Lucene搜尋引擎-分詞器
文章目錄
官方網站: https://lucene.apache.org/
Lucene初識
Apache頂級開源專案,Lucene-core是一個開放原始碼的全文檢索引擎工具包,但它不是一個完整的全文檢索引擎,而是一個全文檢索引擎的框架,提供了完整的查詢引擎和索引引擎,部分文字分詞引擎(英文與德文兩種西方語言)。Lucene的目的是為軟體開發人員提供一個簡單易用的工具包,以方便的在目標系統中實現全文檢索的功能,或者是以此為基礎建立起完整的全文檢索引擎。現在主流的搜尋引擎Solr、ElasticSearch都是以Lucene為底層框架封裝的。
適用場景
- 在應用中為資料庫中的資料提供全文檢索實現
- 開發獨立的搜尋引擎服務、系統
特性
- 穩定、索引效能高
- 每小時能夠索引150GB以上的資料
- 對記憶體的要求小,只需要1MB的堆記憶體
- 增量索引和批量索引一樣快
- 索引的大小約為索引文字大小的20%~30%
- 高效、準確、高效能的搜尋演算法
- 良好的搜尋排序
- 強大的查詢方式支援:短語查詢、萬用字元查詢、臨近查詢、範圍查詢等
- 支援欄位搜尋(如標題、作者、內容)
- 可根據任意欄位排序
- 支援多個索引查詢結果合併
- 支援更新操作和查詢操作同時進行
- 支援高亮、join、分組結果功能
- 可擴充套件排序模組,內建包含向量空間模型、BM25模型可選
- 可配置儲存引擎
- 跨平臺
- 純java編寫
- 作為Apache開源許可下的開源專案,你可在商業或開源專案中使用
- Lucene有多種語言實現版可選(如C、C++、Python等),不光是Java
Lucene初識
請移步看完這篇文章:
https://blog.csdn.net/chenghui0317/article/details/10052103
一定要看,一定要看,一定要看!重要的事情說三遍!
看完以後絕對會對Lucene有一個全面的認識,Lucene所包含的東西可以歸類為如下三項:
- 分詞器如何進行分詞的
- 索引是如何生成的
- 如何利用分詞器與索引進行搜尋的
分詞器
顧名思義,分詞器是用來分詞的,比如下面一句話:
上海自來水來自海上
經過分詞器後的解析後分為好幾個詞項,如下:
上海、自來水、來自、海上
那麼解析後這麼多的此項有什麼用呢?如何儲存索引才會被搜尋到呢?這裡就要談到反向索引,要談反向索引,先來聊聊正向索引。
正向索引
正向索引,簡單理解其實就是我們做傳統應用時資料庫中儲存記錄的形式,比如:
| 文章ID | 文章標題 | 文章內容 |
|---|---|---|
| 1 | {上海、自來水} | {來自} |
| 2 | {上海} | {來自、海上} |
其中{}部分是表示內容中包含的一些關鍵字。我們很容易發現傳統的儲存形式是:
id --> 詞項
面對這種儲存形式,我們查詢文章標題或者文章內容中是否包含某個詞語的時候,一般只能:
SELECT * FROM TABLE WHERE 文章標題 LIKE '%上海%';
SELECT * FROM TABLE WHERE 文章標題 LIKE '%上海%' OR 文章內容 LIKE '%上海%';
可想而知,在面對大資料的時候,這種查詢效率是極其低下的,甚至無法滿足一些複雜場景,比如:關鍵字高亮、偏移量、詞頻等。這時候就要引入反向索引,專業人做專業事!畢竟資料庫比較適合結構化資料的精確查詢,而不適合半結構化、非結構化資料的模糊查詢及靈活搜尋(特別是資料量大時),無法提供想要 實時性。
反向索引
顧名思義,反向索引是正向索引反著來的,以詞項為主關聯文章ID的形式,如下:
| 詞項 | 標題包含該詞的文章id | 內容包含該詞的文章id |
|---|---|---|
| 上海 | {1,2} | {1,2,7} |
| 自來水 | {1,2,3,4} | {1,2,9} |
我們很容易發現這種的儲存形式是:
詞項 --> id
這種儲存的方式可以讓我們根據查詢的關鍵字很快的找出對應的文章,甚至還可以滿足一些更復雜的場景,比如反向索引還可以記錄詞項出現的次數、出現的位置,如下:
| 詞項 | 標題包含該詞的文章id | 內容包含該詞的文章id |
|---|---|---|
| 上海 | {{1,1,{0}},{2,2,{0,4}}} | {{7,2,{1,6}} |
| 自來水 | {{3,2,{1,5}},{4,1,{2}}} | {{2,1,{0}},{9,3,{1,5,9}}} |
{{2,1,{0}},{9,3,{1,5,9}}}解析:
9:文章id
3:出現次數
{1,5,9}:出現位置
這裡就會提出一個問題,反向索引的資料量會非常大嗎?
