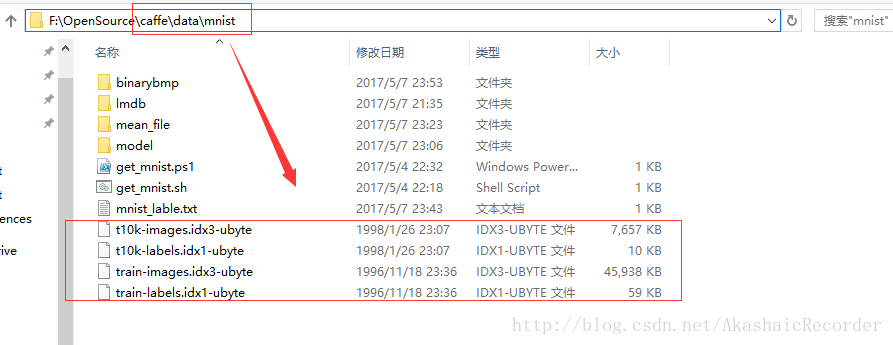
2.將之前在minist官網下載好的訓練集解壓並放到指定目錄下,
注意一定要放到你caffe工程的data\minist目錄下,不然後面會執行檔案報錯
(PS:由於我們是windows系統執行不了get_mnist.sh這個shell檔案,直接去官網下載包放到指定目錄可以達到相同的效果)

3.在..\caffe\build\examples\mnist目錄下新建bat資料夾並建立如下bat檔案
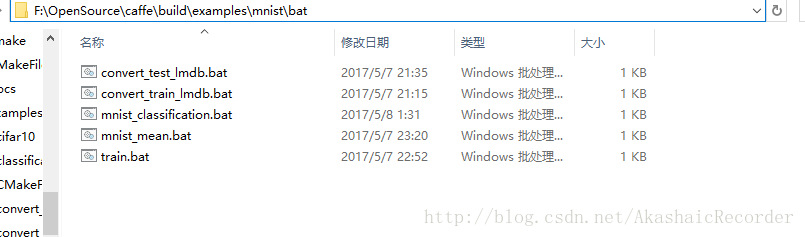
下面我們一一來解釋它們分別的作用:
convert_train_lmdb.bat
F:\OpenSource\caffe\build\examples\mnist\Release\convert_mnist_data.exe
::train-images訓練圖片路徑
F:\OpenSource\caffe\data\mnist\train-images.idx3-ubyte
::訓練標籤路徑
F:\OpenSource\caffe\data\mnist\train-labels.idx1-ubyte
::訓練出來的lmdb檔案存放的位置
F:\OpenSource\caffe\data\mnist\lmdb\train_lmdb
pause注:
Caffe生成的資料分為2種格式:Lmdb和Leveldb 它們都是鍵/值對(Key/Value Pair)嵌入式資料庫管理系統程式設計庫。 雖然lmdb的記憶體消耗是leveldb的1.1倍,但是lmdb的速度比leveldb快10%至15%,更重要的是lmdb允許多種訓練模型同時讀取同一組資料集。 因此lmdb取代了leveldb成為Caffe預設的資料集生成格式。
也就是說,這個程式的作用是為了將原始圖片素材和標籤對應轉換成caffe中能夠執行的lmdb檔案。
convert_test_lmdb.bat
F:\OpenSource\caffe\build\examples\mnist\Release\convert_mnist_data.exe
F:\OpenSource\caffe\data\mnist\t10k-images.idx3-ubyte F:\OpenSource\caffe\data\mnist\t10k-labels.idx1-ubyte F:\OpenSource\caffe\data\mnist\lmdb\test_lmdb
