
HashMap 內部原理
HashMap 內部實現
通過名字便可知道的是,HashMap 的原理就是雜湊。HashMap內部維護一個 Buckets 陣列,每個 Bucket 封裝為一個 Entry<K, V> 鍵值對形式的連結串列結構,這個 Buckets 陣列也稱為表。表的索引是 金鑰K 的雜湊值(雜湊碼)。如下圖所示:
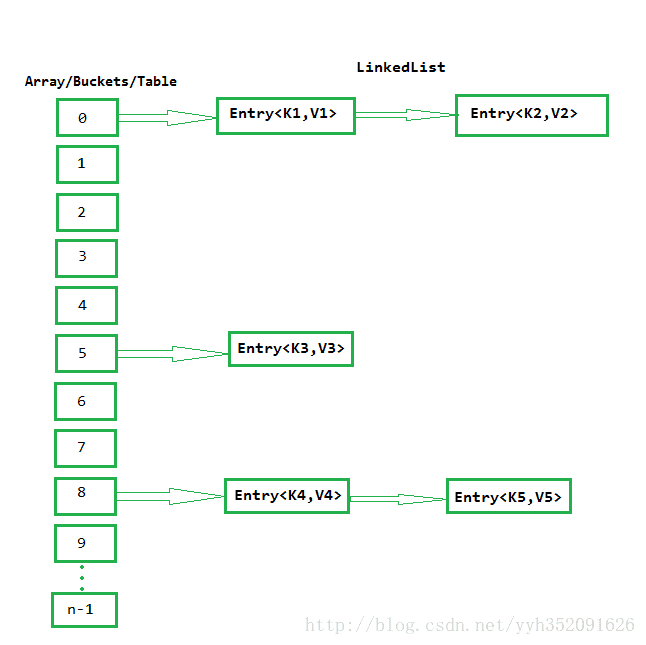
連結串列的每個節點是一個名為 Entry<K,V> 的類的例項。 Entry 類實現了 Map.Entry 介面,下面是Entry類的程式碼:
private static class Entry<K,V> implements Map 注: 每個 Entry 物件僅與一個特定 key 相關聯,但其 value 是可以改變的(如果相同的 key 之後被重新插入不同的 value) - 因此鍵是最終的,而值不是。 每個Entry物件都有一個名為 next 的欄位,它指向下一個Entry,所以實際上為單鏈表結構。hash 欄位儲存了 Entry 物件在 Buckets 陣列索引,也就是 key 的雜湊值。
如果發生Hash碰撞,也就是兩個key的hash值相同,或者如果這個元素所在的位子上已經存放有其他元素了,那麼在同一個位子上的元素將以連結串列的形式存放,新加入的放在鏈頭,最早加入的放在鏈尾。
影響 HashMap 效能的兩個因素是初始容量和負載因子。容量是表陣列的長度,初始容量只是建立雜湊表時的容量。負載因子是衡量雜湊表在容量自動增加之前是否允許獲取的量度(比例)。
當散列表中的 Entry 數量超過負載因子和當前容量的乘積時,將會重新雜湊該表(也就是重建內部資料結構),使得散列表具有大約兩倍的容量(這個其實和ArrayList類似)。
理解 put() 方法
public V put(K key, V value) {
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
if 注:這個計算出來的hash值被傳遞給內部雜湊函式,雜湊函式將返回金鑰的雜湊值。這個值就是 bucket/陣列 的索i引。
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}這裡就有個疑問了,我們如何計算對應儲存陣列索引,首先想到的就是把hashcode對陣列長度取模運算,也就是h%length,這樣一來,元素的分佈相對來說是比較均勻的。但是,“模”運算的消耗還是比較大的,能不能找一種更快速,消耗更小的方式那中?
首先算得key得hashcode值,然後跟陣列的長度-1做一次“與”運算(&)。看上去很簡單,其實比較有玄機。比如陣列的長度是2的4次方,那麼hashcode就會和2的4次方-1做“與”運算。很多人都有這個疑問,為什麼hashmap的陣列初始化大小都是2的次方大小時,hashmap的效率最高,我以2的4次方舉例,來解釋一下為什麼陣列大小為2的冪時hashmap訪問的效能最高。
如下圖,左邊兩組是陣列長度為16(2的4次方),右邊兩組是陣列長度為15。兩組的hashcode均為8和9,但是很明顯,當它們和1110“與”的時候,產生了相同的結果,也就是說它們會定位到陣列中的同一個位置上去,這就產生了碰撞,8和9會被放到同一個連結串列上,那麼查詢的時候就需要遍歷這個連結串列,得到8或者9,這樣就降低了查詢的效率。同時,我們也可以發現,當陣列長度為15的時候,hashcode的值會與14(1110)進行“與”,那麼最後一位永遠是0,而0001,0011,0101,1001,1011,0111,1101這幾個位置永遠都不能存放元素了,空間浪費相當大,更糟的是這種情況中,陣列可以使用的位置比陣列長度小了很多,這意味著進一步增加了碰撞的機率,減慢了查詢的效率!
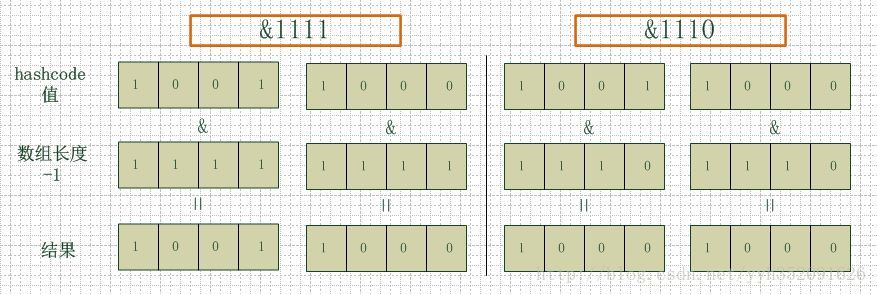
上圖參考自:http://blog.csdn.net/oqqYeYi/article/details/39831029
理解 get() 方法
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : sun.misc.Hashing.singleWordWangJenkinsHash(key); // 計算hash值
// 根據索引遍歷連結串列,找出相等的key
for (HashMapEntry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}get 與 put 總結
下面總結了 put() 和 get() 發生的三個重要步驟:
- 通過呼叫 計算 Hash Code 方法計算金鑰的雜湊碼。
- 將計算的雜湊碼傳遞到內部雜湊函式
indexFor()以獲取表的索引。 - 迭代通過在索引處出現的連結串列,並呼叫
equals()方法來查詢匹配鍵。
所以在這之前要先理解 equals() 和 hashCode() 這兩個方法。
在 Java8 中的改善
在Java 8中,對HashMap有一個性能上的改進。當金鑰中存在許多雜湊衝突(不同的金鑰最終具有相同的雜湊值或索引)時,平衡樹將用於儲存 Entry 物件,而不是連結串列。做法是,一旦 bucket 中的 Entry 數量增長超過某一閾值,則 bucket 將從 Entry 連結串列切換到平衡樹。