英文:所有的英文單詞加起來應該不算多,十幾萬?幾十萬?
中文:中華詞典上的中文單詞總量貌似也就幾十萬
Lucene自帶分詞器
分詞器有多種,有英文分詞器、中文分詞器、其他語言的分詞器等。其中IKAnalyzer是屬於常用的一種中文分詞器。
在講IKAnalyzer之前,先來感受一下Lucene自帶的標準分詞器的效果,直接上程式碼。
- maven工程,pom.xml中引入Lucene核心包
<!-- lucene 核心模組 --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> <version>7.3.0</version> </dependency> <!-- Lucene提供的中文分詞器模組,lucene-analyzers-smartcn --> <dependency> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-smartcn</artifactId> <version>7.3.0</version> </dependency>
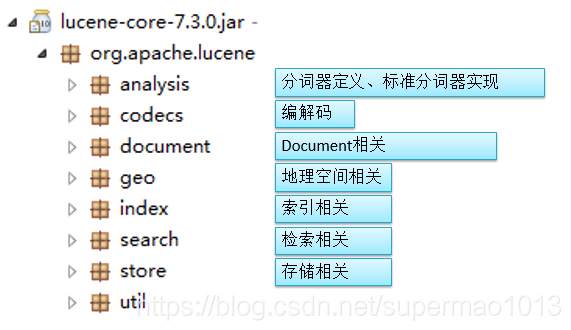
核心包內的各模組功能如下:
- main函式如下
import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer; import org.apache.lucene.analysis.standard.StandardAnalyzer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import java.io.IOException; public class AnalizerTestDemo { private static void doToken(TokenStream ts) throws IOException { ts.reset(); CharTermAttribute cta = ts.getAttribute(CharTermAttribute.class); while (ts.incrementToken()) { System.out.print(cta.toString() + "|"); } System.out.println(); ts.end(); ts.close(); } public static void main(String[] args) throws IOException { String etext = "Analysis is one of the main causes of slow indexing. Simply put, the more you analyze the slower analyze the indexing (in most cases)."; String chineseText = "中華人民共和國簡稱中國。"; //核心包提供的標準分詞器 try { Analyzer ana = new StandardAnalyzer(); TokenStream ts = ana.tokenStream("content", etext); System.out.println("標準分詞器,英文分詞效果:"); doToken(ts); ts = ana.tokenStream("content", chineseText); System.out.println("標準分詞器,中文分詞效果:"); doToken(ts); } catch (IOException e) { e.printStackTrace(); } // smart中文分詞器 try { Analyzer smart = new SmartChineseAnalyzer(); TokenStream ts = smart.tokenStream("content", etext); System.out.println("smart中文分詞器,英文分詞效果:"); doToken(ts); ts = smart.tokenStream("content", chineseText); System.out.println("smart中文分詞器,中文分詞效果:"); doToken(ts); } catch (Exception e) { } } } - 執行結果如下
