
InfluxDB學習筆記
參考文件如下:
InfluxDB是一個用於儲存和分析時間序列資料的開源資料庫。
主要特性有:
- 內建HTTP介面,使用方便
- 資料可以打標記,查讓查詢可以很靈活
- 類SQL的查詢語句
- 安裝管理很簡單,並且讀寫資料很高效
- 能夠實時查詢,資料在寫入時被索引後就能夠被立即查出
- ……
本文按照如下順序介紹influxdb:
- 1、概念介紹
- 2、快速入門
- 3、Influx HttpAPI
- 4、InfluxQL查詢語言
1、概念介紹
| field value | field key | field set |
|---|---|---|
| tag value | tag key | tag set |
| timestamp | measurement | retention policy |
| series | point | database |
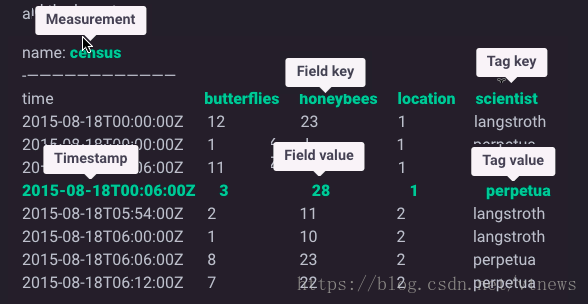
timestamp
RFC3339格式展示了與特定資料相關聯的UTC日期和時間。 field set:每組field key和field value的集合,如butterflies = 3, honeybees = 28
field key/value:在InfluxDB中不能沒有field,field沒有索引。
tag set:不同的每組tag key和tag value的集合,如location = 1, scientist = langstroth
tag key/value:在InfluxDB中可以沒有tag,tag是索引起來的。
measurement: 是一個容器,包含了列time,field和tag。概念上類似表。
retention policy
autogen的保留策略,autogen中的資料永不刪除且備份數replication為1(只有一份資料,在叢集中起作用)。 series:series是共同retention policy,measurement和tag set的集合。如下:
| 任意series編號 | retention policy | measurement | tag set |
|---|---|---|---|
| series 1 | autogen | census | location = 1,scientist = langstroth |
| series 2 | autogen | census | location = 2,scientist = langstroth |
| series 3 | autogen | census | location = 1,scientist = perpetua |
| series 4 | autogen | census | location = 2,scientist = perpetua |
point:point是具有相同timestamp、相同series(measurement,rp,tag set相同)的field。這個點在此時刻是唯一存在的。 相反,當你使用與該series中現有點相同的timestamp記將新point寫入同一series時,該field set將成為舊field set和新field set的並集。
1.1、專業術語
省略了一些簡單的術語。按字母排序,可以跳過。
### batch
用換行符分割的資料點的集合,這批資料可以使用HTTP請求寫到資料庫中。用這種HTTP介面的方式可以大幅降低HTTP的負載。儘管不同的場景下更小或更大的batch可能有更好地效能,InfluxData建議每個batch的大小在5000~10000個數據點。
### continuous query(CQ)
這個一個在資料庫中自動週期執行的InfluxQL的查詢。Continuous query在select語句裡需要一個函式,並且一定會包含一個GROUP BY time()的語法。
### duration
retention policy中的一個屬性,決定InfluxDB中資料保留多長時間。在duration之前的資料會自動從database中刪除掉。
### function
包括InfluxQL中的聚合,查詢和轉換,可以在InfluxQL函式中檢視InfluxQL中的完整函式列表。
### identifier
涉及continuous query的名字,database名字,field keys,measurement名字,retention policy名字,subscription 名字,tag keys以及user 名字的一個標記。
### line protocol
寫入InfluxDB時的資料點的文字格式。如:cpu,host=serverA,region=us_west value=0.64
### metastore
包含了系統狀態的內部資訊。metastore包含了使用者資訊,database,retention policy,shard metadata,continuous query以及subscription。
### node
一個獨立的influxd程序。
### now()
本地伺服器的當前納秒級時間戳。
### query
從InfluxDB裡面獲取資料的一個操作
### replication factor
retention policy的一個引數,決定在叢集模式下資料的副本的個數。InfluxDB在N個數據節點上覆制資料,其中N就是replication factor。
replication factor在單節點的例項上不起作用
### retention policy(RP)
InfluxDB資料結構的一部分,描述了InfluxDB儲存資料的長短(duration),資料存在叢集裡面的副本數(replication factor),以及shard group的時間範圍(shard group duration)。RPs在每個database裡面是唯一的,連同measurement和tag set定義一個series。
當你建立一個database的時候,InfluxDB會自動建立一個叫做autogen的retention policy,其duration為永遠,replication factor為1,shard group的duration設為的七天。
### schema
資料在InfluxDB裡面怎麼組織。InfluxDB的schema的基礎是database,retention policy,series,measurement,tag key,tag value以及field keys。
