
ELK學習筆記之ElasticSearch簡介
0x00 什麼是Elasticsearch
Elasticsearch (ES)是一個基於 Lucene 的開源搜尋引擎,它不但穩定、可靠、快速,而且也具有良好的水平擴充套件能力,是專門為分散式環境設計的,Elasticsearch是面向文件型資料庫,這意味著它儲存的
整個物件或者文件,它不但會儲存它們,還會為他們建立索引,這樣你就可以搜尋他們了。你可以在 Elasticsearch 中索引、搜尋、排序和過濾這些文件,不需要成行成列的資料,ElasticSearch 提供了一套基
於restful風格的全文檢索服務元件。前身是compass,直到2010被一家公司接管進行維護,開始商業化,並提供了ElasticSearch 一些相關的產品,包括大家比較熟悉的 kibana、logstash 以及 ElasticSearch的
一些元件,比如安全元件shield 。當前最新的ElasticSearch 版本為 5.5.1 ,比較應用廣泛的為2.X,直到 2016-12 推出了5.x 版本 ,將版本號調為 5.X 。這是為了和 kibana 和 logstash 等產品版本號進行統一ElasticSearch 。
0x01 Elasticsearch特性
1.安裝方便:沒有其他依賴,下載後安裝非常方便;只用修改幾個引數就可以搭建起來一個叢集
2.JSON:輸入/輸出格式為 JSON,不需要定義 Schema,快捷方便
3.RESTful:基本所有操作(索引、查詢、甚至是配置)都可以通過 HTTP 介面進行
4.分散式:節點對外表現對等(每個節點都可以用來做入口),加入節點自動均衡
5.多租戶:可根據不同的用途分索引;可以同時操作多個索引
6.準實時:從文件索引到可以被檢索只有輕微延時,約1s
7.支援外掛機制,分詞外掛、同步外掛、Hadoop外掛、視覺化外掛等。
Elasticsearch使用Lucene作為內部引擎,但是在使用它做全文搜尋時,只需要使用統一開發好的API即可,而不需要了解其背後複雜的Lucene的執行原理。當然Elasticsearch並不僅僅是Lucene這麼簡單,它不但包括了全文搜尋功能,還可以進行以下工作:
1.分散式實時檔案儲存,並將每一個欄位都編入索引,使其可以被搜尋。
2.實時分析的分散式搜尋引擎。
3.可以擴充套件到上百臺伺服器,處理PB級別的結構化或非結構化資料。
4.這麼多的功能被整合到一臺伺服器上,你可以輕鬆地通過客戶端或者任何你喜歡的程式語言與ES的RESTful API進行交流。
0x02 ElasticSearch相關概念
下圖是 Elasticsearch 外掛 head 的一個截圖
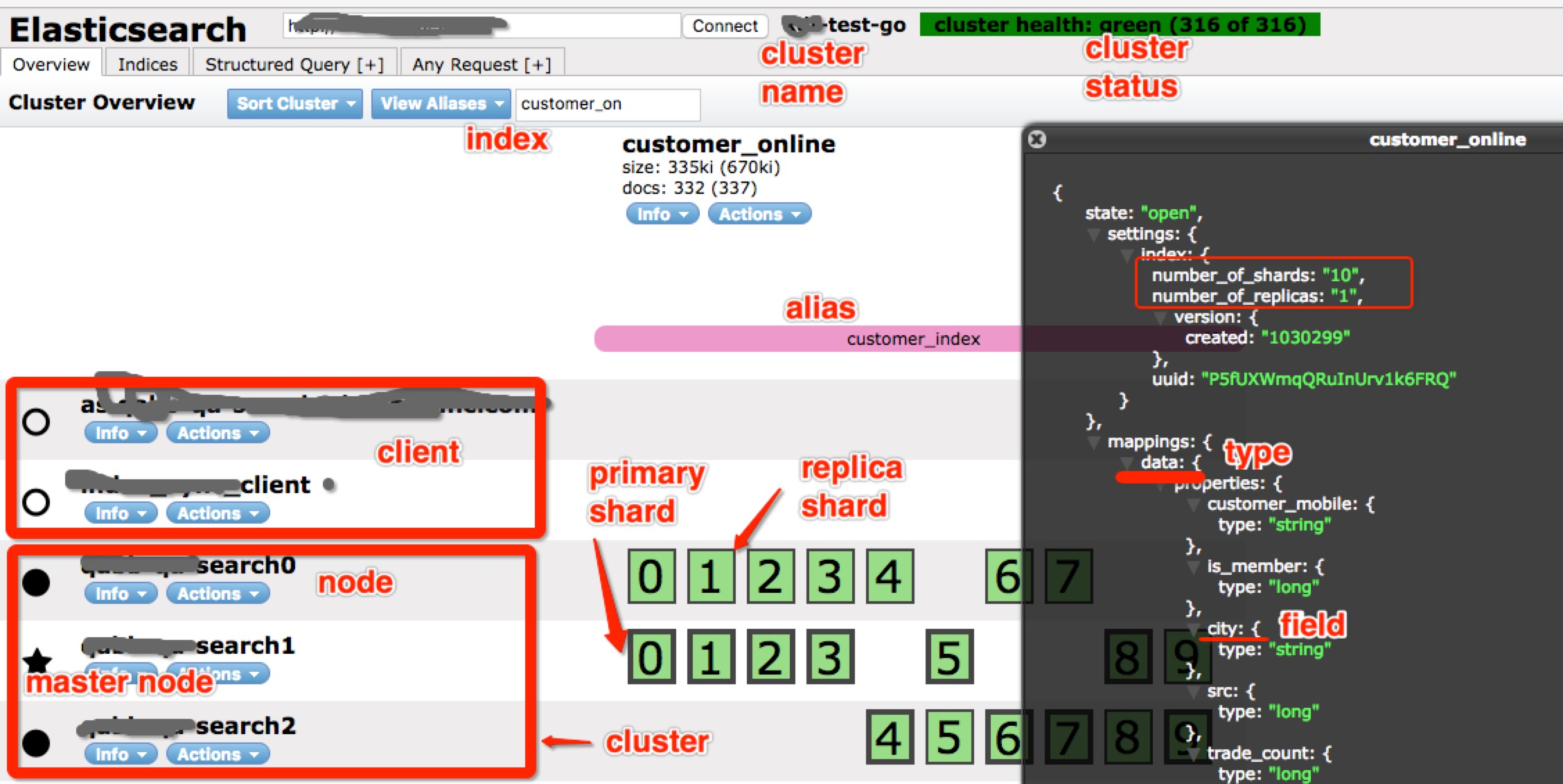
