
Spark_Mllib系列之二———提取,轉化和特徵選擇
Extracting, transforming and selecting features
這部分將會講到特徵的演算法,粗略的分為一下幾個部分:

特徵的提取
TF-IDF
詞條頻率-逆向檔案頻率是一種被廣泛使用在文字提取的向量化特徵的方法,反映了一個詞條對一篇語料庫中的文章的重要性。條目表示為t,一篇文件表示為d,語料庫表示為D,詞條頻率TF(td)是詞條t出現在文件d中的次數,而文件頻率DF是包含這個詞條的文件數目,簡而言之就是多少篇文件包含這個詞條。如果我們僅僅用詞條頻率來估量重要程度,很容易偏重詞條經常出現但只有很少資訊的文件,比如“a”,”the”,和”of”,如果一個詞條經常出現在預料庫中,這意味著這個條目沒有特殊意義對於一個文件。反向文件頻率是隊一個詞條所攜帶的資訊量做數字化估量的方法:
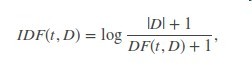
相關推薦
Spark_Mllib系列之二———提取,轉化和特徵選擇
Extracting, transforming and selecting features 這部分將會講到特徵的演算法,粗略的分為一下幾個部分: 特徵的提取 TF-IDF 詞條頻率-逆向檔案頻率是一種被廣泛使用在文字提取的向量化特徵的方法,反映了一個詞條對一篇語料庫
MAVEN系列之二@編寫POM.xml和講解
0、慣例,廢話 廢話少說,直接提槍上陣,如有不妥之處,還請多多賜教。 現在的專案建立都是使用的整合化開發工具,各種工具,各種用法,不管是什麼工具,反正目標只有一個,就是一切為自己開發服務。然後廢話說了那麼多,也不是今天的重點,重點是下面的目錄
SpringCloud學習系列之二 ----- 服務消費者(Feign)和負載均衡(Ribbon)
n) 描述 servers request 其中 led rac stp 定期 前言 本篇主要介紹的是SpringCloud中的服務消費者(Feign)和負載均衡(Ribbon)功能的實現以及使用Feign結合Ribbon實現負載均衡。 SpringCloud Feign
【Unity Shaders】ShadowGun系列之二——霧和體積光
依靠 action 圖形學 取值 線性 數學 viewer https 是否 寫在前面體積光,這個名稱是God Rays的中文翻譯,感覺不是非常形象。God Rays事實上是Crepuscular rays在圖形學中的說法,而Crepuscular rays的意思是雲隙光
【iOS與EV3混合機器人編程系列之二】工欲善其事,必先利其器(準備篇)
style 混合 版權 相同 開發 code 操作系統 圖形 ipa 在上一篇文章中,我們論述了iOS與EV3結合後機器人開發的無限可能。那麽,大家要不要一起來Hacking一把呢?為了能夠完整地完畢我接下來我講的項目。我們須要做下面準備:1、一臺Mac執行MAC OS
從產品展示頁面談談Hybris系列之二: DTO, Converter和Populator
ext 存儲 resource tar adl 裏的 resolve 個數 lis 文章作者:張健(Zhang Jonathan) 上一篇文章 從產品展示頁面談談Hybris的特有概念和設計結構 我們講解了Hybris一些特有的概念以及大體架構,並且介紹了Facade層裏是
Https系列之二:https的SSL證書在服務器端的部署,基於tomcat,spring boot
onf 基於 分享 height 轉化 自簽名 size class ont 一:本文的主要內容介紹 CA證書的下載及相應文件的介紹 CA證書在tomcat的部署 CA證書在spring boot的部署 自簽名證書的部署 二:一些內容的回顧 在Https系列之一中已介
【LC3開源峰會網絡技術系列之二】阿裏雲開發智能網卡的動機、功能框架和軟轉發程序
copy 特點 fda 優化 ext shadow 所有 type 解密 摘要: 摘要 這篇文章介紹了阿裏雲開發智能網卡的動機、功能框架和軟轉發程序以及在軟轉發過程中發現的問題和優化方法。 主講人陳靜 阿裏雲高級技術專家 主題Zero-copy Optimization f
手遊客戶端的效能篇(二)----Unity和C#版之字串拼接,Struct和Class的區別與應用
接著上篇文章: 2、字串拼接(簡單,直接結論) 使用“a” + “b”在幾次(10次以內吧)連線是不會產生gc的但是大量連線就會產生; 連線多的用StringBuilder,內部
“陶華碧”該不該融資系列之二:坐莊的方程式,錯誤的市值管理是怎樣毀滅創業者的
http://www.eeo.com.cn/2018/1121/341590.shtml “陶華碧”該不該融資系列之二:坐莊的方程式,錯誤的市值管理是怎樣毀滅創業者的 2018-11-21 經濟觀察網 鄒衛國/文 近日
史上最詳細、最完全的ipython使用教程,Python使用者必備!——ipython系列之二
宣告:本文承接前面一篇文章,ipython系列之一;另外,本文所指的ipython不是ipython notebook,ipython notebook已經被jupyter notebook所取代,不再叫ipython notebook了。 前面講解了ipython裡面的一些核心
「數據治理那點事」系列之二:手握數據「戶口本」,數據治理肯定穩!