### series cardinality
在InfluxDB例項上唯一database,measurement和tag set組合的數量。
例如,假設一個InfluxDB例項有一個單獨的database,一個measurement。這個measurement有兩個tag key:email和status。如果有三個不同的email,並且每個email的地址關聯兩個不同的status,那麼這個measurement的series cardinality就是6(3*2=6):
| status | |
|---|---|
| [email protected] | start |
| [email protected] | finish |
| [email protected] | start |
| [email protected] | finish |
| [email protected] | start |
| [email protected] | finish |
注意到,因為所依賴的tag的存在,在某些情況下,簡單地執行該乘法可能會高估series cardinality。 依賴的tag是由另一個tag限定的tag並不增加series cardinality。 如果我們將tagfirstname新增到上面的示例中,則系列基數不會是18(3 * 2 * 3 = 18)。 它將保持不變為6,因為firstname已經由email覆蓋了:
| status | firstname | |
|---|---|---|
| [email protected] | start | lorraine |
| [email protected] | finish | lorraine |
| [email protected] | start | marvin |
| [email protected] | finish | marvin |
| [email protected] | start | clifford |
| [email protected] | finish | clifford |
### server
一個執行InfluxDB的伺服器,可以使虛擬機器也可以是物理機。每個server上應該只有一個InfluxDB的程序。
### shard
shard包含實際的編碼和壓縮資料,並由磁碟上的TSM檔案表示。 每個shard都屬於唯一的一個shard group。多個shard可能存在於單個shard group中。每個shard包含一組特定的series。給定shard group中的給定series上的所有點將儲存在磁碟上的相同shard(TSM檔案)中。
### shard duration
shard duration決定了每個shard group跨越多少時間。具體間隔由retention policy中的SHARD DURATION決定。
例如,如果retention policy的SHARD DURATION設定為1w,則每個shard group將跨越一週,幷包含時間戳在該周內的所有點。
### shard group
shard group是shard的邏輯組合。shard group由時間和retention policy組織。包含資料的每個retention policy至少包含一個關聯的shard group。給定的shard group包含shard group覆蓋的間隔的資料的所有shard。每個shard group跨越的間隔是shard的持續時間。
### subscription
subscription允許Kapacitor在push model中接收來自InfluxDB的資料,而不是基於查詢資料的pull model。當Kapacitor配置為使用InfluxDB時,subscription將自動將訂閱的資料庫的每個寫入從InfluxDB推送到Kapacitor。subscription可以使用TCP或UDP傳輸寫入。
### tsm(Time Structured Merge tree)
InfluxDB的專用資料儲存格式。 TSM可以比現有的B+或LSM樹實現更大的壓縮和更高的寫入和讀取吞吐量。
### user
在InfluxDB裡有兩種型別的使用者:
- admin使用者對所有資料庫都有讀寫許可權,並且有管理查詢和管理使用者的全部許可權。
- 非admin使用者有針對database的可讀,可寫或者二者兼有的許可權。
當認證開啟之後,InfluxDB只執行使用有效的使用者名稱和密碼傳送的HTTP請求。
### values per second
對資料持續到InfluxDB的速率的度量,寫入速度通常以values per second表示。
要計算每秒速率的值,將每秒寫入的點數乘以每點儲存的值數。 例如,如果這些點各有四個field,並且每秒寫入batch是5000個點,那麼values per second是每點4個field x 每batch 5000個點 x 10個batch/秒=每秒200,000個值。
### wal(Write Ahead Log)
最近寫的點數的臨時快取。為了減少訪問永久儲存檔案的頻率,InfluxDB將最新的資料點緩衝進WAL中,直到其總大小或時間觸發然後flush到長久的儲存空間。這樣可以有效地將寫入batch處理到TSM中。
可以查詢WAL中的點,並且系統重啟後仍然保留。在程序開始時,在系統接受新的寫入之前,WAL中的所有點都必須flushed。
1.2、與關係型資料庫比較
### 一般來說
InfluxDB用於儲存大量的時間序列資料,並對這些資料進行快速的實時分析。SQL資料庫也可以提供時序的功能,但時序並不是其目的。
在InfluxDB中,timestamp標識了在任何給定資料series中的單個點。就像關係型資料庫中的主鍵。
InfluxDB考慮到schema可能隨時間而改變,因此賦予了其便利的動態能力。比如只需要在新的資料line中加入所需的值,cpu,host=serverA,region=us_west,newTag=aa value=0.64,newValue=bbb
### 更形象一點
下表是一個叫foodships的SQL資料庫的例子,並有沒有索引的#_foodships列和有索引的park_id,planet和time列。
| park_id | planet | time | _foodships |
|---|---|---|---|
| 1 | Earth | 1429185600000000000 | 0 |
| 1 | Earth | 1429185601000000000 | 3 |
| 1 | Earth | 1429185602000000000 | 15 |
| 1 | Earth | 1429185603000000000 | 15 |
