
源碼之ConcurrentHashMap
我們平常使用的很多的是HashMap,但是在多線程並發情況下是非安全的,雖然HashTable和Collections.synchronizedMap(hashMap)能夠解決並發安全問題,但是這兩種方式都是對整個hash表進行讀寫加鎖,其性能可想而知。所以出現了CurrentHashMap解決並發和性能問題。JDK7\JDK8中因為實現有很大差別,所以我們需要深入去進行對比,分析兩個版本分別實現的底層原理。
JDK1.7CurrentHashMap邏輯結構圖
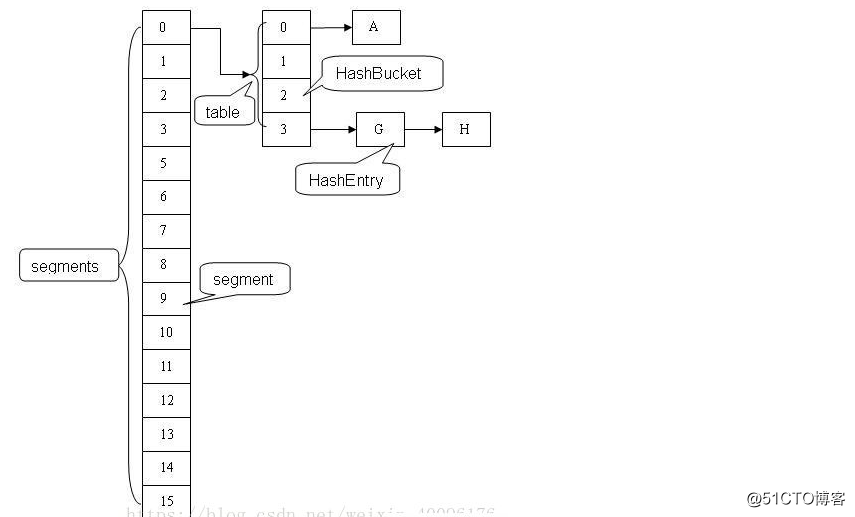
說明:
ConcurrentHashMap采用 分段鎖的機制,實現並發的更新操作,底層采用數組+鏈表的存儲結構。
其包含兩個核心靜態內部類 Segment和HashEntry。
Segment繼承ReentrantLock用來充當鎖的角色,每個 Segment 對象守護每個散列映射表的若幹個桶。
HashEntry 用來封裝映射表的鍵 / 值對;
每個桶是由若幹個 HashEntry 對象鏈接起來的鏈表。
在JDK1.7中采用的是Segment + HashEntry,而Segment繼承了ReentrantLock,所以自帶鎖功能。
JDK1.8CurrentHashMap邏輯結構圖
