
Memcache-Java-Client-Release原始碼閱讀(之六)
一、主要內容
本章節的主要內容是介紹Memcache Client的一致性Hash演算法的應用及實現。
二、準備工作
1、伺服器啟動192.168.0.106:11211,192.168.0.106:11212兩個服務端例項。
2、示例程式碼:
String[] servers = { "192.168.0.106:11211", "192.168.0.106:11212" };
SockIOPool pool = SockIOPool.getInstance();
pool.setServers(servers);
pool.setInitConn(10);
pool.setMinConn 三、一致性Hash演算法簡單介紹
一致性Hash演算法主要適用於動態變化的cache環境中,比如P2P場景,快取系統,主要解決的問題是動態增加、刪除節點引起的系統震盪。
1、Hash演算法的衡量指標
單調性(Monotonicity):單調性是指如果已經有一些內容通過雜湊分派到了相應的緩衝中,又有新的緩衝加入到系統中。雜湊的結果應能夠保證原有已分配的內容可以被對映到新的緩衝中去,而不會被對映到舊的緩衝集合中的其他緩衝區。
平衡性(Balance):指雜湊的結果能夠儘可能分佈到所有的緩衝中去,這樣可以使得所有的緩衝空間都得到利用。
分散性(Spread):在分散式環境中,終端有可能看不到所有的緩衝,而是隻能看到其中的一部分。當終端希望通過雜湊過程將內容對映到緩衝上時,由於不同終端所見的緩衝範圍有可能不同,從而導致雜湊的結果不一致,最終的結果是相同的內容被不同的終端對映到不同的緩衝區中。這種情況顯然是應該避免的,因為它導致相同內容被儲存到不同緩衝中去,降低了系統儲存的效率。分散性的定義就是上述情況發生的嚴重程度。好的雜湊演算法應能夠儘量避免不一致的情況發生,也就是儘量降低分散性。
負載(Load):負載問題實際上是從另一個角度看待分散性問題。既然不同的終端可能將相同的內容對映到不同的緩衝區中,那麼對於一個特定的緩衝區而言,也可能被不同的使用者對映為不同 的內容。與分散性一樣,這種情況也是應當避免的,因此好的雜湊演算法應能夠儘量降低緩衝的負荷。
2、路由演算法
因為在一致性Hash演算法中,各個節點只負責管理一部分緩衝區,所以對於任何一個Hash的鍵值,存在這個鍵值應該歸屬到哪個節點的問題,這個查詢演算法就叫做路由演算法。
舉一個簡單的例子,在0–2^32(2的32次方,^表示冪,下文類似)緩衝區空間內,有4個節點A、B、C、D平均分管這片空間,並且定義A分管的為0-2^8-1,B分管的為2^8-2^16,C分管的為2^16-2^24-1,D分管的為2^24-2^32,各節點都儲存了本節點和其他幾個鄰近節點的分管資訊,如果某個物件的鍵值為15(介於0-2^8-1 之間),那麼它查詢的節點應該為A。
3、一致性Hash應用模型
環形Hash空間 :按照常用的hash演算法來將對應的key雜湊到一個具有2^32次方個桶的空間中,即0~(2^32)-1的數字空間中。現在我們可以將這些數字頭尾相連,想象成一個閉合的環形。如下圖
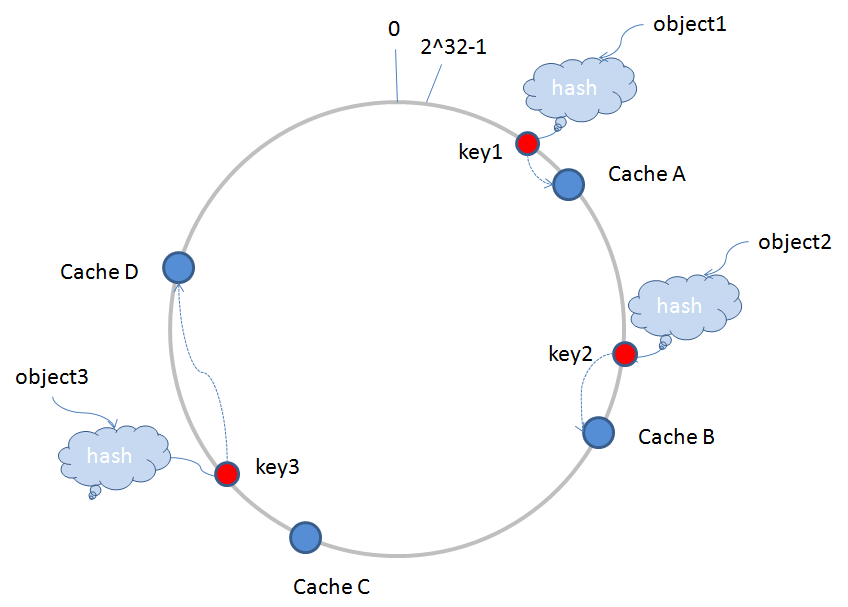
object1,object2,object3三個儲存物件經過hash演算法後得到的key1,key2,key3對映到環形Hash空間內,CacheA,CacheB,CacheC,CacheD表示節點伺服器經過一樣的Hash演算法(伺服器一般會採用IP或是Mac地址作為輸入項,採用一定的演算法取Hash值),也對映到環形空間內。這樣儲存物件和伺服器的Hash值處在同一個Hash空間內,路由演算法是順時針查詢最近的伺服器,進行儲存的,比如key1儲存在CacheA中,key2儲存在CacheB中,key3儲存在CacheD中。
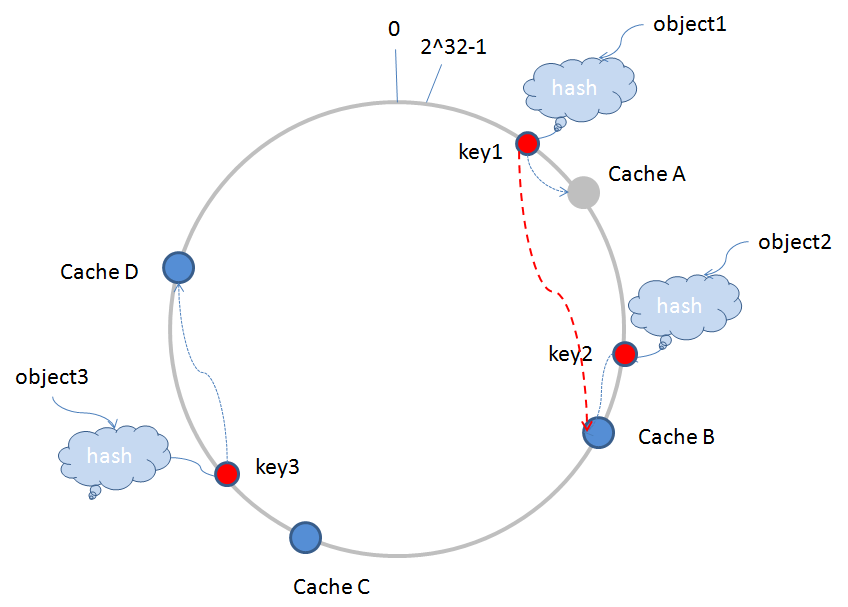
當執行過程中有節點伺服器宕機退出時,假如CacheA宕機退出(圖中變為灰色),伺服器需要更新相應的路由表資訊,原有的key1值根據路由演算法繼續查詢的伺服器,將由CacheA跳到CacheB(如圖中紅色的虛線),這樣,受影響的緩衝片區僅僅為從CacheD到CacheA這一段,其他區域不受影響,如下圖所示:
動態增加伺服器,也是類似。
4、虛擬節點
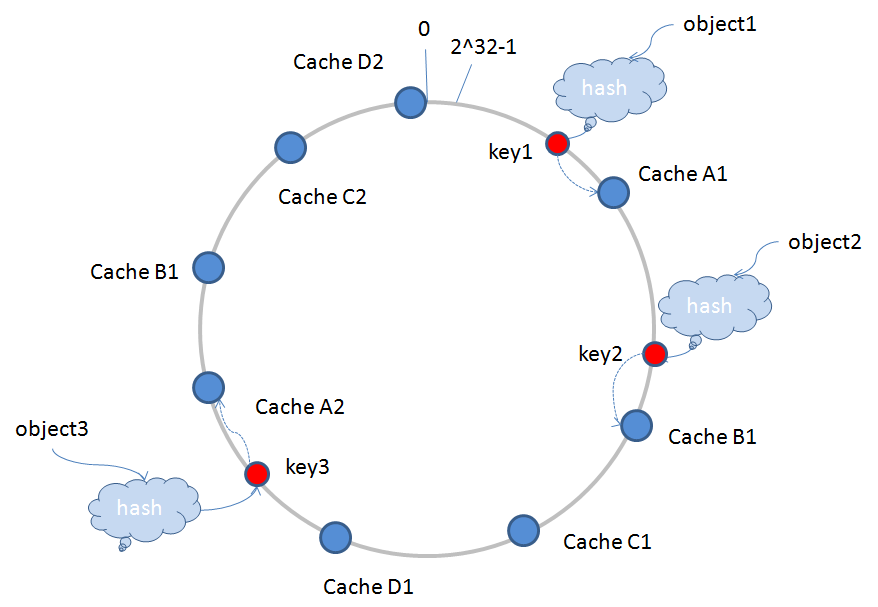
上面的圖例中,CacheA,CacheB,CacheC,CacheD分別表示實際的伺服器節點,會存在一個問題:如果CacheA宕機退出,會導致原有CacheA承擔的儲存任務全部會積壓在CacheB上面,這樣很容易導致CacheB因為負荷過重也宕機了,然後把CacheA,CacheB的儲存任務推給CacheC,如此一來,可能會誘發“雪崩”現象,導致所有伺服器節點全部宕機。為了排除這一隱患,引入虛擬節點。
虛擬節點是實際節點在Hash空間的複製品(replica),一個實際節點對應了若干個“虛擬節點”,這個對應個數也成為“複製個數”,“虛擬節點”在Hash空間中以Hash值排列,對映關係就由{物件->節點}轉換到了{物件->虛擬節點->實際節點}。
有兩個減緩“雪崩”現象的原因:
1)虛擬節點經過一定的演算法,可以做到在環形Hash空間內交叉排列,這樣就可以分攤宕機帶來的儲存壓力。
2)虛擬節點數量要比實際節點多,這樣可以使環形Hash空間每個虛擬節點負責儲存的區域變小,即單個節點儲存負荷量變小,一個節點宕機,推給下一個節點的負荷會更小。
這樣就能更好地保證整體執行穩定,如下圖所示CacheA1,CacheA2等表示:
四、Memcache客戶端有關一致性Hash的實現
1、客戶端初始化過程
在SchoonerSockIOPool類中的initialize()方法,原始碼如下:
/**
* Initializes the pool.
*/
public void initialize() {
initDeadLock.lock();
try {
// if servers is not set, or it empty, then
// throw a runtime exception
if (servers == null || servers.length <= 0) {
log.error("++++ trying to initialize with no servers");
throw new IllegalStateException(
"++++ trying to initialize with no servers");
}
// pools
socketPool = new HashMap<String, GenericObjectPool>(servers.length);
hostDead = new ConcurrentHashMap<String, Date>();
hostDeadDur = new ConcurrentHashMap<String, Long>();
// only create up to maxCreate connections at once
// initalize our internal hashing structures
if (this.hashingAlg == CONSISTENT_HASH)
populateConsistentBuckets();
else
populateBuckets();
// mark pool as initialized
this.initialized = true;
} finally {
initDeadLock.unlock();
}
}
有一個很明顯的分支,一致性Hash呼叫populateConsistentBuckets()方法,其他三個Hash演算法呼叫populateBuckets()方法,前面已經講過其他三個Hash演算法的邏輯,這裡重點講解一致性Hash,populateConsistentBuckets()方法原始碼如下:
private void populateConsistentBuckets() {
// store buckets in tree map
consistentBuckets = new TreeMap<Long, String>();
MessageDigest md5 = MD5.get();
if (this.totalWeight <= 0 && this.weights != null) {
for (int i = 0; i < this.weights.length; i++)
this.totalWeight += (this.weights[i] == null) ? 1
: this.weights[i];
} else if (this.weights == null) {
this.totalWeight = this.servers.length;
}
for (int i = 0; i < servers.length; i++) {
int thisWeight = 1;
if (this.weights != null && this.weights[i] != null)
thisWeight = this.weights[i];
double factor = Math
.floor(((double) (40 * this.servers.length * thisWeight))
/ (double) this.totalWeight);
for (long j = 0; j < factor; j++) {
byte[] d = md5.digest((servers[i] + "-" + j).getBytes());
for (int h = 0; h < 4; h++) {
Long k = ((long) (d[3 + h * 4] & 0xFF) << 24)
| ((long) (d[2 + h * 4] & 0xFF) << 16)
| ((long) (d[1 + h * 4] & 0xFF) << 8)
| ((long) (d[0 + h * 4] & 0xFF));
consistentBuckets.put(k, servers[i]);
}
}
// Create a socket pool for each host
// Create an object pool to contain our active connections
GenericObjectPool gop;
SchoonerSockIOFactory factory;
if (authInfo != null) {
factory = new AuthSchoonerSockIOFactory(servers[i], isTcp,
bufferSize, socketTO, socketConnectTO, nagle, authInfo);
} else {
factory = new SchoonerSockIOFactory(servers[i], isTcp,