pause同上,convert_train_lmdb.bat是為了轉換用於訓練的lmdb檔案這個則是為了轉換用於測試的lmdb檔案
注意,用於生產存放lmdb檔案的資料夾一定要是不存在的,不然執行bat會報錯——處理程式停止響應
執行完以上兩個後,我們發現caffe\data\mnist\lmdb裡多了兩個資料夾
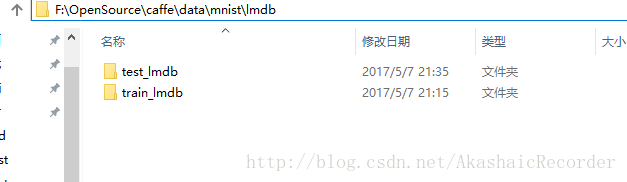
train.bat
F:\OpenSource\caffe\build\tools\Release\caffe.exe train -solver=F:/OpenSource/caffe/examples/mnist/lenet_solver.prototxt
pause訓練模型生成迭代model檔案
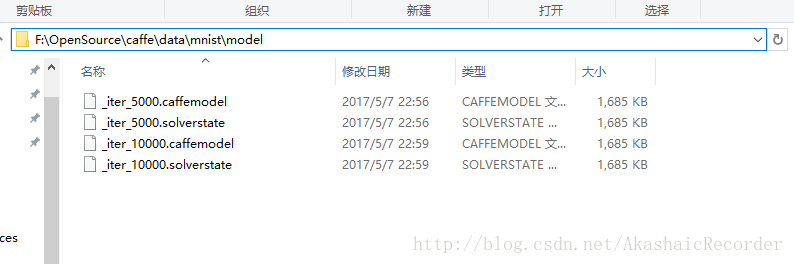
必需檔案》》》
一、網路模型檔案 lenet_train_test.prototxt
位於caffe\examples\mnist
二、訓練超引數檔案 lenet_solver.prototxt
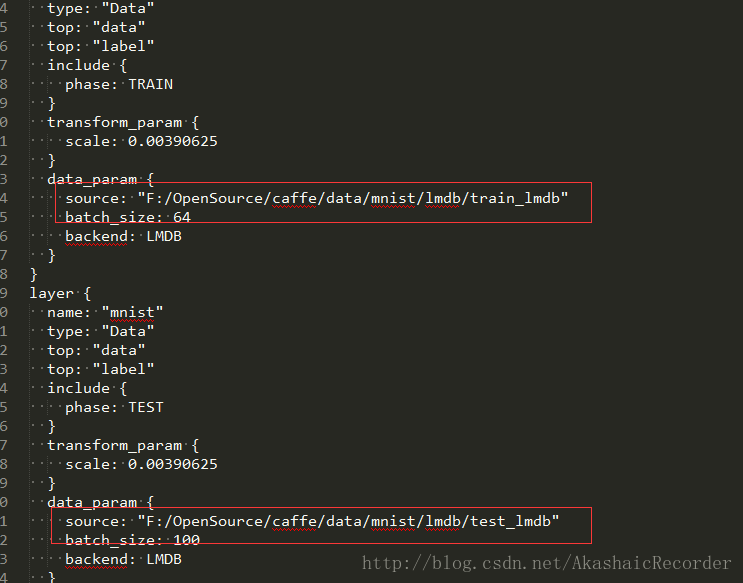
在 lenet_train_test.prototxt修改
TRAIN source路徑為訓練圖片的lmdb檔案路徑
TEST source路徑為測試圖片的lmdb檔案路徑
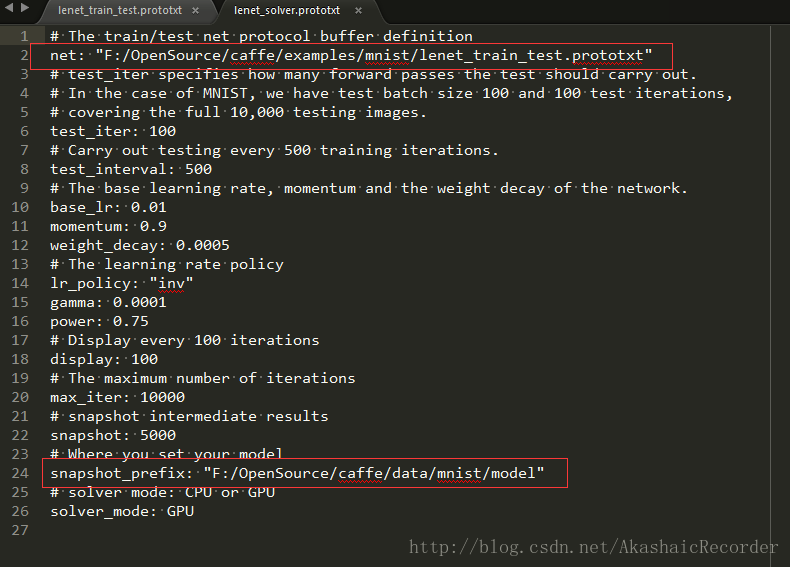
在 lenet_solver.prototxt中修改
net的path為網路模型檔案 lenet_train_test.prototxt的地址,
snapshot_prefix為生產訓練模型的地址caffe\data\mnist\model
如果snapshot_prefix不指定,模型檔案將會預設生成在train.bat同級資料夾下
迭代模型訓練時間根據計算機效能決定,一般在15——45分鐘
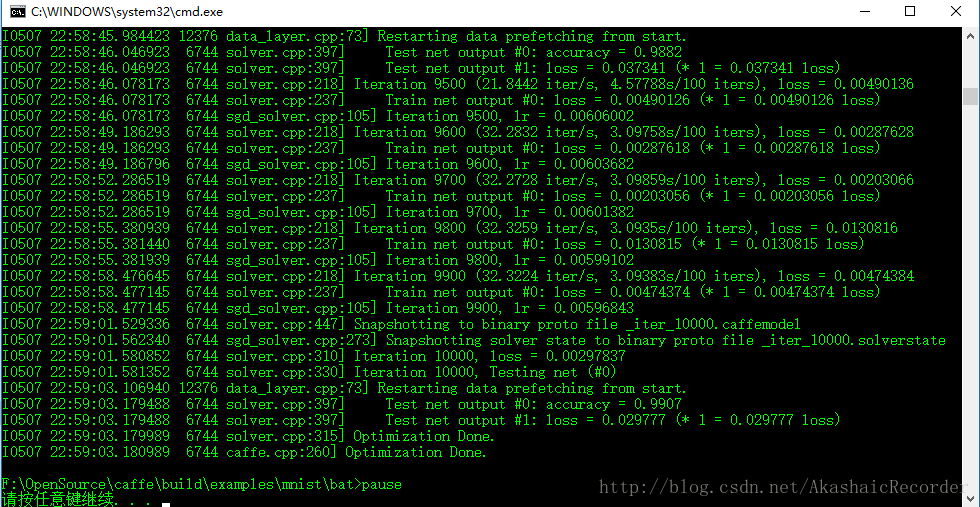
模型生產成功即意味著可以使用它來識別圖片
mnist_mean.bat
F:\OpenSource\caffe\build\tools\Release\compute_image_mean.exe F:\OpenSource\caffe\data\mnist\lmdb\train_lmdb F:\OpenSource\caffe\data\mnist\mean_file\mean.binaryproto
pausemean_file需要自己建立,用於存放計算均值檔案mean.binaryproto
平均歸一化訓練出來的影象對識別結果有提升,所以要使用該方法計算出 訓練/測試資料的平均影象。且求平均影象的方法是直接從LevelDB或者LMDB資料庫裡面直接讀取出來的,而不是直接用影象資料庫裡面求出,所以要提供train_lmdb 路徑,才能求平均影象。
mnist_classification.bat
::分類執行檔案
F:\OpenSource\caffe\build\examples\cpp_classification\Release\classification.exe
::網路模型配置檔案,暫時不用改
F:\OpenSource\caffe\examples\mnist\lenet.prototxt
::訓練好的Caffe Model模型
F:\OpenSource\caffe\data\mnist\model\_iter_10000.caffemodel
::均值檔案的路徑
F:\OpenSource\caffe\data\mnist\mean_file\mean.binaryproto
::訓練影象label標籤
F:\OpenSource\caffe\data\mnist\mnist_lable.txt
::要測試的圖片檔案
F:\OpenSource\caffe\data\mnist\binarybmp\XXX.bmp
pausemnist_lable.txt要怎麼寫?
這裡可以下載用於測試的Mnist圖片庫
http://pan.baidu.com/s/1hrXYLLi
執行mnist_classification.bat
顯示出識別結果
源圖片:

識別結果
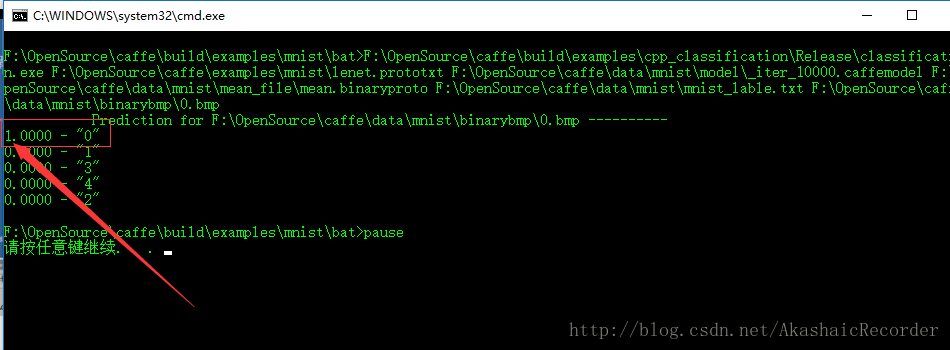
第一行顯示的是該圖片為0的概率,可以看到它成功的識別出了數字0,經測試,這個模型識別數字的準確率大概為90%
下一次,我們將詳細解析模型分析出這樣結果的原因,及如何進一步提高識別率