
京東預測系統核心介紹
1. 京東預測系統
1.1 預測系統介紹
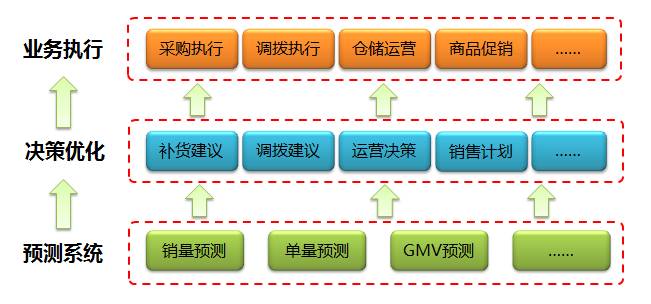
預測系統在整個供應鏈體系中處在最底層並且起到一個支撐的作用,支援上層的多個決策優化系統,而這些決策優化系統利用精準的預測資料結合運籌學技術得出最優的決策,並將結果提供給更上層的業務執行系統或是業務方直接使用。
目前,預測系統主要支援三大業務:銷量預測、單量預測和GMV預測。其中銷量預測主要支援商品補貨、商品調撥;單量預測主要支援倉庫、站點的運營管理;GMV預測主要支援銷售部門計劃的定製。
銷量預測按照不同維度又可以分為RDC採購預測、FDC調撥預測、城市倉調撥預測、大建倉補貨預測、全球購銷量預測和圖書促銷預測等;單量預測又可分為庫房單量預測、配送中心單量預測和配送站單量預測等(在這裡“單量”並非指使用者所下訂單的量,而是將訂單拆單後流轉到倉庫中的單量。例如一個使用者的訂單中包括3件物品,其中兩個大件品和一個小件品,在京東的供應鏈環節中可能會將其中兩個大件品組成一個單投放到大件倉中,而將那個小件單獨一個單投放到小件倉中,單量指的是拆單後的量);GMV預測支援到商品粒度。
1.2 預測系統架構
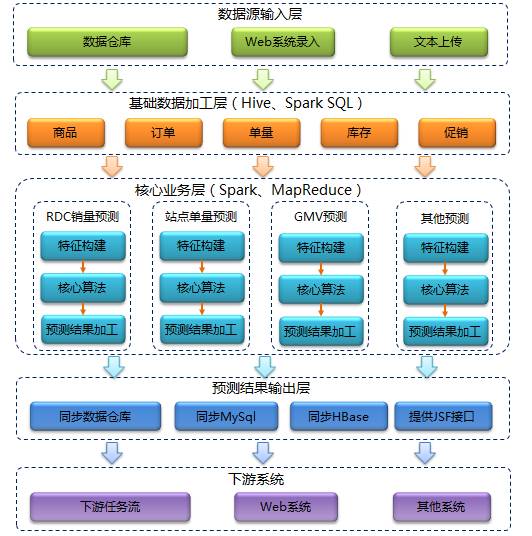
整體架構從上至下依次是:資料來源輸入層、基礎資料加工層、核心業務層、資料輸出層和下游系統。首先從外部資料來源獲取我們所需的業務資料,然後對基礎資料進行加工清洗,再通過時間序列、機器學習等人工智慧技術對資料進行處理分析,最後計算出預測結果並通過多種途徑推送給下游系統使用。
- 資料來源輸入層:京東資料倉庫中儲存著我們需要的大部分業務資料,例如訂單資訊、商品資訊、庫存資訊等等。而對於促銷計劃資料則大部分來自於採銷人員通過Web系統錄入的資訊。除此之外還有一小部分資料通過文字形式直接上傳到HDFS中。
- 基礎資料加工層:在這一層主要通過Hive對基礎資料進行一些加工清洗,去掉不需要的欄位,過濾不需要的維度並清洗有問題的資料。
- 核心業務層:這層是系統的的核心部分,橫向看又可分為三層:特徵構建、預測演算法和預測結果加工。縱向看是由多條業務線組成,彼此之間不發生任何交集。
- 特徵構建:將之前清洗過的基礎資料通過近一步的處理轉化成標準格式的特徵資料,提供給後續演算法模型使用。
- 核心演算法:利用時間序列分析、機器學習等人工智慧技術進行銷量、單量的預測,是預測系統中最為核心的部分。
- 預測結果加工:預測結果可能在格式和一些特殊性要求上不能滿足下游系統,所以還需要根據實際情況對其進行加工處理,比如增加標準差、促銷標識等額外資訊。
- 預測結果輸出層:將最終預測結果同步回京東資料倉庫、MySql、HBase或製作成JSF介面供其他系統遠端呼叫。
- 下游系統:包括下游任務流程、下游Web系統和其他系統。
2. 預測系統核心介紹
2.1 預測系統核心層技術選型
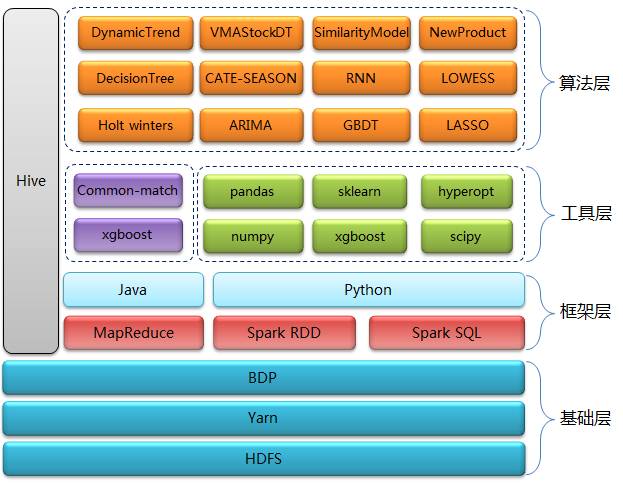
