
spark rdd aggregate (python語言)
阿新 • • 發佈:2018-11-01
aggregate
(
zeroValue
,
seqOp
,
combOp
)
seqOp操作會聚合各分割槽中的元素,然後combOp操作把所有分割槽的聚合結果再次聚合,兩個操作的初始值都是zeroValue. seqOp的操作是遍歷分割槽中的所有元素(y),第一個y跟zeroValue做操作,結果再為與第二個y做操作,直到遍歷完整個分割槽。combOp操作是把各分割槽聚合的結果,再聚合。aggregate函式返回一個跟RDD不同型別的值。因此,需要一個操作seqOp來把分割槽中的元素y合併成一個x,另外一個操作combOp把所有x(seqOp的結果)聚合。 ![]()

combOp的操作: y是上一輪運算的x,這裡即時(10,4) ![]()
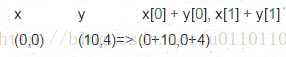
seqOp= (lambda x, y: (x[0]+ y, x[1]+1))
combOp = (lambda x, y: (x[0]+ y[0], x[1]+ y[1]))
sc.parallelize([1,2,3,4]).aggregate((0,0), seqOp, combOp)
(10, 4)combOp的操作: y是上一輪運算的x,這裡即時(10,4)