標準分詞器,英文分詞效果: analysis|one|main|causes|slow|indexing|simply|put|more|you|analyze|slower|analyze|indexing|most|cases| 標準分詞器,中文分詞效果: 中|華|人|民|共|和|國|簡|稱|中|國| smart中文分詞器,英文分詞效果: analysi|is|on|of|the|main|caus|of|slow|index|simpli|put|the|more|you|analyz|the|slower|analyz|the|index|in|most|case| smart中文分詞器,中文分詞效果: 中華人民共和國|簡稱|中國|
可以看出,Lucene自帶的標準分詞器對英文是通過空格進行分詞的,對中文大部分是通過單字進行分詞的,這種分詞效果並不好。
而Lucene自帶的smart分詞器對中文分詞效果很好,但對英文分詞效果不好,因為無法過濾掉停用詞。
停用詞:不需要進行分詞的詞語,無關緊要的詞語,每種語言都有相對應的停用詞
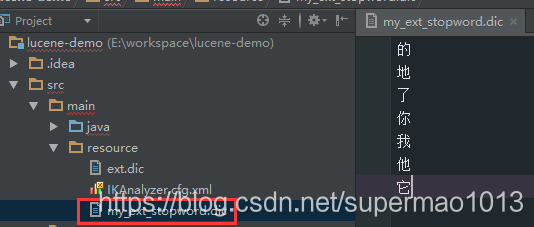
中文停用詞:你、我、它、的、了
英文停用詞:is、the、we、in、of
專案整合IKAnalyzer分詞器
IKAnalyzer是作為Lucene上使用而開發的,後面發展為獨立的分片語件,只提供到Lucene4.0版本的支援,所以如果使用Lucene4.0以後版本的要簡單整合一下IKAnalyzer。
- 第一步:maven工程pom.xml中加入依賴包
<!-- ikanalyzer 中文分詞器 --> <dependency> <groupId>com.janeluo</groupId> <artifactId>ikanalyzer</artifactId> <version>2012_u6</version> <exclusions> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-core</artifactId> </exclusion> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-queryparser</artifactId> </exclusion> <exclusion> <groupId>org.apache.lucene</groupId> <artifactId>lucene-analyzers-common</artifactId> </exclusion> </exclusions> </dependency> - 第二步:重新定義IKAnalyzer
原因:Lucene中的Analyzer類的抽象方法createComponents入參已經發生改變,而當前IK分詞器中繼承Analyzer的類IKAnalyzer重寫該方法時入參是錯誤的,如下:
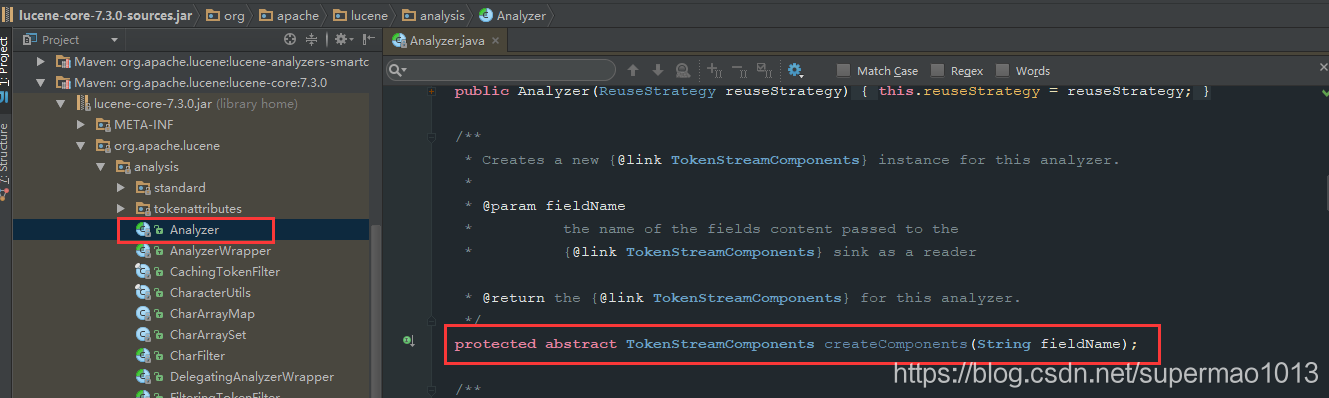

重新定義如下:import org.apache.lucene.analysis.Analyzer; public class IKAnalyzer4Lucene7 extends Analyzer { private boolean useSmart = false; public IKAnalyzer4Lucene7() { this(false); } public IKAnalyzer4Lucene7(boolean useSmart) { super(); this.useSmart = useSmart; } public boolean isUseSmart() { return useSmart; } public void setUseSmart(boolean useSmart) { this.useSmart = useSmart; } @Override protected TokenStreamComponents createComponents(String fieldName) { IKTokenizer4Lucene7 tk = new IKTokenizer4Lucene7(this.useSmart); return new TokenStreamComponents(tk); } }import java.io.IOException; import org.apache.lucene.analysis.Tokenizer; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import org.apache.lucene.analysis.tokenattributes.OffsetAttribute; import org.apache.lucene.analysis.tokenattributes.TypeAttribute; import org.wltea.analyzer.core.IKSegmenter; import org.wltea.analyzer.core.Lexeme; public