預測系統核心層技術主要分為四層:基礎層、框架層、工具層和演算法層
基礎層: HDFS用來做資料儲存,Yarn用來做資源排程,BDP(Big Data Platform)是京東自己研發的大資料平臺,我們主要用它來做任務排程。
框架層: 以Spark RDD、Spark SQL、Hive為主, MapReduce程式佔一小部分,是原先遺留下來的,目前正逐步替換成Spark RDD。 選擇Spark除了對效能的考慮外,還考慮了Spark程式開發的高效率、多語言特性以及對機器學習演算法的支援。在Spark開發語言上我們選擇了Python,原因有以下三點:
- Python有很多不錯的機器學習演算法包可以使用,比起Spark的MLlib,演算法的準確度更高。我們用GBDT做過對比,發現xgboost比MLlib裡面提供的提升樹模型預測準確度高出大概5%~10%。雖然直接使用Spark自帶的機器學習框架會節省我們的開發成本,但預測準確度對於我們來說至關重要,每提升1%的準確度,就可能會帶來成本的成倍降低。
- 我們的團隊中包括開發工程師和演算法工程師,對於演算法工程師而言他們更擅長使用Python進行資料分析,使用Java或Scala會有不小的學習成本。
- 對比其他語言,我們發現使用Python的開發效率是最高的,並且對於一個新人,學習Python比學習其他語言更加容易。
工具層: 一方面我們會結合自身業務有針對性的開發一些演算法,另一方面我們會直接使用業界比較成熟的演算法和模型,這些演算法都封裝在第三方Python包中。我們比較常用的包有xgboost、numpy、pandas、sklearn、scipy和hyperopt等。
Xgboost:它是Gradient Boosting Machine的一個C++實現,xgboost最大的特點在於,它能夠自動利用CPU的多執行緒進行並行,同時在演算法上加以改進提高了精度。
numpy:是Python的一種開源的數值計算擴充套件。這種工具可用來儲存和處理大型矩陣,比Python自身的巢狀列表結構要高效的多(該結構也可以用來表示矩陣)。
pandas:是基於NumPy 的一種工具,該工具是為了解決資料分析任務而建立的。Pandas 納入了大量庫和一些標準的資料模型,提供了高效地操作大型資料集所需的工具。
sklearn:是Python重要的機器學習庫,支援包括分類、迴歸、降維和聚類四大機器學習演算法。還包含了特徵提取、資料處理和模型評估三大模組。
scipy:是在NumPy庫的基礎上增加了眾多的數學、科學以及工程計算中常用的庫函式。例如線性代數、常微分方程數值求解、訊號處理、影象處理和稀疏矩陣等等。
演算法層: 我們用到的演算法模型非常多,原因是京東的商品品類齊全、業務複雜,需要根據不同的情況採用不同的演算法模型。我們有一個獨立的系統來為演算法模型與商品之間建立匹配關係,有些比較複雜的預測業務還需要使用多個模型。我們使用的演算法總體上可以分為三類:時間序列、機器學習和結合業務開發的一些獨有的演算法。