bufferSize, socketTO, socketConnectTO, nagle);
}
gop = new GenericObjectPool(factory, maxConn,
GenericObjectPool.WHEN_EXHAUSTED_BLOCK, maxIdle, maxConn);
factory.setSockets(gop);
socketPool.put(servers[i], gop);
}
}
如上程式碼我認為可以分成三部分:
1)計算服務端節點權重之和(totalWeight);
2)factor的計算,作為生成虛擬節點數量的因子;
3)建立 GenericObjectPool物件池,這段邏輯四個Hash演算法都是一樣處理的。
這裡我們重點看一下第二部分,注意一下factor的生成:
double factor = Math.floor(((double) (40 * this.servers.length * thisWeight))
/ (double) this.totalWeight);
根據權重的比例,計算factor因子,注意所有服務端節點的factor總和,會小於等於40 * this.servers.length。例如,兩個服務端節點,factor總和會小於等於80。
而每一次factor迴圈時,拼接的服務端節點資訊(這裡的格式是ip:port-0,ip:port-1,ip:port-2,ip:port-3等),經過MD5加密得到一個16位的byte[],又會拆分成四個一組,共有四組,即byte[0],byte[1],byte[2],byte[3],作為一組,分別移位得到小於2^32大小的Long值,剩餘組依次類推,這個就是上文提到的伺服器資訊對映到環形Hash空間內和虛擬節點的建立過程。
這裡需要注意一個問題:為什麼byte[3]要左移24位,byte[2]要左移16位,byte[1]要左移8位,byte[1]不移位?
因為環形Hash空間的大小為2^32-1,只有這樣按24,16,8,0進行左移,才能保證伺服器是基本均勻地對映在環形空間內,0–2^32各個區間都能分配到,這樣才能更好的滿足Hash平衡性。
我們做一個最簡單的算術:
假設有2個服務端節點,不設定權重,factor總和為80,這樣共能生成虛擬節點80*4=320個,2^32 - 1 = 4294967295(4G),所以一個虛擬節點負責的緩衝區間平均大約有2^32/320=13421772(12.8M)空間大小(這裡要注意一下,每個虛擬節點負責的緩衝區間大小並不是均等的,均等是最理想的情況),設定了權重的話,虛擬節點負責的緩衝區間大於或等於12.8M。
這樣,初始化過程中就完成了伺服器資訊到環形Hash空間的對映過程。
2、set/get操作
閱讀過前面文章就可以知道,memcache客戶端在set/get操作時,定址的演算法是一樣的,在SchoonerSockIOPool類中的getBucket ()方法,原始碼如下所示:
private final long getBucket(String key, Integer hashCode) {
long hc = getHash(key, hashCode);
if (this.hashingAlg == CONSISTENT_HASH) {
return findPointFor(hc);
} else {
long bucket = hc % buckets.size();
if (bucket < 0)
bucket *= -1;
return bucket;
}
}
先看一下快取物件key求hash的演算法,這裡我們看一致性Hash的求法:
/**
* Internal private hashing method.
*
* MD5 based hash algorithm for use in the consistent hashing approach.
*
* @param key
* @return
*/
private static long md5HashingAlg(String key) {
MessageDigest md5 = MD5.get();
md5.reset();
md5.update(key.getBytes());
byte[] bKey = md5.digest();
long res = ((long) (bKey[3] & 0xFF) << 24)
| ((long) (bKey[2] & 0xFF) << 16)
| ((long) (bKey[1] & 0xFF) << 8) | (long) (bKey[0] & 0xFF);
return res;
}
跟上面的移位操作很像,也是通過MD5得到16位的byte[],取前面四個元素進行移位,得到hash值。
得到hash值後,我們往下看,一致性Hash呼叫findPointFor(),其他的三個演算法直接線性求模,findPointFor()原始碼如下:
/**
* Gets the first available key equal or above the given one, if none found,
* returns the first k in the bucket
*
* @param k
* key
* @return
*/
private final Long findPointFor(Long hv) {
SortedMap<Long, String> tmap = this. consistentBuckets.tailMap(hv);
return (tmap.isEmpty()) ? this. consistentBuckets.firstKey() : tmap
.firstKey();
}
方法很簡單,直接使用TreeMap集合,呼叫tailMap方法,得到一個TreeMap物件的分割槽檢視,這個分割槽檢視集合裡物件的key值,都要比當前傳入的hash值大,注意一下這個集合檢視,是關聯原有的TreeMap物件的,修改檢視也會導致原有物件被修改。
consistentBuckets集合裡儲存的是虛擬節點的資訊,tmap呼叫firstKey(),意思是取比當前hash值大的元素,但這個元素是分割槽檢視集合裡面最小的,這個就是一致性Hash的路由演算法實現,很神奇吧?就一句話。
現在已經很明瞭了,TreeMap集合物件就是前面所說的環形Hash空間,但環形又是怎麼實現的呢?
我們再看一下return語句這一行,如果分割槽檢視為空,就從原始的集合物件裡取一個最小的元素,這個元素是整個集合中最小的元素,那麼分割槽檢視什麼時候會是空?只有當前hash值已經比TreeMap集合中最大元素還大時,才會為空,意味著當前Hash是最接近2^32的值了,這種情況就取從0開始,一個最小元素的虛擬節點,這樣就完成了環形的特性。
五、FAQ
Q1:虛擬節點Hash值計算時,是把16位的資料拆分成4個一組,這樣會不會導致Hash衝突?
A1:目前MD5可以保證唯一性,即16位的byte[]肯定是唯一的,但拆分的四組,能否保證也是唯一,這個很難確定,但應該衝突的概率不高,不過就算有衝突,也只是少了一個虛擬節點而已,並不會造成多大影響。
Q2:快取物件key的hash演算法也是這樣只取前面4位,會不會有衝突?
A2:原因如上,這個問題要查證,猜想只要兩個不同的物件,如果MD5值的前面4位相等,就能證明這個hash演算法存在不足,若有精通MD5演算法的童鞋,請幫忙指點此疑問,不勝感激。
Q3:Memcache客戶端中會不會出現動態增加/刪除服務端節點的情況?
A3:經查閱客戶端的原始碼,在初始化過程中,維護服務端資訊的集合以及儲存虛擬節點的集合就已經固定,set/get操作過程中不會對這兩個集合的元素進行增刪,只有在shutdown時,會清空這兩個集合。如果因為這樣你認為一致性Hash用處不大,你就大錯特錯了,因為客戶端是可以shutdown再初始化的,比如,我動態增加了一些服務端節點,雖然客戶端不提供方法讓我熱載入節點,但我可以先呼叫shutdown方法,再呼叫initialize方法的,讓客戶端重新載入配置檔案,若是使用線性求模Hash,那麼很多快取物件將不可再用,這樣一致性Hash的威力就體現出來了。