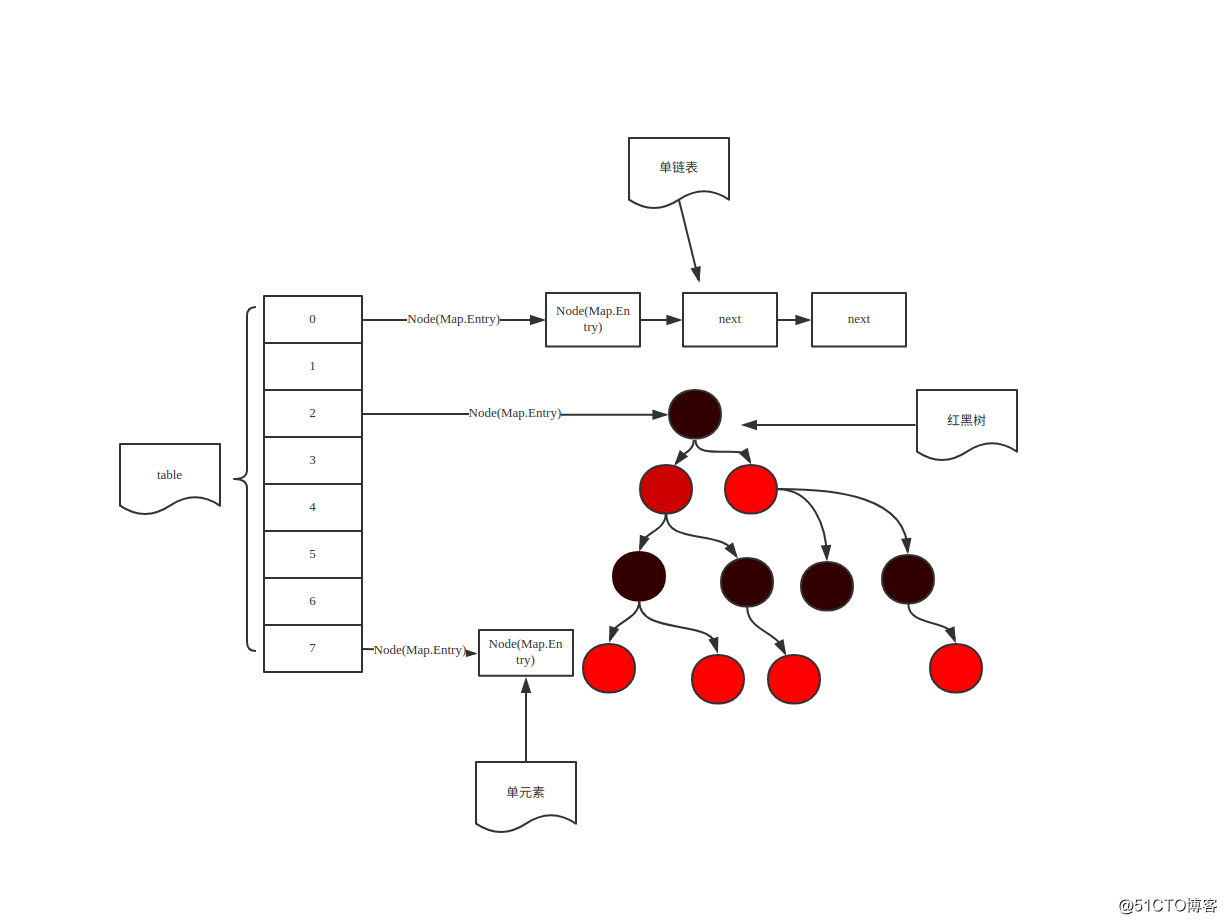
說明:
在開始之前,有些重要的概念需要介紹一下:
table:默認為null,初始化發生在第一次插入操作,默認大小為16的數組,用來存儲Node節點數據,擴容時大小總是2的冪次方。
nextTable:默認為null,擴容時新生成的數組,其大小為原數組的兩倍。
-1 代表table正在初始化
-N 表示有N-1個線程正在進行擴容操作
其余情況:
1、如果table未初始化,表示table需要初始化的大小。
2、如果table初始化完成,表示table的容量,默認是table大小的0.75倍,居然用這個公式算0.75(n - (n >>> 2))。
Node:保存key,value及key的hash值的數據結構。
在jdk1.8裏面CurrentHashMap的實現采用的是Node + CAS + Synchronized,而取消掉了Segment+HashEntry的實現方式。
// ForwardingNode:一個特殊的Node節點,hash值為-1,其中存儲nextTable的引用。
final class ForwardingNode<K,V> extends Node<K,V> {
final Node<K,V>[] nextTable;
ForwardingNode(Node<K,V>[] tab) {