1. 機器學習演算法主要包括GBDT、LASSO和RNN :
GBDT:是一種迭代的決策樹演算法,該演算法由多棵決策樹組成,所有樹的結論累加起來做最終答案。我們用它來預測高銷量,但歷史規律不明顯的商品。
RNN:這種網路的內部狀態可以展示動態時序行為。不同於前饋神經網路的是,RNN可以利用它內部的記憶來處理任意時序的輸入序列,這讓它可以更容易處理如時序預測、語音識別等。
LASSO:該方法是一種壓縮估計。它通過構造一個罰函式得到一個較為精煉的模型,使得它壓縮一些係數,同時設定一些係數為零。因此保留了子集收縮的優點,是一種處理具有復共線性資料的有偏估計。用來預測低銷量,歷史資料平穩的商品效果較好。
2. 時間序列主要包括ARIMA和Holt winters :
ARIMA:全稱為自迴歸積分滑動平均模型,於70年代初提出的一個著名時間序列預測方法,我們用它來主要預測類似庫房單量這種平穩的序列。
Holt winters:又稱三次指數平滑演算法,也是一個經典的時間序列演算法,我們用它來預測季節性和趨勢都很明顯的商品。
3. 結合業務開發的獨有演算法包括WMAStockDT、SimilarityModel和NewProduct等:
WMAStockDT:庫存決策樹模型,用來預測受庫存狀態影響較大的商品。
SimilarityModel:相似品模型,使用指定的同類品資料來預測某商品未來銷量。
NewProduct:新品模型,顧名思義就是用來預測新品的銷量。
2.2 預測系統核心流程
預測核心流程主要包括兩類:以機器學習演算法為主的流程和以時間序列分析為主的流程。
1. 以機器學習演算法為主的流程如下:
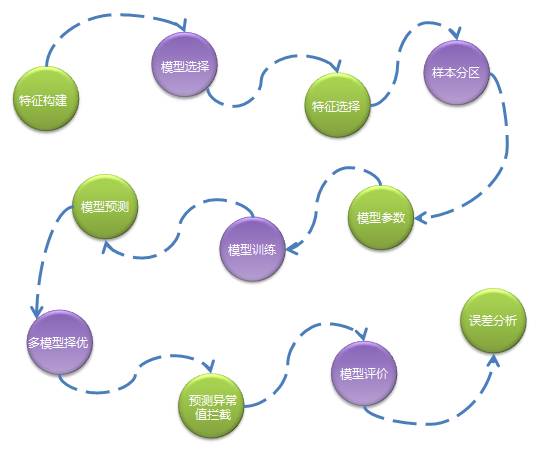
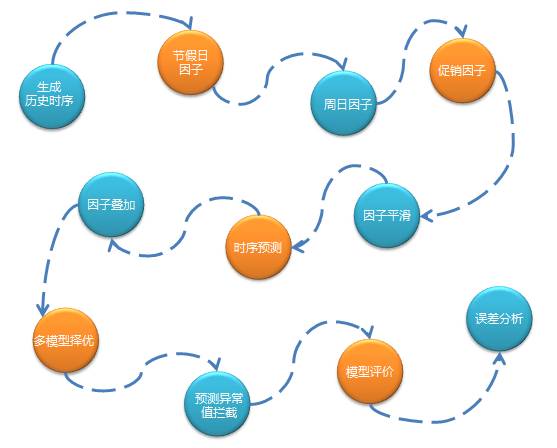
特徵構建:通過資料分析、模型試驗確定主要特徵,通過一系列任務生成標準格式的特徵資料。
模型選擇:不同的商品有不同的特性,所以首先會根據商品的銷量高低、新品舊品、假節日敏感性等因素分配不同的演算法模型。
特徵選擇:對一批特徵進行篩選過濾不需要的特徵,不同型別的商品特徵不同。
樣本分割槽:對訓練資料進行分組,分成多組樣本,真正訓練時針對每組樣本生成一個模型檔案。一般是同類型商品被分成一組,比如按品類維度分組,這樣做是考慮並行化以及模型的準確性。
模型引數:選擇最優的模型引數,合適的引數將提高模型的準確度,因為需要對不同的引數組合分別進行模型訓練和預測,所以這一步是非常耗費資源。
模型訓練:待特徵、模型、樣本都確定好後就可以進行模型訓練,訓練往往會耗費很長時間,訓練後會生成模型檔案,儲存在HDFS中。
模型預測:讀取模型檔案進行預測執行。
多模型擇優:為了提高預測準確度,我們可能會使用多個演算法模型,當每個模型的預測結果輸出後系統會通過一些規則來選擇一個最優的預測結果。
