大資料開發----Hive(入門篇)
前言
本篇介紹Hive的一些常用知識。要說和網上其他manual的區別,那就是這是筆者寫的一套成體系的文件,不是隨心所欲而作。
本文所用的環境為:
- CentOS 6.5 64位
- Hive 2.1.1
- Java 1.8
Hive Architecture
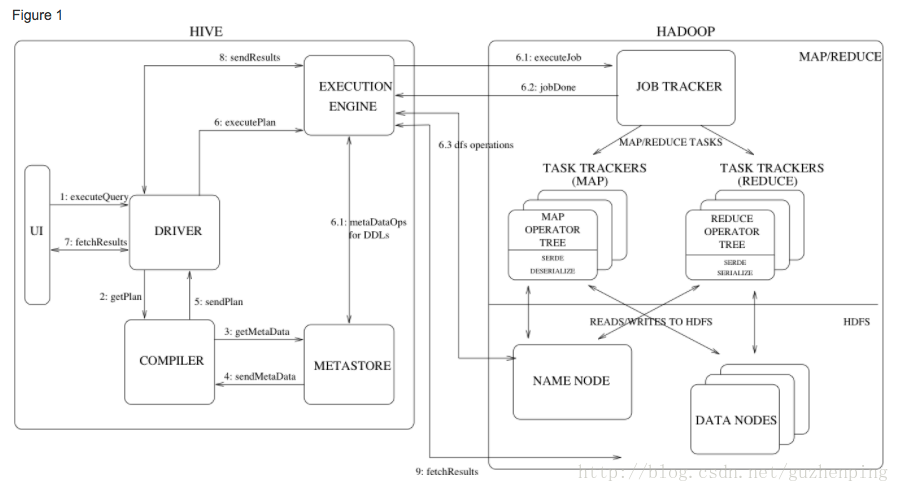
引自官網,務必仔細閱讀:
Figure 1 also shows how a typical query flows through the system. The UI calls the execute interface to the Driver (step 1 in Figure 1). The Driver creates a session handle for the query and sends the query to the compiler to generate an execution plan (step 2). The compiler gets the necessary metadata from the metastore (steps 3 and 4). This metadata is used to typecheck the expressions in the query tree as well as to prune partitions based on query predicates. The plan generated by the compiler (step 5) is a DAG of stages with each stage being either a map/reduce job, a metadata operation or an operation on HDFS. For map/reduce stages, the plan contains map operator trees (operator trees that are executed on the mappers) and a reduce operator tree (for operations that need reducers). The execution engine submits these stages to appropriate components (steps 6, 6.1, 6.2 and 6.3). In each task (mapper/reducer) the deserializer associated with the table or intermediate outputs is used to read the rows from HDFS files and these are passed through the associated operator tree. Once the output is generated, it is written to a temporary HDFS file though the serializer (this happens in the mapper in case the operation does not need a reduce). The temporary files are used to provide data to subsequent map/reduce stages of the plan. For DML operations the final temporary file is moved to the table’s location. This scheme is used to ensure that dirty data is not read (file rename being an atomic operation in HDFS). For queries, the contents of the temporary file are read by the execution engine directly from HDFS as part of the fetch call from the Driver (steps 7, 8 and 9).
Hive QL
- 建立資料庫
-- 建立hello_world資料庫
create database hello_world; - 檢視所有資料庫
show databases;- 檢視所有表
show tables;- 建立內部表
-- 建立hello_world_inner
create table hello_world_inner
(
id bigint,
account string,
name string,
age int
)
row format delimited fields terminated by - 建立分割槽表
create table hello_world_parti
(
id bigint,
name string
)
partitioned by (dt string, country string)
;- 展示表分割槽
show partition hello_world_parti;- 更改表名稱
alter table hello_world_parti to hello_world2_parti;- 匯入資料
load data local inpath '/home/deploy/user_info.txt' 匯入資料的幾種方式
比如有一張測試表:
create table hello
(
id int,
name string,
message string
)
partitioned by (
dt string
)
ROW FORMAT DELIMITED
FIELDS TERMINATED BY '\t'
STORED AS TEXTFILE
;- 從本地檔案系統中匯入資料到hive表
例如:
load data local inpath 'data.txt' into table hello;- 從HDFS上匯入資料到hive表
- 從別的表中查詢出相應的資料並匯入到hive表中
- 建立表時從別的表查到資料並插入的所建立的表中
結語
更多學習交流、技術分析,可加微信群聊–谷同學的IT圈。掃碼進入: