eclipse如何檢視當前專案的編碼方式+java編碼方式總結
阿新 • • 發佈:2018-10-31
我們寫程式碼有時候會出現這種情況:在自己電腦上執行的很正常,字元顯示很完美,把自己的程式碼給別人或者換臺機器執行,就會出現亂碼的現象,這是為什麼呢?都是編碼方式在作祟,不同的機器或java專案可能使用的預設編碼不同。
如何檢視eclipse 中java專案的編碼方式:

如圖右擊專案名稱,然後選擇propertices選項,就可以了
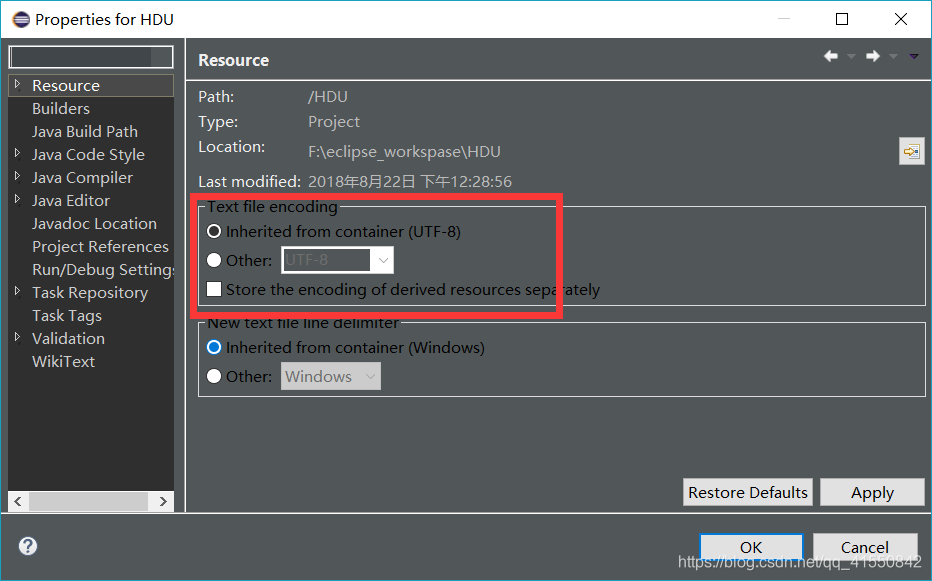
我的這個專案的預設編碼方式是utf-8 ,下面對java的編碼方式總結一下,記錄一下:
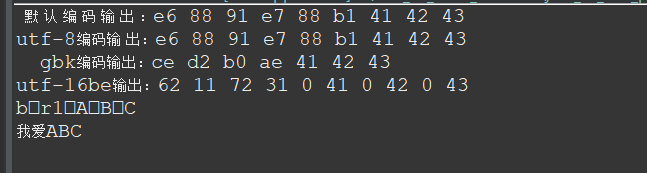
import java.io.UnsupportedEncodingException; public class EncodeDemo { public static void main(String[] args) throws UnsupportedEncodingException{ String s = "我愛ABC"; byte[] byte1 = s.getBytes();//以系統預設的編碼方式轉換為位元組流 System.out.print(" 默 認 編 碼 輸 出 :"); for(byte b : byte1){ System.out.print(Integer.toHexString(b & 0xff) + " "); } System.out.print("\nutf-8編碼輸 出:"); byte[] byte2 = s.getBytes("utf-8");//以utf-8的編碼轉換 for(byte b : byte2){ System.out.print(Integer.toHexString(b & 0xff) + " "); } /* * 以上兩個輸出說明該工程使用的預設編碼是utf-8 * 該編碼格式一個漢字棧佔用三個位元組,英文字母佔用一個位元組 */ System.out.print("\n gbk編碼輸出:"); byte[] byte3 = s.getBytes("gbk"); for(byte b : byte3){ System.out.print(Integer.toHexString(b & 0xff) + " "); } /* * gbk編碼格式,中文佔兩個位元組,英文字母佔一個位元組 */ System.out.print("\nutf-16be輸出:"); /* * java使用的雙位元組編碼(utf-16be) * 中文英文都是兩個位元組 */ byte[] byte4 = s.getBytes("utf-16be"); for(byte b : byte4){ System.out.print(Integer.toHexString(b & 0xff) + " "); } /* * 當我們吧utf-16be編碼格式的byte4轉換為陣列時,不指定編碼方式,而是使用 * 專案預設編碼方式,發現打印出來的是亂碼,之後將編碼方式改為上面utf-16be的 * 格式再打印發現沒有亂碼。同理,如果我們想將byte3轉換為字串再輸出,則需要 * 使用對應的gbk的編碼方式,這樣才不會亂碼 */ System.out.println(); String s1 = new String(byte4);//使用專案預設的編碼(utf-8) System.out.println(s1); String s2 = new String(byte4,"utf-16be"); System.out.println(s2); } }
程式碼中b & 0xff 操作是為了去掉整數高24位多餘的0,因為我們知道一個位元組8位,而int是四個位元組,所以byte轉換為int後就變成了32位,但高24位都是0,影響視覺效果,所以用這個操作把它去掉就好了。輸出結果如下圖: