
機器學習之貝葉斯網路(三)
引言
貝葉斯網路是機器學習中非常經典的演算法之一,它能夠根據已知的條件來估算出不確定的知識,應用範圍非常的廣泛。貝葉斯網路以貝葉斯公式為理論接觸構建成了一個有向無環圖,我們可以通過貝葉斯網路構建的圖清晰的根據已有資訊預測未來資訊。貝葉斯網路適用於表達和分析不確定性和概率性的事件,應用於有條件地依賴多種控制因素的決策,可以從不完全、不精確或不確定的知識或資訊中做出推理。本文從樸素貝葉斯模型開始,詳細描述了貝葉斯網路的意義,構建方案以及其他衍生演算法。
預備知識
最大熵模型、概率統計
一、樸素貝葉斯
1、樸素貝葉斯假設(與貝葉斯網路區別)
一個特徵出現的概率,與其他特徵(條件)獨立(特徵獨立性),其實是:對於給定分類的條件下,特徵獨立
每個特徵同等重要(特徵均衡性)
例子:文字分類問題:
樣本:10000封郵件,每個郵件被標記為垃圾郵件或者非垃圾郵件
分類目標:給定第10001封郵件,確定它是垃圾郵件還是非垃圾郵件
方法:樸素貝葉斯
類別c:垃圾郵件c1,非垃圾郵件c2
詞彙表,兩種建立方法:
1、使用現成的單詞詞典;2、將所有郵件中出現的單詞都統計出來,得到詞典。
記單詞數目為N
將每個郵件m對映成維度為N的向量xn
若單詞wi在郵件m中出現過,則xi=1,否則,xi=0。即郵件的向量化:m-->(x1,x2……xN)o
貝葉斯公式:P(c|x)=P(x|c)*P(c)/P(x)
P(c1|x)=P(x|c1)*P(c1)/P(x)
P(c2|x)=P(x|c2)*P(c2)/P(x)
注意這裡x是向量
P(c|x)=P(x|c)*P(c)/P(x)
P(x|c)=P(x1,x2…xN|c)=P(x1|c)*P(x2|c)…P(xN|c)
特徵條件獨立假設
P(x)=P(x1,x2…xN)=P(x1)*P(x2)…P(xN)
特徵獨立假設
帶入公式:P(c|x)=P(x|c)*P(c)/P(x)
o等式右側各項的含義:
nP(xi|cj):在cj(此題目,cj要麼為垃圾郵件1,要麼為非垃圾郵件2)的前提下,第i個單詞xi出現的概率
nP(xi):在所有樣本中,單詞xi出現的概率
nP(cj):在所有樣本中,郵件類別cj出現的概率
拉普拉斯平滑(防止是0的情況)
p(x1|c1)是指的:在垃圾郵件c1這個類別中,單詞x1出現的概率。(x1是待考察的郵件中的某個單詞)
定義符號:
n1:在所有垃圾郵件中單詞x1出現的次數。如果x1沒有出現過,則n1=0。
nn:屬於c1類的所有文件的出現過的單詞總數目。
o得到公式:
o拉普拉斯平滑:
n其中,N是所有單詞的數目。修正分母是為了保證概率和為1
同理,以同樣的平滑方案處理p(x1)
二、貝葉斯網路
把某個研究系統中涉及的隨機變數,根據是否條件獨立繪製在一個有向圖中,就形成了貝葉斯網路。
貝葉斯網路,又稱有向無環圖模型(DAG),是一種概率圖模型,根據概率圖的拓撲結構,考察一組隨機變數{X1,X2...Xn}及其n組條件概率分佈(CPD)的性質。
一般而言,貝葉斯網路的有向無環圖中的節點表示隨機變數,它們可以是可觀察到的變數,或隱變數、未知引數等。連線兩個節點的箭頭代表此兩個隨機變數是具有因果關係(或非條件獨立)。若兩個節點間以一個單箭頭連線在一起,表示其中一個節點是“因(parents)”,另一個是“果(children)”,兩節點就會產生一個條件概率值。
每個結點在給定其直接前驅時,條件獨立於其非後繼。
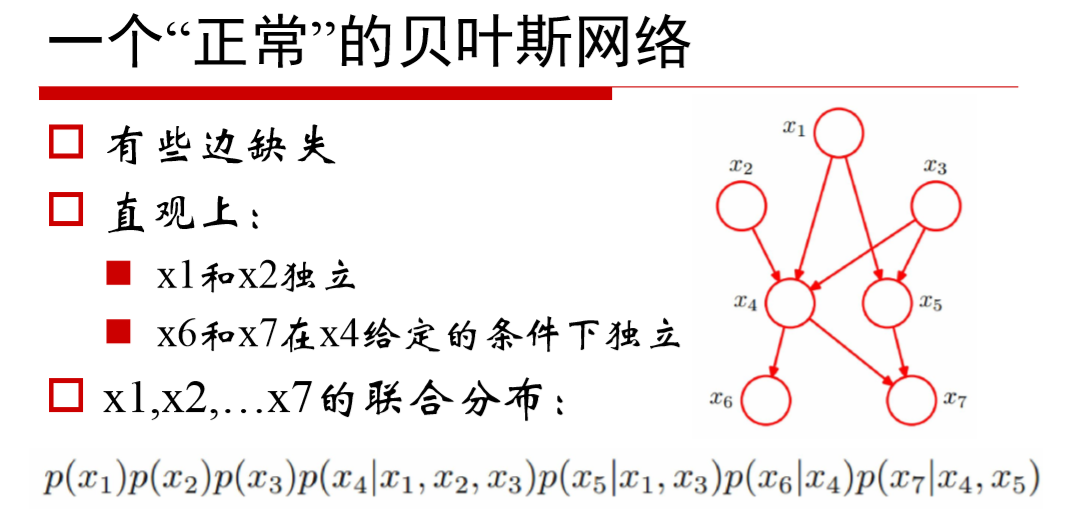
三、馬爾科夫模型
貝葉斯網路簡化形成一條鏈式模型,Ai+1只與Ai有關,與A1,…,Ai-1無關。
![]()
隱馬爾科夫模型:

四、通過貝葉斯網路判斷條件獨立:

五、貝葉斯網路的構建
依次計算每個變數的D-separation的區域性測試結果,綜合每個結點得到貝葉斯網路。
演算法過程:
選擇變數的一個合理順序:X1,X2,...Xn
對於i=1到n
o在網路中新增Xi結點
在X1,X2,...Xi-1中選擇Xi的父母,使得:
![]()
o這種構造方法,顯然保證了全域性的語義要求:
![]()
問題,如果碰到了混合(離散+連續)的網路怎麼辦-->訊號函式離散化