● node:即一個 Elasticsearch 的執行例項,使用多播或單播方式發現 cluster 並加入。
● cluster:包含一個或多個擁有相同叢集名稱的 node,其中包含一個master node。
● index:類比關係型資料庫裡的DB,是一個邏輯名稱空間。
● alias:可以給 index 新增零個或多個alias,通過 alias 使用index 和根據index name 訪問index一樣,但是,alias給我們提供了一種切換index的能力,比如重建了index,取名● customer_online_v2,這時,有了alias,我要訪問新 index,只需要把 alias 新增到新 index 即可,並把alias從舊的 index 刪除。不用修改程式碼。
● type:類比關係資料庫裡的Table。其中,一個index可以定義多個type,但一般使用習慣僅配一個type。
● mapping:類比關係型資料庫中的 schema 概念,mapping 定義了 index 中的 type。mapping 可以顯示的定義,也可以在 document 被索引時自動生成,如果有新的 field,Elasticsearch 會自動推測出 field 的type並加到mapping中。
● document:類比關係資料庫裡的一行記錄(record),document 是 Elasticsearch 裡的一個 JSON 物件,包括零個或多個field。
● field:類比關係資料庫裡的field,每個field 都有自己的欄位型別。
● shard:是一個Lucene 例項。Elasticsearch 基於 Lucene,shard 是一個 Lucene 例項,被 Elasticsearch 自動管理。之前提到,index 是一個邏輯名稱空間,shard 是具體的物理概念,建索引、查詢等都是
體的shard在工作。shard 包括primary shard 和 replica shard,寫資料時,先寫到primary shard,然後,同步到replica shard,查詢時,primary 和 replica 充當相同的作用。replica shard 可以有多份,也可
沒有,replica shard的存在有兩個作用,一是容災,如果primary shard 掛了,資料也不會丟失,叢集仍然能正常工作;二是提高效能,因為replica 和 primary shard 都能處理查詢。另外,如上圖右側紅框
示,shard數和replica數都可以設定,但是,shard 數只能在建立index 時設定,後期不能更改,但是,replica 數可以隨時更改。但是,由於 Elasticsearch 很友好的封裝了這部分,在使用Elasticsearch 的過