super(MOVED, null, null, null);
this.nextTable = tab;
}
}
// 只有table發生擴容的時候,ForwardingNode才會發揮作用,
// 作為一個占位符放在table中表示當前節點為null或則已經被移動。
源碼分析
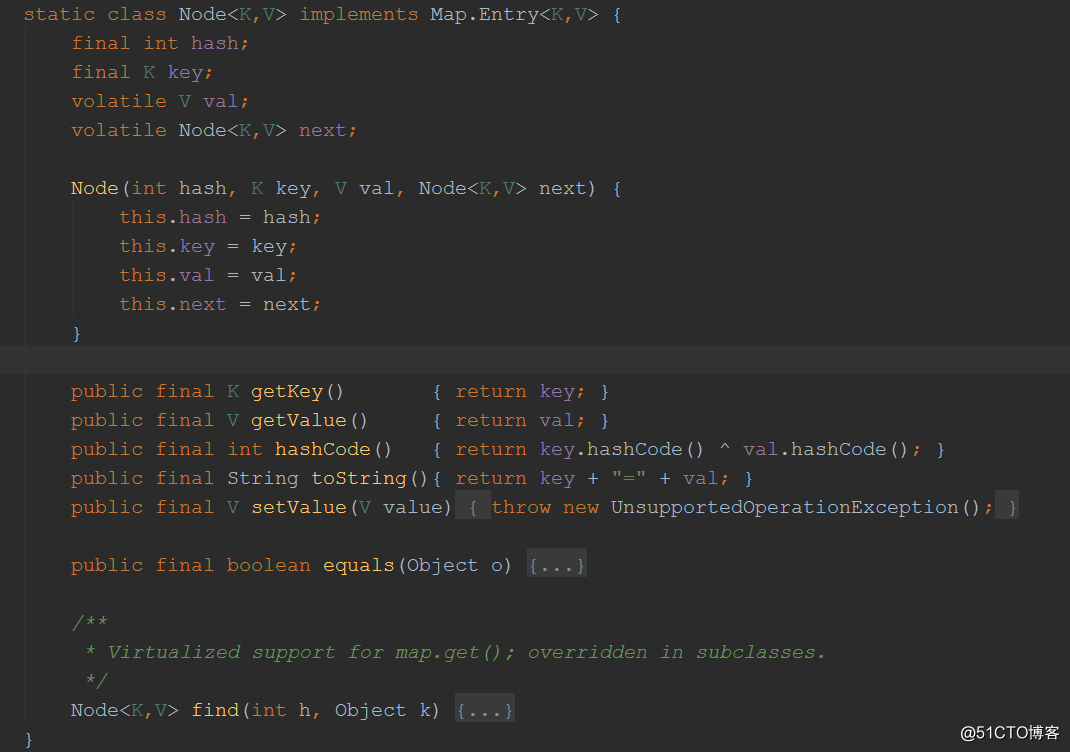
Node節點類中,next、value都是volatile,保證並發的可見性。

在ConcurrentHashMap中沒有hash函數,取而代之的是spread函數,但功能和hash函數一樣。
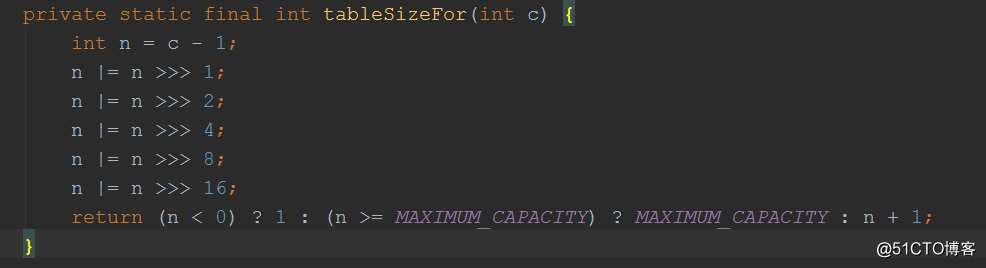
tableSizeFor是給table是設置容量的,你傳入的容量並不會真的設置為該容量,而是會進行位運算,使得容量一定是2的正整數次冪。
構造函數
public ConcurrentHashMap() { }
public ConcurrentHashMap(int initialCapacity) {
if (initialCapacity < 0)
throw new IllegalArgumentException();
int cap = ((initialCapacity >= (MAXIMUM_CAPACITY >>> 1)) ?
MAXIMUM_CAPACITY :
tableSizeFor(initialCapacity + (initialCapacity >>> 1) + 1));
this.sizeCtl = cap;
}
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public ConcurrentHashMap(int initialCapacity, float loadFactor) {
this(initialCapacity, loadFactor, 1);
}
public ConcurrentHashMap(int initialCapacity,
float loadFactor, int concurrencyLevel) {
if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0)
throw new IllegalArgumentException();
if (initialCapacity < concurrencyLevel) // Use at least as many bins
initialCapacity = concurrencyLevel; // as estimated threads
long size = (long)(1.0 + (long)initialCapacity / loadFactor);
int cap = (size >= (long)MAXIMUM_CAPACITY) ?
MAXIMUM_CAPACITY : tableSizeFor((int)size);
this.sizeCtl = cap;
}除了使用集合初始化,其他的構造函數都沒有真正的去初始化hash表,只是設置了一些參數。當第一個元素被插入hash表時進行初始化操作。
集合構造table
public ConcurrentHashMap(Map<? extends K, ? extends V> m) {
this.sizeCtl = DEFAULT_CAPACITY;
putAll(m);
}
public void putAll(Map<? extends K, ? extends V> m) {
tryPresize(m.size());
for (Map.Entry<? extends K, ? extends V> e : m.entrySet())
putVal(e.getKey(), e.getValue(), false);
}
// 分配table空間
private final void tryPresize(int size) {
// 設置容量
int c = (size >= (MAXIMUM_CAPACITY >>> 1)) ? MAXIMUM_CAPACITY :
tableSizeFor(size + (size >>> 1) + 1);
int sc;
// 如果sizeCtl > 0
while ((sc = sizeCtl) >= 0) {
Node<K,V>[] tab = table; int n;
// 如果table還未初始化
if (tab == null || (n = tab.length) == 0) {
n = (sc > c) ? sc : c; // sizeCtl存放的是當前容量
// 設置sizeCtl為-1,進行擴容
if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) {
try {
if (table == tab) {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n];
table = nt;
sc = n - (n >>> 2);
}
} finally {
sizeCtl = sc;
}
}
}
else if (c <= sc || n >= MAXIMUM_CAPACITY)
break;
else if (tab == table) {
int rs = resizeStamp(n);
if (sc < 0) {
Node<K,V>[] nt;
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 ||
sc == rs + MAX_RESIZERS || (nt = nextTable) == null ||
transferIndex <= 0)
break;
if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1))
transfer(tab, nt);
}
else if (U.compareAndSwapInt(this, SIZECTL, sc,
(rs << RESIZE_STAMP_SHIFT) + 2))
transfer(tab, null);
}
}
}
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) {
int n = tab.length, stride;
if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE)
stride = MIN_TRANSFER_STRIDE; // subdivide range
if (nextTab == null) { // initiating
try {
@SuppressWarnings("unchecked")
Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1];
nextTab = nt;
} catch (Throwable ex) { // try to cope with OOME
sizeCtl = Integer.MAX_VALUE;
return;
}
nextTable = nextTab;
transferIndex = n;
}
int nextn = nextTab.length;
ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab);
boolean advance = true;
boolean finishing = false; // to ensure sweep before committing nextTab
for (int i = 0, bound = 0;;) {
Node<K,V> f; int fh;
while (advance) {
int nextIndex, nextBound;
if (--i >= bound || finishing)
advance = false;
else if ((nextIndex = transferIndex) <= 0) {
i = -1;
advance = false;
}
else if (U.compareAndSwapInt
(this, TRANSFERINDEX, nextIndex,
nextBound = (nextIndex > stride ?