物理 系列 數據對比 概念 決策者 等等 ges mode 架構 這篇文章主要從數據治理的基礎和核心之一:元數據 入手,從以下幾個角度展開具體講解: 元數據概念元數據的分布和采集元數據的一些實際應用場景. 1.元數據到底是個啥? 如果我說:元數據(Meta Data),就是
【Java進階面試系列之二】:哥們,那你說說系統架構引入訊息中介軟體有什麼缺點?
歡迎關注個人公眾號:石杉的架構筆記(ID:shishan100) 週一至週五早8點半!精品技術文章準時送上! 一、前情回顧 上篇文章「Java進階面試系列之一」你們系統架構中為何要引入訊息中介軟體?,給大家講了講訊息中介軟體引入系統架構的作用,主要是解決哪些問題的。 其比較常見的實踐場景是: 複雜系統
三叔學FPGA系列之二:Cyclone V中的POR、配置、初始化,以及復位
對於FPGA內部的復位,之前一直比較迷,這兩天仔細研究官方資料手冊,解開了心中的諸多疑惑,感覺自己又進步了呢..... 一、關於POR(Power-On Reset ) FPGA在上電工作時,會先進入復位模式,將所有RAM位清除,並通過內部弱上拉電阻將使用者I/O置為三態。接著依次完成 配置、初始化工
敏捷外包工程系列之二:人員結構(敏捷外包工程,敏捷開發,產品負責人,客戶價值)
本文是敏捷外包工程系列的第二篇。(之一,之二,之三,之四)敏捷開發整體上適合小團隊、產品研發(所以才有product owner一稱)的環境,而外包軟體開發中常常存在的則相反,因此在建立團隊的時候要充分認識到這一點。下文提到“企業”時指軟體開發公司即乙方,而“客戶”指政府、銀
面試必問系列之 建構函式,原型物件和例項之間的關係(一)
關於建構函式,原型物件,例項之間的關係 ,先來看一張圖,大致瞭解下1,建構函式建構函式跟普通函式沒什麼區別,都是由function定義的,為了和普通函式做區別,一般建構函式首字母大寫像這樣,建構函式可以使用new操作符呼叫,也可以像普通函式那樣呼叫,如果像普通函式那樣呼叫,
剖析Elasticsearch集群系列之二:分散式的三個C、translog和Lucene段
共識——裂腦問題及法定票數的重要性 共識是分散式系統的一項基本挑戰。它要求系統中的所有程序/節點必須對給定資料的值/狀態達成共識。已經有很多共識演算法諸如Raft、Paxos等,從數學上的證明了是行得通的。但是,Elasticsearch卻實現了自己的共識系統(zen
C/C++回撥方式系列之二class介面回撥和lambda程式
在《C/C++回撥方式系列之一》中我們總結了函式指標模式回撥,這些回調當時比較原始,容易給人一種面向過程的程式設計的感覺,而且函式指標的格式比較繁瑣,可讀性相對差一點。本系列二將總結比較推薦的回撥使用模式。 一、class介面回撥模式 1. 定義介面 C++可以定義virt
spring boot 系列之二:spring boot 如何修改預設埠號和contextpath
上一篇檔案我們通過一個例項進行了spring boot 入門,我們發現tomcat埠號和上下文(context path)都是預設的, 如果我們對於這兩個值有特殊需要的話,需要自己制定的時候怎麼辦呢? 一、問題解決: 在src/main/resources目錄下新建檔案application.pro
【只怕沒有幾個人能說清楚】系列之二:Unity中的特殊文件夾
物體 avi ebp time 編輯模式 tro hive 預覽 打包 參考:http://www.manew.com/thread-99292-1-1.html 1. 隱藏文件夾 以.開頭的文件夾會被忽略。在這種文件夾中的資源不會被導入,腳本不會被編譯。也不會出現