class IKTokenizer4Lucene7 extends Tokenizer { // IK分詞器實現 private IKSegmenter _IKImplement; // 詞元文字屬性 private final CharTermAttribute termAtt; // 詞元位移屬性 private final OffsetAttribute offsetAtt; // 詞元分類屬性(該屬性分類參考org.wltea.analyzer.core.Lexeme中的分類常量) private final TypeAttribute typeAtt; // 記錄最後一個詞元的結束位置 private int endPosition; /** * @param useSmart */ public IKTokenizer4Lucene7(boolean useSmart) { super(); offsetAtt = addAttribute(OffsetAttribute.class); termAtt = addAttribute(CharTermAttribute.class); typeAtt = addAttribute(TypeAttribute.class); _IKImplement = new IKSegmenter(input, useSmart); } /* * (non-Javadoc) * * @see org.apache.lucene.analysis.TokenStream#incrementToken() */ @Override public boolean incrementToken() throws IOException { // 清除所有的詞元屬性 clearAttributes(); Lexeme nextLexeme = _IKImplement.next(); if (nextLexeme != null) { // 將Lexeme轉成Attributes // 設定詞元文字 termAtt.append(nextLexeme.getLexemeText()); // 設定詞元長度 termAtt.setLength(nextLexeme.getLength()); // 設定詞元位移 offsetAtt.setOffset(nextLexeme.getBeginPosition(), nextLexeme.getEndPosition()); // 記錄分詞的最後位置 endPosition = nextLexeme.getEndPosition(); // 記錄詞元分類 typeAtt.setType(nextLexeme.getLexemeTypeString()); // 返會true告知還有下個詞元 return true; } // 返會false告知詞元輸出完畢 return false; } /* * (non-Javadoc) * * @see org.apache.lucene.analysis.Tokenizer#reset(java.io.Reader) */ @Override public void reset() throws IOException { super.reset(); _IKImplement.reset(input); } @Override public final void end() { // set final offset int finalOffset = correctOffset(this.endPosition); offsetAtt.setOffset(finalOffset, finalOffset); } } - 第三步:測試程式碼如下
import java.io.IOException; import org.apache.lucene.analysis.Analyzer; import org.apache.lucene.analysis.TokenStream; import org.apache.lucene.analysis.tokenattributes.CharTermAttribute; import com.dongnao.lucene.demo.analizer.ik.IKAnalyzer4Lucene7; public class IkAnalyzerTestDemo { private static void doToken(TokenStream ts) throws IOException { ts.reset(); CharTermAttribute cta = ts.getAttribute(CharTermAttribute.class); while (ts.incrementToken()) { System.out.print(cta.toString() + "|"); } System.out.println(); System.out.println(); ts.end(); ts.close(); } public static void main(String[] args) throws IOException { String etext = "Analysis is one of the main causes of slow indexing. Simply put, "; String chineseText = "厲害了我的國一經播出,受到各方好評,強烈激發了國人的愛國之情、自豪感!"; try { // IKAnalyzer 細粒度切分 Analyzer ik = new IKAnalyzer4Lucene7(); TokenStream ts = ik.tokenStream("content", etext); System.out.println("IKAnalyzer中文分詞器 細粒度切分,英文分詞效果:"); doToken(ts); ts = ik.tokenStream("content", chineseText); System.out.println("IKAnalyzer中文分詞器 細粒度切分,中文分詞效果:"); doToken(ts); } catch (Exception e) { } try { // IKAnalyzer 智慧切分 Analyzer ik = new IKAnalyzer4Lucene7(true); TokenStream ts = ik.tokenStream("content", etext); System.out.println("IKAnalyzer中文分詞器 智慧切分,英文分詞效果:"); doToken(ts); ts = ik.tokenStream("content", chineseText); System.out.println("IKAnalyzer中文分詞器 智慧切分,中文分詞效果:"); doToken(ts); } catch (Exception e) { } } } - 測試結果如下
IKAnalyzer中文分詞器 細粒度切分,英文分詞效果: analysis|is|one|of|the|main|causes|of|slow|indexing.|indexing|simply|put| IKAnalyzer中文分詞器 細粒度切分,中文分詞效果: 厲害|害了|我|的|國一|一經|一|經|播出|受到|各方|好評|強烈|激發|發了|國人|的|愛國|之情|自豪感|自豪|感| IKAnalyzer中文分詞器 智慧切分,英文分詞效果: analysis|is|one|of|the|main|causes|of|slow|indexing.|simply|put| IKAnalyzer中文分詞器 智慧切分,中文分詞效果: 厲|害了|我|的|國|一經|播出|受到|各方|好評|強烈|激|發了|國人|的|愛國|之情|自豪感|
IKAnalyze擴充套件
-
停用詞擴充套件
IK中預設的停用詞很少,需要擴充套件它,從https://github.com/cseryp/stopwords下載一份比較全的停用詞。- 停用詞檔案中一行一個詞,且檔案必須是UTF-8編碼,檔案命名為my_ext_stopword.dic
- 檔案存放於src/main/resource中
-
新詞擴充套件
每年都會產生很多新詞,比如網路用語等,因此需要維護一份新詞詞典- 新詞檔案中多個詞語間用;隔開,且檔案必須是UTF-8編碼,檔案命名為ext.dic
- 檔案存放於src/main/resource中
-
配置檔案
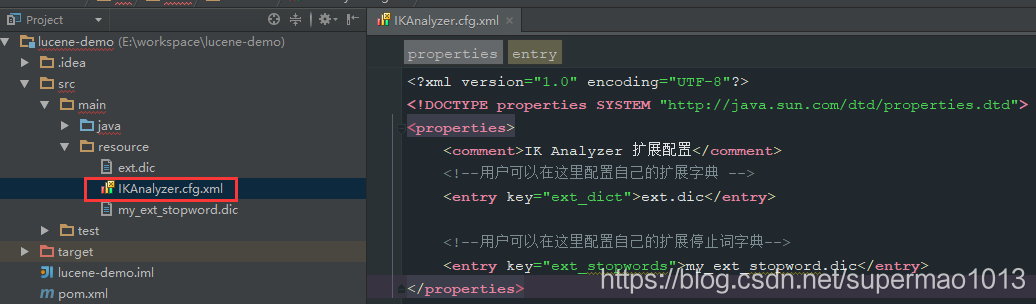
上述兩個檔案中需要加入一個配置檔案中才能生效- 新增一個配置檔案,檔名為IKAnalyzer.cfg.xml
- 檔案存放於src/main/resource中*
檔案內容如下:
<?xml version="1.0" encoding="UTF-8"?> <!DOCTYPE properties SYSTEM "http://java.sun.com/dtd/properties.dtd"> <properties> <comment>IK Analyzer 擴充套件配置</comment> <!--使用者可以在這裡配置自己的擴充套件字典 --> <entry key="ext_dict">ext.dic</entry> <!--使用者可以在這裡配置自己的擴充套件停止詞字典--> <entry key="ext_stopwords">my_ext_stopword.dic</entry> </properties>