預測值異常攔截:我們發現越是複雜且不易解釋的演算法越容易出現極個別預測值異常偏高的情況,這種預測偏高無法結合歷史資料進行解釋,因此我們會通過一些規則將這些異常值攔截下來,並且用一個更加保守的數值代替。
模型評價:計算預測準確度,我們通常用使用mapd來作為評價指標。
誤差分析:通過分析預測準確度得出一個誤差在不同維度上的分佈,以便給演算法優化提供參考依據。
2. 以時間序列分析為主的預測流程如下:
2.3 Spark在預測核心層的應用
我們使用Spark SQL和Spark RDD相結合的方式來編寫程式,對於一般的資料處理,我們使用Spark的方式與其他無異,但是對於模型訓練、預測這些需要呼叫演算法介面的邏輯就需要考慮一下並行化的問題了。我們平均一個訓練任務在一天處理的資料量大約在500G左右,雖然資料規模不是特別的龐大,但是Python演算法包提供的演算法都是單程序執行。我們計算過,如果使用一臺機器訓練全部品類資料需要一個星期的時間,這是無法接收的,所以我們需要藉助Spark這種分散式平行計算框架來將計算分攤到多個節點上實現並行化處理。
我們實現的方法很簡單,首先需要在叢集的每個節點上安裝所需的全部Python包,然後在編寫Spark程式時考慮通過某種規則將資料分割槽,比如按品類維度,通過groupByKey操作將資料重新分割槽,每一個分割槽是一個樣本集合並進行獨立的訓練,以此達到並行化。流程如下圖所示:
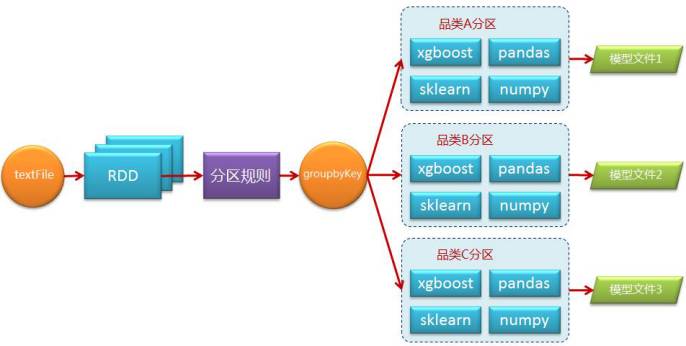
偽碼如下:

repartitionBy方法即設定一個重分割槽的邏輯返回(K,V)結構RDD,train方法是訓練資料,在train方法裡面會呼叫Python演算法包介面。saveAsPickleFile是Spark Python獨有的一個Action操作,支援將RDD儲存成序列化後的sequnceFile格式的檔案,在序列化過程中會以10個一批的方式進行處理,儲存模型檔案非常適合。
雖然原理簡單,但存在著一個難點,即以什麼樣的規則進行分割槽,key應該如何設定。為了解決這個問題我們需要考慮幾個方面,第一就是哪些資料應該被聚合到一起進行訓練,第二就是如何避免資料傾斜。
針對第一個問題我們做了如下幾點考慮:
- 被分在一個分割槽的資料要有一定的相似性,這樣訓練的效果才會更好,比如按品類分割槽就是個典型例子。
- 分析商品的特性,根據特性的不同選擇不同的模型,例如高銷商品和低銷商品的預測模型是不一樣的,即使是同一模型使用的特徵也可能不同,比如對促銷敏感的商品就需要更多與促銷相關特徵,相同模型相同特徵的商品應傾向於分在一個分割槽中。
針對第二個問題我們採用瞭如下的方式解決:
- 對於資料量過大的分割槽進行隨機抽樣選取。
- 對於資料量過大的分割槽還可以做二次拆分,比如圖書小說這個品類資料量明顯大於其他品類,於是就可以分析小說品類下的子品類資料量分佈情況,並將子品類合併成新的幾個分割槽。
- 對於資料量過小這種情況則需要考慮進行幾個分割槽資料的合併處理。
總之對於後兩種處理方式可以單獨通過一個Spark任務定期執行,並將這種分割槽規則儲存。