nextIndex - stride : 0))) {
bound = nextBound;
i = nextIndex - 1;
advance = false;
}
}
if (i < 0 || i >= n || i + n >= nextn) {
int sc;
if (finishing) {
nextTable = null;
table = nextTab;
sizeCtl = (n << 1) - (n >>> 1);
return;
}
if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) {
if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT)
return;
finishing = advance = true;
i = n; // recheck before commit
}
}
else if ((f = tabAt(tab, i)) == null)
advance = casTabAt(tab, i, null, fwd);
else if ((fh = f.hash) == MOVED)
advance = true; // already processed
else {
synchronized (f) {
if (tabAt(tab, i) == f) {
Node<K,V> ln, hn;
if (fh >= 0) {
int runBit = fh & n;
Node<K,V> lastRun = f;
for (Node<K,V> p = f.next; p != null; p = p.next) {
int b = p.hash & n;
if (b != runBit) {
runBit = b;
lastRun = p;
}
}
if (runBit == 0) {
ln = lastRun;
hn = null;
}
else {
hn = lastRun;
ln = null;
}
for (Node<K,V> p = f; p != lastRun; p = p.next) {
int ph = p.hash; K pk = p.key; V pv = p.val;
if ((ph & n) == 0)
ln = new Node<K,V>(ph, pk, pv, ln);
else
hn = new Node<K,V>(ph, pk, pv, hn);
}
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
else if (f instanceof TreeBin) {
TreeBin<K,V> t = (TreeBin<K,V>)f;
TreeNode<K,V> lo = null, loTail = null;
TreeNode<K,V> hi = null, hiTail = null;
int lc = 0, hc = 0;
for (Node<K,V> e = t.first; e != null; e = e.next) {
int h = e.hash;
TreeNode<K,V> p = new TreeNode<K,V>
(h, e.key, e.val, null, null);
if ((h & n) == 0) {
if ((p.prev = loTail) == null)
lo = p;
else
loTail.next = p;
loTail = p;
++lc;
}
else {
if ((p.prev = hiTail) == null)
hi = p;
else
hiTail.next = p;
hiTail = p;
++hc;
}
}
ln = (lc <= UNTREEIFY_THRESHOLD) ? untreeify(lo) :
(hc != 0) ? new TreeBin<K,V>(lo) : t;
hn = (hc <= UNTREEIFY_THRESHOLD) ? untreeify(hi) :
(lc != 0) ? new TreeBin<K,V>(hi) : t;
setTabAt(nextTab, i, ln);
setTabAt(nextTab, i + n, hn);
setTabAt(tab, i, fwd);
advance = true;
}
}
}
}
}
}tryPreSize函數進行table初始化,
transfer函數:
1.計算每個線程可以處理的桶區間。默認 16.
2.初始化臨時變量 nextTable,擴容 2 倍。
3.死循環,計算下標。完成總體判斷。
4.如果桶內有數據,同步轉移數據。通常會像鏈表拆成 2 份
put方法
public V put(K key, V value) {
return putVal(key, value, false);
}
/** Implementation for put and putIfAbsent */
final V putVal(K key, V value, boolean onlyIfAbsent) {
if (key == null || value == null) throw new NullPointerException();
int hash = spread(key.hashCode()); //兩次hash,減少hash沖突,可以均勻分布
int binCount = 0;
for (Node<K,V>[] tab = table;;) { //對這個table進行叠代
Node<K,V> f; int n, i, fh;
//這裏就是上面構造方法沒有進行初始化,在這裏進行判斷,
// 為null就調用initTable進行初始化,屬於懶漢模式初始化
if (tab == null || (n = tab.length) == 0)
tab = initTable();
else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {
//如果i位置沒有數據,就直接無鎖插入
if (casTabAt(tab, i, null,
new Node<K,V>(hash, key, value, null)))
break; // no lock when adding to empty bin
}
else if ((fh = f.hash) == MOVED)//如果在進行擴容,則先進行擴容操作
tab = helpTransfer(tab, f);
else {
V oldVal = null;
//如果以上條件都不滿足,那就要進行加鎖操作,
// 也就是存在hash沖突,鎖住鏈表或者紅黑樹的頭結點
synchronized (f) {
if (tabAt(tab, i) == f) {
if (fh >= 0) { //表示該節點是鏈表結構
binCount = 1;
for (Node<K,V> e = f;; ++binCount) {
K ek;
//這裏涉及到相同的key進行put就會覆蓋原先的value
if (e.hash == hash &&
((ek = e.key) == key ||
