
優化ElasticSearch之合理分配索引分片詳解

大多數ElasticSearch使用者在建立索引時通用會問的一個重要問題是:我需要建立多少個分片?
在本文中, 我將介紹在分片分配時的一些權衡以及不同設定帶來的效能影響. 如果想搞清晰你的分片策略以及如何優化,請繼續往下閱讀.
為什麼要考慮分片數
分片分配是個很重要的概念, 很多使用者對如何分片都有所疑惑, 當然是為了讓分配更合理. 在生產環境中, 隨著資料集的增長, 不合理的分配策略可能會給系統的擴充套件帶來嚴重的問題.
同時, 這方面的文件介紹也非常少. 很多使用者只想要明確的答案而不僅僅一個數字範圍, 甚至都不關心隨意的設定可能帶來的問題.
當然,我也有一些答案. 不過先要看看它的定義和描述, 然後通過幾個通用的案例來分別給出我們的建議.
分片定義
如果你剛接觸ElasticSearch, 那麼弄清楚它的幾個術語和核心概念是非常必要的.
(如果你已經有ES的相關經驗, 可以跳過這部分)
假設ElasticSearch叢集的部署結構如下:
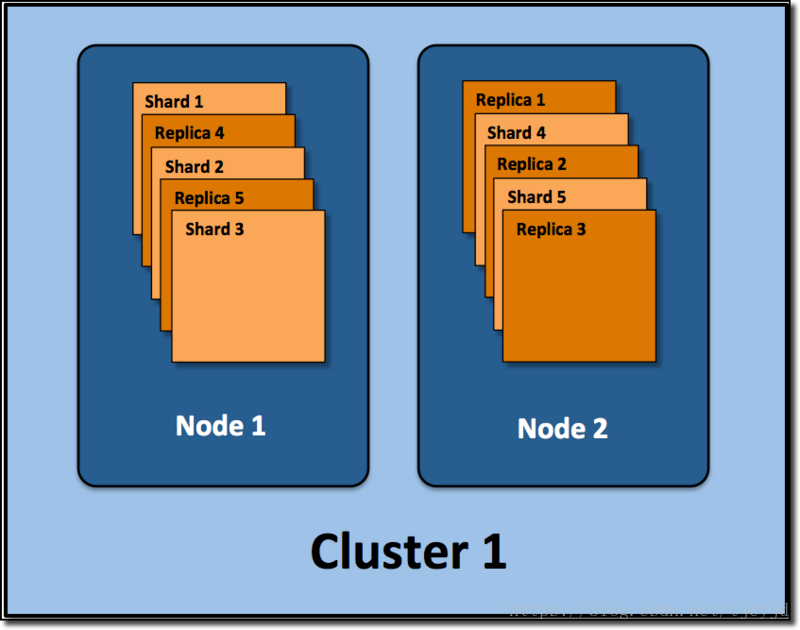
通過該圖, 記住下面的幾個定義:
叢集(cluster): 由一個或多個節點組成, 並通過叢集名稱與其他叢集進行區分
節點(node): 單個ElasticSearch例項. 通常一個節點執行在一個隔離的容器或虛擬機器中
索引(index): 在ES中, 索引是一組文件的集合
分片(shard): 因為ES是個分散式的搜尋引擎, 所以索引通常都會分解成不同部分, 而這些分佈在不同節點的資料就是分片. ES自動管理和組織分片, 並在必要的時候對分片資料進行再平衡分配, 所以使用者基本上不用擔心分片的處理細節.
副本(replica): ES預設為一個索引建立5個主分片, 並分別為其建立一個副本分片. 也就是說每個索引都由5個主分片成本, 而每個主分片都相應的有一個copy.
對於分散式搜尋引擎來說, 分片及副本的分配將是高可用及快速搜尋響應的設計核心.主分片與副本都能處理查詢請求, 它們的唯一區別在於只有主分片才能處理索引請求.
在上圖示例中, 我們的ElasticSearch叢集有兩個節點, 並使用了預設的分片配置. ES自動把這5個主分片分配到2個節點上, 而它們分別對應的副本則在完全不同的節點上. 對,就這是分散式的概念.
請記住, 索引的number_of_shards引數只對當前索引有效而不是對整個叢集生效.對每個索引來講, 該引數定義了當前索引的主分片數(而不是叢集中所有的主分片數).
關於副本
本文中不會對ElasticSearch的副本做詳細闡述. 如果想單獨瞭解可參考這篇文章.
副本對搜尋效能非常重要, 同時使用者也可在任何時候新增或刪除副本. 正如另篇文章所述, 額外的副本能給你帶來更大的容量, 更高的呑吐能力及更強的故障恢復能力.
謹慎分配你的分片
當在ElasticSearch叢集中配置好你的索引後, 你要明白在叢集執行中你無法調整分片設定. 既便以後你發現需要調整分片數量, 你也只能新建建立並對資料進行重新索引(reindex)(雖然reindex會比較耗時, 但至少能保證你不會停機).
主分片的配置與硬碟分割槽很類似, 在對一塊空的硬碟空間進行分割槽時, 會要求使用者先進行資料備份, 然後配置新的分割槽, 最後把資料寫到新的分割槽上.
2~3GB的靜態資料集
分配分片時主要考慮的你的資料集的增長趨勢.
我們也經常會看到一些不必要的過度分片場景. 從ES社群使用者對這個熱門主題(分片配置)的分享資料來看, 使用者可能認為過度分配是個絕對安全的策略(這裡講的過度分配是指對特定資料集, 為每個索引分配了超出當前資料量(文件數)所需要的分片數).
Elastic在早期確實鼓吹過這種做法, 然後很多使用者做的更為極端--例如分配1000個分片. 事實上, Elastic目前對此持有更謹慎的態度.
稍有富餘是好的, 但過度分配分片卻是大錯特錯. 具體定義多少分片很難有定論, 取決於使用者的資料量和使用方式. 100個分片, 即便很少使用也可能是好的;而2個分片, 即便使用非常頻繁, 也可能是多餘的.
要知道, 你分配的每個分片都是有額外的成本的:
-
每個分片本質上就是一個Lucene索引, 因此會消耗相應的檔案控制代碼, 記憶體和CPU資源
-
每個搜尋請求會排程到索引的每個分片中. 如果分片分散在不同的節點倒是問題不太. 但當分片開始競爭相同的硬體資源時, 效能便會逐步下降
-
ES使用詞頻統計來計算相關性. 當然這些統計也會分配到各個分片上. 如果在大量分片上只維護了很少的資料, 則將導致最終的文件相關性較差
我們的客戶通常認為隨著業務的增長, 他們的資料量也會相應的增加, 所以很有必要為此做長期規劃. 很多使用者相信他們將會遇到暴發性增長(儘管大多數甚至都沒有遇到過峰值), 當然也希望避免重新分片並減少可能的停機時間.
如果你真的擔心資料的快速增長, 我們建議你多關心這條限制: ElasticSearch推薦的最大JVM堆空間是30~32G, 所以把你的分片最大容量限制為30GB, 然後再對分片數量做合理估算. 例如, 你認為你的資料能達到200GB, 我們推薦你最多分配7到8個分片.
總之, 不要現在就為你可能在三年後才能達到的10TB資料做過多分配. 如果真到那一天, 你也會很早感知到效能變化的.
儘管本部分並未詳細討論副本分片, 但我們推薦你保持適度的副本數並隨時可做相應的增加. 如果你正在部署一個新的環境, 也許你可以參考我們的基於副本的叢集的設計.這個叢集有三個節點組成, 每個分片只分配了副本. 不過隨著需求變化, 你可以輕易的調整副本數量.
大規模以及日益增長的資料場景
對大資料集, 我們非常鼓勵你為索引多分配些分片--當然也要在合理範圍內. 上面講到的每個分片最好不超過30GB的原則依然使用.
不過, 你最好還是能描述出每個節點上只放一個索引分片的必要性. 在開始階段, 一個好的方案是根據你的節點數量按照1.5~3倍的原則來建立分片. 例如,如果你有3個節點, 則推薦你建立的分片數最多不超過9(3x3)個.
隨著資料量的增加,如果你通過叢集狀態API發現了問題,或者遭遇了效能退化,則只需要增加額外的節點即可. ES會自動幫你完成分片在不同節點上的分佈平衡.
再強調一次, 雖然這裡我們暫未涉及副本節點的介紹, 但上面的指導原則依然使用: 是否有必要在每個節點上只分配一個索引的分片. 另外, 如果給每個分片分配1個副本, 你所需的節點數將加倍. 如果需要為每個分片分配2個副本, 則需要3倍的節點數. 更多詳情可以參考基於副本的叢集.
Logstash
不知道你是否有基於日期的索引需求, 並且對索引資料的搜尋場景非常少. 也許這些索引量將達到成百上千, 但每個索引的資料量只有1GB甚至更小. 對於這種類似場景, 我建議你只需要為索引分配1個分片.
如果使用ES的預設配置(5個分片), 並且使用Logstash按天生成索引, 那麼6個月下來, 你擁有的分片數將達到890個. 再多的話, 你的叢集將難以工作--除非你提供了更多(例如15個或更多)的節點.
想一下, 大部分的Logstash使用者並不會頻繁的進行搜尋, 甚至每分鐘都不會有一次查詢. 所以這種場景, 推薦更為經濟使用的設定. 在這種場景下, 搜尋效能並不是第一要素, 所以並不需要很多副本. 維護單個副本用於資料冗餘已經足夠. 不過資料被不斷載入到記憶體的比例相應也會變高.
如果你的索引只需要一個分片, 那麼使用Logstash的配置可以在3節點的叢集中維持執行6個月. 當然你至少需要使用4GB的記憶體, 不過建議使用8GB, 因為在多資料雲平臺中使用8GB記憶體會有明顯的網速以及更少的資源共享.
總結
再次宣告, 資料分片也是要有相應資源消耗,並且需要持續投入.
當索引擁有較多分片時, 為了組裝查詢結果, ES必須單獨查詢每個分片(當然並行的方式)並對結果進行合併. 所以高效能IO裝置(SSDs)和多核處理器無疑對分片效能會有巨大幫助. 儘管如此, 你還是要多關心資料本身的大小,更新頻率以及未來的狀態. 在分片分配上並沒有絕對的答案, 只希望你能從本文的討論中受益.