中,我們一般僅需要關注 index 即可,不需關注shard。
綜上所述,shard、node、cluster 在物理上構成了 Elasticsearch 叢集,field、type、index 在邏輯上構成一個index的基本概念,在使用 Elasticsearch 過程中,我們一般關注到邏輯概念就好,就像我們在使用
MySQL 時,我們一般就關注DB Name、Table和schema即可,而不會關注DBA維護了幾個MySQL例項、master 和 slave 等怎麼部署的一樣。
要了解ES首先就要弄清楚下面的幾個概念,這樣也不會對ES產生一些誤解:
1. 近實時(NRT)
ES並不是一個標準的資料庫,它不像MongoDB,它側重於對儲存的資料進行搜尋。因此要注意到它 不是 實時讀寫 的,這也就意味著,剛剛儲存的資料,並不能馬上查詢到。
當然這裡還要區分查詢的方式,ES也有資料的查詢以及搜尋,這裡的近實時強調的是搜尋....
2. 叢集(Cluster)
在ES中,對使用者來說叢集是很透明的。你只需要指定一個叢集的名字(預設是elasticsearch),啟動的時候,凡是叢集是這個名字的,都會預設加入到一個叢集中。
你不需要做任何操作,選舉或者管理都是自動完成的。
對使用者來說,僅僅是一個名字而已!
3. 節點(Node)
跟叢集的概念差不多,ES啟動時會設定這個節點的名字,一個節點也就是一個ES得伺服器。
預設會自動生成一個名字,這個名字在後續的叢集管理中還是很有作用的,因此如果想要手動的管理或者檢視一些叢集的資訊,最好是自定義一下節點的名字。
4. 索引(Index)
索引是一類文件的集合,所有的操作比如索引(索引資料)、搜尋、分析都是基於索引完成的。
在一個叢集中,可以定義任意數量的索引。
5. 型別(Type)
型別可以理解成一個索引的邏輯分割槽,用於標識不同的文件欄位資訊的集合。但是由於ES還是以索引為粗粒度的單位,因此一個索引下的所有的型別,都存放在一個索引下。這也就導致不同型別相同欄位名字的欄位會存在型別定義衝突的問題。
在2.0之前的版本,是可以插入但是不能搜尋;在2.0之後的版本直接做了插入檢查,禁止欄位型別衝突。
6. 文件(Document)
文件是儲存資料資訊的基本單元,使用json來表示。
7. 分片與備份(Sherd & Replica)
在ES中,索引會備份成分片,每個分片是獨立的lucene索引,可以完成搜尋分析儲存等工作。
分片的好處:
1. 如果一個索引資料量很大,會造成硬體硬碟和搜尋速度的瓶頸。如果分成多個分片,分片可以分攤壓力。
2. 分片允許使用者進行水平的擴充套件和拆分
3. 分片允許分散式的操作,可以提高搜尋以及其他操作的效率
拷貝一份分片就完成了分片的備份,那麼備份有什麼好處呢?