(ek != null && key.equals(ek)))) {
oldVal = e.val;
if (!onlyIfAbsent)
e.val = value;
break;
}
Node<K,V> pred = e;
if ((e = e.next) == null) { //插入鏈表尾部
pred.next = new Node<K,V>(hash, key,
value, null);
break;
}
}
}
else if (f instanceof TreeBin) {//紅黑樹結構
Node<K,V> p;
binCount = 2;
//紅黑樹結構旋轉插入
if ((p = ((TreeBin<K,V>)f).putTreeVal(hash, key,
value)) != null) {
oldVal = p.val;
if (!onlyIfAbsent)
p.val = value;
}
}
}
}
if (binCount != 0) { //如果鏈表的長度大於8時就會進行紅黑樹的轉換
if (binCount >= TREEIFY_THRESHOLD)
treeifyBin(tab, i);
if (oldVal != null)
return oldVal;
break;
}
}
}
addCount(1L, binCount);//統計size,並且檢查是否需要擴容
return null;
}1.key\value都不能為null;
2.hash值為-1時表示當前正在擴容,那麽調用helpTransfer輔助擴容
3.如果hash發生沖突且不滿足條件,使用synchronized給f加內部鎖
4.binCount如果達到TREEIFY_THRESHOLD,那麽轉成紅黑樹,然後統計判斷是否擴容
TreeNode結構
static final class TreeNode<K,V> extends Node<K,V> {
//樹形結構的屬性定義
TreeNode<K,V> parent; // red-black tree links
TreeNode<K,V> left;
TreeNode<K,V> right;
TreeNode<K,V> prev; // needed to unlink next upon deletion
boolean red; //標誌紅黑樹的紅節點
TreeNode(int hash, K key, V val, Node<K,V> next,
TreeNode<K,V> parent) {
super(hash, key, val, next);
this.parent = parent;
}
Node<K,V> find(int h, Object k) {
return findTreeNode(h, k, null);
}
//根據key查找 從根節點開始找出相應的TreeNode,
final TreeNode<K,V> findTreeNode(int h, Object k, Class<?> kc) {
if (k != null) {
TreeNode<K,V> p = this;
do {
int ph, dir; K pk; TreeNode<K,V> q;
TreeNode<K,V> pl = p.left, pr = p.right;
if ((ph = p.hash) > h)
p = pl;
else if (ph < h)
p = pr;
else if ((pk = p.key) == k || (pk != null && k.equals(pk)))
return p;
else if (pl == null)
p = pr;
else if (pr == null)
p = pl;
else if ((kc != null ||
(kc = comparableClassFor(k)) != null) &&
(dir = compareComparables(kc, k, pk)) != 0)
p = (dir < 0) ? pl : pr;
else if ((q = pr.findTreeNode(h, k, kc)) != null)
return q;
else
p = pl;
} while (p != null);
}
return null;
}
}TreeNode繼承與Node,但是數據結構換成了二叉樹結構,它是紅黑樹的數據的存儲結構,用於紅黑樹中存儲數據,當鏈表的節點數大於8時會轉換成紅黑樹的結構,他就是通過TreeNode作為存儲結構代替Node來轉換成黑紅樹。
TreeBin
static final class TreeBin<K,V> extends Node<K,V> {
//指向TreeNode列表和根節點
TreeNode<K,V> root;
volatile TreeNode<K,V> first;
volatile Thread waiter;
volatile int lockState;
// 讀寫鎖狀態
static final int WRITER = 1; // 獲取寫鎖的狀態
static final int WAITER = 2; // 等待寫鎖的狀態
static final int READER = 4; // 增加數據時讀鎖的狀態
/**
* 初始化紅黑樹
*/
TreeBin(TreeNode<K,V> b) {
super(TREEBIN, null, null, null);
this.first = b;
TreeNode<K,V> r = null;
for (TreeNode<K,V> x = b, next; x != null; x = next) {
next = (TreeNode<K,V>)x.next;
x.left = x.right = null;
if (r == null) {
x.parent = null;
x.red = false;
r = x;
}
else {
K k = x.key;
int h = x.hash;
Class<?> kc = null;
for (TreeNode<K,V> p = r;;) {
int dir, ph;
K pk = p.key;
if ((ph = p.hash) > h)
dir = -1;
else if (ph < h)
dir = 1;
else if ((kc == null &&
(kc = comparableClassFor(k)) == null) ||
(dir = compareComparables(kc, k, pk)) == 0)
dir = tieBreakOrder(k, pk);
TreeNode<K,V> xp = p;
if ((p = (dir <= 0) ? p.left : p.right) == null) {
x.parent = xp;
if (dir <= 0)
xp.left = x;
else
xp.right = x;
r = balanceInsertion(r, x);
break;
}
}
}
}
this.root = r;
assert checkInvariants(root);
}
......
}TreeBin從字面含義中可以理解為存儲樹形結構的容器,而樹形結構就是指TreeNode,所以TreeBin就是封裝TreeNode的容器,它提供轉換黑紅樹的一些條件和鎖的控制。
get方法
public V get(Object key) {
Node<K,V>[] tab; Node<K,V> e, p; int n, eh; K ek;
int h = spread(key.hashCode()); //計算兩次hash
if ((tab = table) != null && (n = tab.length) > 0 &&
(e = tabAt(tab, (n - 1) & h)) != null) {//讀取首節點的Node元素
if ((eh = e.hash) == h) { //如果該節點就是首節點就返回
if ((ek = e.key) == key || (ek != null && key.equals(ek)))
return e.val;
}
//hash值為負值表示正在擴容,這個時候查的是ForwardingNode的find方法來定位到nextTable來
//查找,查找到就返回
else if (eh < 0)
return (p = e.find(h, key)) != null ? p.val : null;
while ((e = e.next) != null) {//既不是首節點也不是ForwardingNode,那就往下遍歷
if (e.hash == h &&
((ek = e.key) == key || (ek != null && key.equals(ek))))
return e.val;
}
}
return null;
}ConcurrentHashMap的get操作的流程很簡單,也很清晰,可以分為三個步驟來描述
計算hash值,定位到該table索引位置,如果是首節點符合就返回
如果遇到擴容的時候,會調用標誌正在擴容節點ForwardingNode的find方法,查找該節點,匹配就返回
以上都不符合的話,就往下遍歷節點,匹配就返回,否則最後就返回null。
總結思考
1.JDK1.8的實現降低鎖的粒度,JDK1.7版本鎖的粒度是基於Segment的,包含多個HashEntry,而JDK1.8鎖的粒度就是HashEntry(首節點)。
2.JDK1.8版本的數據結構變得更加簡單,使得操作也更加清晰流暢,因為已經使用synchronized來進行同步,所以不需要分段鎖的概念,也就不需要Segment這種數據結構了,由於粒度的降低,實現的復雜度也增加了。
3.JDK1.8使用紅黑樹來優化鏈表,基於長度很長的鏈表的遍歷是一個很漫長的過程,而紅黑樹的遍歷效率是很快的,代替一定閾值的鏈表,這樣形成一個最佳拍檔。
4.JDK1.8為什麽使用內置鎖synchronized來代替重入鎖ReentrantLock,我覺得有以下幾點:
因為粒度降低了,在相對而言的低粒度加鎖方式,synchronized並不比ReentrantLock差,在粗粒度加鎖中ReentrantLock可能通過Condition來控制各個低粒度的邊界,更加的靈活,而在低粒度中,Condition的優勢就沒有了。
JVM的開發團隊從來都沒有放棄synchronized,而且基於JVM的synchronized優化空間更大,使用內嵌的關鍵字比使用API更加自然。
在大量的數據操作下,對於JVM的內存壓力,基於API的ReentrantLock會開銷更多的內存,雖然不是瓶頸,但是也是一個選擇依據。
源碼之ConcurrentHashMap