
*lucene索引_的刪除和更新
阿新 • • 發佈:2018-11-01
【刪除】

【恢復刪除】

【強制刪除】

【優化和合並】

【更新索引】
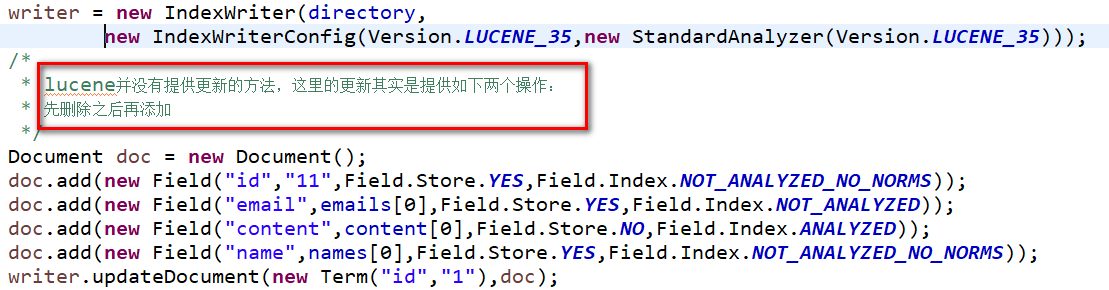
附:
程式碼:
IndexUtil.java:
1 package cn.hk.index; 2 3 import java.io.File; 4 import java.io.IOException; 5 6 import org.apache.lucene.analysis.standard.StandardAnalyzer; 7 import org.apache.lucene.document.Document;8 import org.apache.lucene.document.Field; 9 import org.apache.lucene.index.CorruptIndexException; 10 import org.apache.lucene.index.IndexReader; 11 import org.apache.lucene.index.IndexWriter; 12 import org.apache.lucene.index.IndexWriterConfig; 13 import org.apache.lucene.index.StaleReaderException;14 import org.apache.lucene.index.Term; 15 import org.apache.lucene.store.Directory; 16 import org.apache.lucene.store.FSDirectory; 17 import org.apache.lucene.store.LockObtainFailedException; 18 import org.apache.lucene.util.Version; 19 20 public class IndexUtil { 21 private String[] ids = {"1","2","3","4","5","6"};22 private String[] emails = {"[email protected]","[email protected]","[email protected]", 23 "[email protected]","[email protected]","[email protected]"}; 24 private String[] content = { 25 "welcome to visited the space","hello boy","my name is aa","i like football", 26 "I like football and I like Basketball too","I like movie and swim" 27 }; 28 private int[] attachs = {2,3,1,4,5,5}; 29 private String[] names = {"zhangsan","lisi","john","mike","jetty","jake"}; 30 31 private Directory directory = null; 32 33 public IndexUtil(){ 34 try { 35 directory = FSDirectory.open(new File("d://lucene/index02")); 36 } catch (IOException e) { 37 e.printStackTrace(); 38 } 39 } 40 41 public void update(){ 42 IndexWriter writer =null; 43 try { 44 writer = new IndexWriter(directory, 45 new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35))); 46 /* 47 * lucene並沒有提供更新的方法,這裡的更新其實是提供如下兩個操作: 48 * 先刪除之後再新增 49 */ 50 Document doc = new Document(); 51 doc.add(new Field("id","11",Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 52 doc.add(new Field("email",emails[0],Field.Store.YES,Field.Index.NOT_ANALYZED)); 53 doc.add(new Field("content",content[0],Field.Store.NO,Field.Index.ANALYZED)); 54 doc.add(new Field("name",names[0],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 55 writer.updateDocument(new Term("id","1"),doc); 56 } catch (CorruptIndexException e) { 57 e.printStackTrace(); 58 } catch (LockObtainFailedException e) { 59 e.printStackTrace(); 60 } catch (IOException e) { 61 e.printStackTrace(); 62 }finally{ 63 if(writer != null) 64 try { 65 writer.close(); 66 } catch (CorruptIndexException e) { 67 e.printStackTrace(); 68 } catch (IOException e) { 69 e.printStackTrace(); 70 } 71 } 72 73 } 74 75 76 public void merge(){ 77 IndexWriter writer = null; 78 try { 79 writer = new IndexWriter(directory, 80 new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); 81 //會將索引合併為2段,這兩段中的被刪除的資料會被清空 82 //特別注意:此處在lucene3.5後不建議使用,因為會消耗大量的開銷, 83 //lucene會根據情況自動處理的 84 writer.forceMerge(2); 85 } catch (CorruptIndexException e) { 86 e.printStackTrace(); 87 } catch (LockObtainFailedException e) { 88 e.printStackTrace(); 89 } catch (IOException e) { 90 e.printStackTrace(); 91 }finally{ 92 if(writer != null) 93 try { 94 writer.close(); 95 } catch (CorruptIndexException e) { 96 e.printStackTrace(); 97 } catch (IOException e) { 98 e.printStackTrace(); 99 } 100 } 101 } 102 103 public void forceDelete(){ 104 IndexWriter writer = null; 105 try { 106 writer = new IndexWriter(directory, 107 new IndexWriterConfig(Version.LUCENE_35,new StandardAnalyzer(Version.LUCENE_35))); 108 writer.forceMergeDeletes(); 109 } catch (CorruptIndexException e) { 110 e.printStackTrace(); 111 } catch (LockObtainFailedException e) { 112 e.printStackTrace(); 113 } catch (IOException e) { 114 e.printStackTrace(); 115 }finally{ 116 if(writer != null) 117 try { 118 writer.close(); 119 } catch (CorruptIndexException e) { 120 e.printStackTrace(); 121 } catch (IOException e) { 122 e.printStackTrace(); 123 } 124 } 125 } 126 127 128 public void undelete(){ 129 //使用IndexReader進行恢復 130 try { 131 IndexReader reader = IndexReader.open(directory,false); 132 //回覆時,必須把IndexReader的只讀(readyonly)設定為FALSE 133 reader.undeleteAll(); 134 reader.close(); 135 } catch (StaleReaderException e) { 136 137 e.printStackTrace(); 138 } catch (CorruptIndexException e) { 139 140 e.printStackTrace(); 141 } catch (LockObtainFailedException e) { 142 143 e.printStackTrace(); 144 } catch (IOException e) { 145 // TODO Auto-generated catch block 146 e.printStackTrace(); 147 } 148 } 149 150 151 152 153 154 public void delete(){ 155 IndexWriter writer = null; 156 try { 157 writer = new IndexWriter(directory, 158 new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); 159 //刪除ID為1的文件 160 //引數可以是一個選項,可以是一個Query,也可以是一個Term,Term是一個精確查詢的值 161 //此時刪除的文件並不會被完全刪除,而是儲存在回收站中的,可以恢復 162 writer.deleteDocuments(new Term("id","1")); 163 } catch (CorruptIndexException e) { 164 165 e.printStackTrace(); 166 } catch (LockObtainFailedException e) { 167 168 e.printStackTrace(); 169 } catch (IOException e) { 170 171 e.printStackTrace(); 172 }finally{ 173 if(writer != null) 174 try { 175 writer.close(); 176 } catch (CorruptIndexException e) { 177 178 e.printStackTrace(); 179 } catch (IOException e) { 180 181 e.printStackTrace(); 182 } 183 } 184 } 185 186 187 188 public void query(){ 189 try { 190 IndexReader reader = IndexReader.open(directory); 191 //通過reader可以獲取文件的數量 192 System.out.println("numDocs:" + reader.numDocs()); 193 System.out.println("maxDocs" + reader.maxDoc()); 194 System.out.println("deleteDocs:" + reader.numDeletedDocs()); 195 reader.close(); 196 } catch (CorruptIndexException e) { 197 198 e.printStackTrace(); 199 } catch (IOException e) { 200 201 e.printStackTrace(); 202 } 203 } 204 205 206 public void index(){ 207 IndexWriter writer = null; 208 try { 209 writer = new IndexWriter(directory,new IndexWriterConfig(Version.LUCENE_35, new StandardAnalyzer(Version.LUCENE_35))); 210 Document doc = null; 211 for(int i=0;i<ids.length;i++){ 212 doc = new Document(); 213 doc.add(new Field("id",ids[i],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 214 doc.add(new Field("email",emails[i],Field.Store.YES,Field.Index.NOT_ANALYZED)); 215 doc.add(new Field("content",content[i],Field.Store.NO,Field.Index.ANALYZED)); 216 doc.add(new Field("name",names[i],Field.Store.YES,Field.Index.NOT_ANALYZED_NO_NORMS)); 217 writer.addDocument(doc); 218 } 219 } catch (CorruptIndexException e) { 220 e.printStackTrace(); 221 } catch (LockObtainFailedException e) { 222 e.printStackTrace(); 223 } catch (IOException e) { 224 e.printStackTrace(); 225 }finally{ 226 if(writer != null) 227 try { 228 writer.close(); 229 } catch (CorruptIndexException e) { 230 231 e.printStackTrace(); 232 } catch (IOException e) { 233 234 e.printStackTrace(); 235 } 236 237 } 238 } 239 240 }
TestIndex.java:
1 package cn.hk.test; 2 3 import org.junit.Test; 4 5 import cn.hk.index.IndexUtil; 6 7 public class TestIndex { 8 9 @Test 10 public void testIndex(){ 11 IndexUtil iu = new IndexUtil(); 12 iu.index(); 13 } 14 15 @Test 16 public void testQuery(){ 17 IndexUtil iu = new IndexUtil(); 18 iu.query(); 19 } 20 21 @Test 22 public void testDelete(){ 23 IndexUtil iu = new IndexUtil(); 24 iu.delete(); 25 } 26 27 @Test 28 public void testUnDelete(){ 29 IndexUtil iu = new IndexUtil(); 30 iu.undelete(); 31 } 32 33 @Test 34 public void testForceDelete(){ 35 IndexUtil iu = new IndexUtil(); 36 iu.forceDelete(); 37 } 38 39 public void testMerge(){ 40 IndexUtil iu = new IndexUtil(); 41 iu.merge(); 42 } 43 44 @Test 45 public void testUpdate(){ 46 IndexUtil iu = new IndexUtil(); 47 iu.update(); 48 } 49 }