1. 當一個分片失敗或者下線時,備份的分片可以代替工作,提高了高可用性。
2. 備份的分片也可以執行搜尋操作,分攤了搜尋的壓力。
ES預設在建立索引時會建立5個分片,這個數量可以修改。
不過需要注意:
1. 分片的數量只能在建立索引的時候指定,不能在後期修改
2. 備份的數量可以動態的定義
0x03 Elasticsearch主要解決問題
1. 檢索相關資料;
2. 返回統計結果;
3. 速度要快:
0x04 Elasticsearch工作原理
當ElasticSearch的節點啟動後,它會利用多播(multicast)(或者單播,如果使用者更改了配置)尋找叢集中的其它節點,並與之建立連線。這個過程如下圖所示:

0x05 Elasticsearch對外介面
1. JAVA API介面
2. RESTful API介面
0x06 Elasticsearch JAVA客戶端
1.Transport客戶端
Transport Client表示傳輸客戶端,ElasticSearch內建客戶端的一種,使用傳輸模組遠端連線到Elasticsearch叢集
2.Jest客戶端
Jest是ElasticSearch的Java HTTP Rest客戶端,第三方工具,它為索引和搜尋結果提供了一個POJO編組機制
0x07 基於Lucence的全文檢索
全文檢索就是對一篇文章進行索引,可以根據關鍵字搜尋,類似於mysql裡的like語句。
全文索引就是把內容根據詞的意義進行分詞,然後分別建立索引,例如”你們的激情是因為什麼事情來的” 可能會被分詞成:“你們“,”激情“,“什麼事情“,”來“ 等token,這樣當你搜索“你們” 或者 “激情” 都會
這句搜出來。
0x08 ElasticSearch與傳統關係型資料庫對比
在ElasticSearch中,我們常常會聽到Index、Type以及Document等概念,將Elasticsearch和傳統關係型資料庫MySQL做一下類比:

index => databases type => table field => field document => record mapping => schema
簡單描述:
1) Index
定義:類似於mysql中的database。索引只是一個邏輯上的空間,物理上是分為多個檔案來管理的。
命名:必須全小寫
描述:因為本身ES是基於Lucene的,所以內部索引的本質上其實Lucene的索引構造方式.
ES中index可能被分為多個分片【對應物理上的lcenne索引】,在實踐過程中每個index都會有一個相應的副 本。主要用來在硬體出現問題時,用來回滾資料的。這也某種程式上,加劇了ES對於記憶體高要求。
2)Type
定義:類似於mysql中的table,根據使用者需求每個index中可以新建任意數量的type。
3)Document
定義:對應mysql中的row。有點類似於MongoDB中的文件結構,每個Document是一個json格式的文字。
4)Mapping
更像是一個用來定義每個欄位型別的語義規範在mysql中類似sql語句,在ES中經過包裝後,都被封裝為友好的Restful風格的介面進行操作。這一點也是為什麼開發人員更願意使用ES或者compass這樣的框架
而不是直接使用Lucene的一個原因。
5)Shards & Replicas
定義:能夠為每個索引提供水平的擴充套件以及備份操作。
描述:
Shards:在單個節點中,index的儲存始終是有限制,並且隨著儲存的增大會帶來效能的問題。為了解決這個問題,ElasticSearch提供一個能夠分割單個index到叢集各個節點的功能。你可以在新建這個索引時,
手動的定義每個索引分片的數量。
6)Replicas
在每個node出現宕機或者下線的情況,Replicas能夠在該節點下線的同時將副本同時自動分配到其他仍然可用的節點。而且在提供搜尋的同時,允許進行擴充套件節點的數量,在這個期間並不會出現服務終止的情況。
預設情況下,每個索引會分配5個分片,並且對應5個分片副本,同時會出現一個完整的副本【包括5個分配的副本資料】。
從 Elasticsearch 中取出一條資料(document)看看:

由index、type和id三者唯一確定一個document,_source 欄位中是具體的document 值,是一個JSON 物件,有5個field組成。
注意:mysql的Index和Elasticsearch的Index含義並不一致。
Elasticsearch叢集可以包含多個索引(indices)(資料庫),每一個索引可以包含多個型別(types)(表), 每一個型別包含多個文件(documents)(行),然後每個文件包含多個欄位(Fields)(列)。資料被儲存和索引在分片
(shards)中,索引只是把一個或多個分片分組在一起的邏輯空間。我們只需要知道文件儲存在索引(index)中。其他細節都可以有Elasticsearch搞定。
總結: (1)關係型資料庫中的資料庫(DataBase),等價於ES中的索引(Index) (2)一個數據庫下面有N張表(Table),等價於1個索引Index下面有N多型別(Type)。 (3)一個數據庫表(Table)下的資料由多行(ROW)多列(column,屬性)組成,等價於1個Type由多個文件(Document)和多Field組成。 (4)在一個關係型資料庫裡面,schema定義了表、每個表的欄位,還有表和欄位之間的關係。 與之對應的,在ES中:Mapping定義索引下的Type的欄位處理規則,即索引如何建立、索引型別、是否儲存原 始索引JSON文件、是否壓縮原始JSON文件、是否需要分詞處理、如何進行分詞處理等。 (5)在資料庫中的增insert、刪delete、改update、查search操作等價於ES中的增PUT/POST、刪Delete、改_update、查GET。
0x09 Elasticsearch應用場景
1.它提供了強大的搜尋功能,可以實現類似百度、谷歌等搜尋。
2.可以搜尋日誌或者交易資料,用來分析商業趨勢、蒐集日誌、分析系統瓶頸或者執行發展等等
3.可以提供預警功能(持續的查詢分析某個資料,如果超過一定的值,就進行警告)
4.分析商業資訊,在百萬級的大資料中輕鬆的定位關鍵資訊
5.維基百科使用Elasticsearch來進行全文搜做並高亮顯示關鍵詞,以及提供search-as-you-type、did-you-mean等搜尋建議功能。
6.英國衛報使用Elasticsearch來處理訪客日誌,以便能將公眾對不同文章的反應實時地反饋給各位編輯。
7.StackOverflow將全文搜尋與地理位置和相關資訊進行結合,以提供more-like-this相關問題的展現。
8.GitHub使用Elasticsearch來檢索超過1300億行程式碼。
0x10 Elasticsearch與Lucene的區別
Elasticsearch執行搜尋的速度更快,可以簡單的通過HTTP方式,使用JSON來操作資料,並支援對分散式叢集的搜尋。
Elasticsearch對分散式支援,其索引功能分拆為多個分片,每個分片可有0個或多個副本,叢集中的每個資料節點都可承載一個或多個分片,並且能協調和處理各種操作;負載再平衡(Rebalancing)和路由
(Routing)在大多數情況下都是自動完成的。
Lucene只是一個庫。想要使用它,你必須使用Java來作為開發語言並將其直接整合到你的應用中,更糟糕的是,Lucene非常複雜,你需要深入瞭解檢索的相關知識來理解它是如何工作的。
Elasticsearch也使用Java開發並使用Lucene作為其核心來實現所有索引和搜尋的功能,但是它的目的是通過簡單的RESTful API來隱藏Lucene的複雜性,從而讓全文搜尋變得簡單。
0x11 Elasticsearch與Solr的區別
比較總結:
1. 都是基於Lucene,且安裝都很簡單
2. Solr利用Zookeeper進行分散式管理,而Elasticsearch自身帶有分散式協調管理功能
3. Solr支援更多格式的資料,而Elasticsearch僅支援json格式
4. Solr官方提供功能較多,而Elasticsearch更注重核心功能,高階功能多由第三方外掛提供
5. Solr在傳統的搜尋應用中表現好於Elasticsearch,但Elasticsearch在實時搜尋應用中效率更高
結論:
1. solr查詢快,但更新索引時慢(即插入刪除慢),用於電商等查詢多的應用;
2.ES建立索引快(即查詢慢),即實時性查詢快,用於facebook新浪等搜尋。