
python踩過的一些坑
找完工作,又開始忙於做畢設,很久沒更新部落格了,不過部落格新上線的這個新介面太不好用了,分類下只有兩篇文章,每次點選進去都出現很多篇其他類的,每次找一篇博文都要翻很久。體驗真是極差。
廢話不多說,先記幾個做畢設過程中發現的小坑
1、jieba分詞生成迭代器,在第二次for迴圈會失效
測試程式碼:
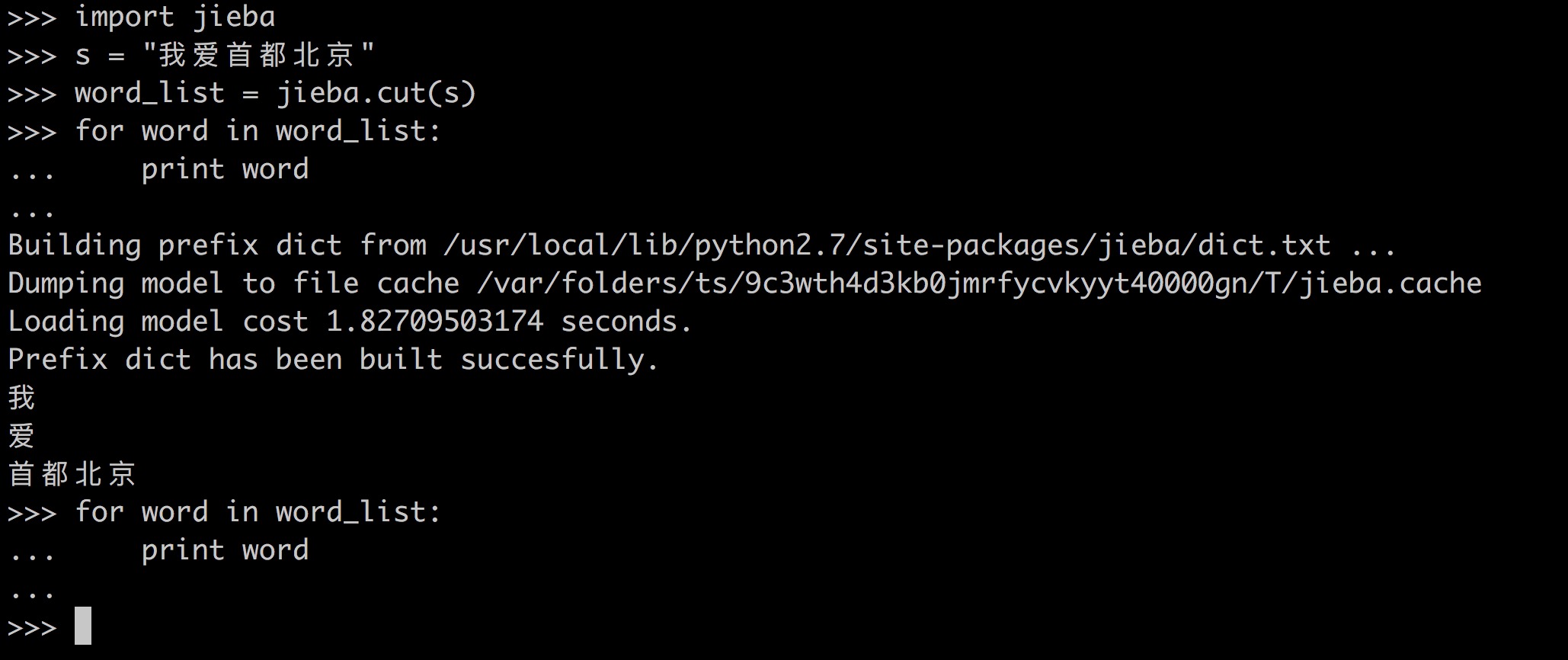
用jieba分詞生成的word_list是個迭代器,第二個for裡面就已經失效了,所以什麼都打印不出來,所以為了讓它不失效,用word_list1 = list(word_list)將其轉化為list即可。
2、list在生成二維陣列時,注意值的淺拷貝
問題發現:
>>> a = [[0] * 3] * 3
>>> a
[[0, 0, 0], [0, 0, 0], [0, 0, 0]]
>>> a[1][1] = 1
>>> a
[[0, 1, 0], [0, 1, 0], [0, 1, 0]]
>>>建立了一個3*3的二維陣列a,初始化所有值都為0,現在想將a[1][1]值改為1,發現所有行的下標為1的值都改為了1
原因:[0]*3是生成一個1*3的一維陣列,初始化所有值為0,現在對這個一維陣列再*3,企圖生成一個二維陣列時,實際上用到的是淺拷貝,就是說這三個[0]*3用到的一個記憶體,所以任何一維陣列中有值修改了,另外兩個一維陣列中對應地方的值都會跟著變(因為用的是一個記憶體,可以理解為本來就是指向同一個數)。
正確的生成二維陣列的方式如下:
>>> a = [[] for i in range(3)]
>>> a
[[], [], []]
>>> a[0].append(0)
>>> a[1].append(0)
>>> a[2].append(0)
>>> a
[[0], [0], [0]]
>>> a[1][0] = 1
>>> a
[[0], [1], [0]]3、在python的工程中,檔案的命名千萬不要使用包的名字。當你出現報錯提示你import的包不存在時,看看你的檔案命名是否有問題!
4、處理微博資料時,在遇到表情時,utf-8編碼的文字是可以打印出來不報錯的,但是在儲存到資料庫中會報錯。這時需要對其進行處理
處理方案是:將其先通過encode轉化為gbk編碼,因為gbk編碼不能表示表情,在轉碼時會報錯。選擇errors = 'ignore',然後再decode回utf-8,這時文字中表情已經去掉了
str = str.encode("gbk", errors="ignore")
str = str.decode("gbk")在用到
str.encode(encoding='UTF-8',errors='strict')
這個函式時,如果想直接將表情從文字中去掉,選擇errors='ignore'即可。
errors引數如下:
'ignore', 'replace', 'xmlcharrefreplace', 'backslashreplace' 以及通過 codecs.register_error() 註冊的任何值。
可參考網址:http://www.runoob.com/python/att-string-encode.html