
TensorFlow學習筆記(四)
學習筆記摘自TensorFlow中文社群http://www.tensorfly.cn/
本次學習字元的向量表示
字元的向量表示
學習目錄
- 為何需要使用向量表示文字
- 通過直觀地例子觀察模型背後的本質,以及它是如何訓練的(通過一些數學方法評估)。
- 展示了TensorFlow對該模型的簡單實現
- 使這個簡單的模型變得更好
1、為什麼需要使用向量來表示文字
通常影象或音訊系統處理的是由圖片中所有單個原始畫素點強度值或者音訊中功率譜密度的強度值,把它們編碼成豐富、高緯度的向量資料集。對於物體或語音識別這一類的任務,我們所需的全部資訊已經都儲存在原始資料中(顯然人類本身就是依賴原始資料進行日常的物體或語音識別的)。然後,自然語言處理系統通常將詞彙作為離散的單一符號,例如“cat”一詞或可表示為Id537,而“dog”一詞可以表示為Id143。這些符號編碼毫無規律,無法提供不同詞彙之間可能存在的關聯資訊。換句話說,在處理關於“dogs”一詞的資訊時,模型將無法利用已知的關於“cats”資訊(例如,它們都是動物,有四條腿,可作為寵物等等)。可見,將詞彙表達為上述的獨立離散符號將進一步導致資料稀疏,使我們在訓練統計模型時不得不尋求更多的資料。而詞彙的向量表示將克服上述的難題。
向量空間模型(VSMs)將詞彙表達(巢狀)於一個連續的向量空間中,語義近似的詞彙被對映為相鄰的資料點。向量空間模型在自然語言處理領域中有著漫長且豐富的歷史,不過幾乎所有利用這一模型的方法都依賴於分散式假設,其核心思想為出現於上下文情景中的詞彙都有相類似的語義。採用這一假設的研究方法大致分為兩類:基於技術的方法(潛在語義分析https://en.wikipedia.org/wiki/Latent_semantic_analysis)和預測方法(神經概率化語言模型http://www.scholarpedia.org/article/Neural_net_language_models)。這些東西在後續的學習中會講到。
簡而言之:基於計數的方法計算詞彙與其鄰近詞彙在一個大型語料庫中共同出現的頻率及其他統計量。然後將這些統計量對映到一個小型且稠密的向量中。預測方法則試圖直接從某詞彙對其進行預測,在此過程中利用已經學習到的小型且稠密的巢狀向量。
Word2vec是一種可以進行高效率詞巢狀學習的預測模型。其兩種變體分別為:連續詞袋模型(CBOW)及Skip_Gram模型。從演算法角度看,這兩種方法非常相似,其區別為CBOW根據源詞上下文詞彙(‘the cat sits on the’)來預測目標詞彙(例如,‘mat’),而Skip_Gram模型做法相反,它通過目標詞彙來預測源詞彙。Skip_Gram模型採取CBOM的逆過程的動機在於:CBOW演算法對於很多分散式資訊進行了平滑處理(例如將一整段上下文資訊視為一個單一觀察量)。很多情況下,對於小型的資料集,這一處理是有幫助的。相形之下,Skip-Gram模型將每個“上下文-目標詞彙”的組合視為一個新觀察量,這種做法在大型資料集中會更為有效。下面著重講解Skip-Gram模型。
處理噪聲對比訓練
神經概率化語言模型通常使用極大似然法(ML)進行訓練,其中通過softmax function 來最大化當提供一個單詞“h”(代表“history”),後一個單詞的概率Wt(代表“target”),
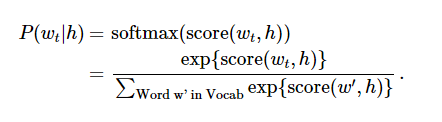
當score(w_t,h)計算了文字w_t和上下文h的相容性(通常使用向量積)。我們使用對數似然函式來訓練訓練集的最大值。
這裡提出了一個解決語言概率模型的合適的通用方法。然而這個方法實際執行起來開銷非常大,因為我們需要去計算並正則化當前上下文環境h中所有其他V單詞w‘的概率得分,在每一步訓練迭代中。

從另一個角度來說,當使用word2vec模型時,我們並不需要對概率模型中的所有特徵進行學習。而CBOW模型和Skip-Gram模型為了避免這種情況發生,使用一個二分類器(邏輯迴歸)在同一個上下文環境裡從k虛構的(噪聲)單詞w區分出真正的目標單詞Wt。我們下面詳細闡述一下CBOW模型,對於Skip-Gram模型只要簡單地做相反的操作即可。

說實在的。我有點看不懂了,
未完