| 2 | Saturn | 1429185600000000000 | 5 |
| 2 | Saturn | 1429185601000000000 | 9 |
| 2 | Saturn | 1429185602000000000 | 10 |
| 2 | Saturn | 1429185603000000000 | 14 |
這些資料在InfluxDB看起來就像這樣:
name: foodships
tags: park_id=1, planet=Earth
time #_foodships
---- ------------
2015-04-16T12:00:00Z 0
2015-04-16T12:00:01Z 3
2015-04-16T12:00:02Z 15
2015-04-16T12:00:03Z 15
name: foodships
tags: park_id=2, planet=Saturn
time #_foodships
---- ------------
2015-04-16T12:00:00Z 5
2015-04-16T12:00:01Z 9
2015-04-16T12:00:02Z 10
2015-04-16T12:00:03Z 14
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
參考上面的資料,一般可以這麼說:
- InfluxDB的measurement(
foodships)和SQL資料庫裡的table類似; - InfluxDB的tag(
park_id和planet)類似於SQL資料庫裡索引的列; - InfluxDB中的field(
#_foodships)類似於SQL資料庫裡沒有索引的列; - InfluxDB裡面的資料點(例如
2015-04-16T12:00:00Z 5)類似於SQL資料庫的行;
基於這些資料庫術語的比較,InfluxDB的continuous query和retention policy與SQL資料庫中的儲存過程類似。 它們被指定一次,然後定期自動執行。
在InfluxDB中InfluxQL是一種類SQL的語言。對於來自其他SQL或類SQL環境的使用者來說,它已經被精心設計,而且還提供特定於儲存和分析時間序列資料的功能。
InfluxQL的select語句來自於SQL中的select形式:
SELECT <stuff> FROM <measurement_name> WHERE <some_conditions>
- 1
如果你想看到planet為Saturn,並且在UTC時間為2015年4月16號12:00:01之後的資料:
SELECT * FROM "foodships" WHERE "planet" = 'Saturn' AND time > '2015-04-16 12:00:01'
- 1
如上例所示,InfluxQL允許您在WHERE子句中指定查詢的時間範圍。您可以使用包含單引號的日期時間字串,格式為YYYY-MM-DD HH:MM:SS.mmm(mmm為毫秒,為可選項,您還可以指定微秒或納秒。您還可以使用相對時間與now()來指代伺服器的當前時間戳:
SELECT * FROM "foodships" WHERE time > now() - 1h
- 1
該查詢輸出measurement為foodships中的資料,其中時間戳比伺服器當前時間減1小時。與now()做計算來決定時間範圍的可選單位有:
| 字母 | 意思 |
|---|---|
| u或µ | 微秒 |
| ms | 毫秒 |
| s | 秒 |
| m | 分鐘 |
| h | 小時 |
| d | 天 |
| w | 星期 |
SQL資料庫和InfluxDB之間存在一些重大差異。SQL中的JOIN不適用於InfluxDB中的measurement。InfluxQL還支援正則表示式,表示式中的運算子,SHOW語句和GROUP BY語句。 InfluxQL功能還包括COUNT,MIN,MAX,MEDIAN,DERIVATIVE等。
### 為什麼InfluxDB不是CRUD的一個解釋
InfluxDB是針對時間序列資料進行了優化的資料庫。這些資料通常來自分散式感測器組,來自大型網站的點選資料或金融交易列表等。
這個資料有一個共同之處在於它只看一個點沒什麼用。一個讀者說,在星期二UTC時間為12:38:35時根據他的電腦CPU利用率為12%,這個很難得出什麼結論。只有跟其他的series結合並可視化時,它變得更加有用。隨著時間的推移開始顯現的趨勢,是我們從這些資料裡真正想要看到的。另外,時間序列資料通常是一次寫入,很少更新。
結果是,由於優先考慮create和read資料的效能而不是update和delete,InfluxDB不是一個完整的CRUD資料庫,更像是一個CR-ud。
2、快速入門
$ wget https://dl.influxdata.com/influxdb/releases/influxdb_1.5.2_amd64.deb
$ sudo dpkg -i influxdb_1.5.2_amd64.deb
$ sudo systemctl start influxdb
$ influx -precision rfc3339
Connected to http://localhost:8086 version 1.2.x
InfluxDB shell 1.2.x
> CREATE DATABASE mydb
>
> SHOW DATABASES
name: databases
---------------
name
_internal
mydb
> USE mydb
Using database mydb
> INSERT cpu,host=serverA,region=us_west value=0.64
>
> SELECT "host", "region", "value" FROM "cpu"
name: cpu
---------
time host region value
2018-05-19T19:28:07.580664347Z serverA us_west 0.64
>
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
3、Influx HttpAPI
詳見官方文件。
| Endpoint | Description |
|---|---|
| /debug/requests | 測試某時間段的使用者(client)query或write的情況。 |
| /ping | 測試資料庫狀態,返回204則正常 |
| /query | 查詢的請求 |
| /write | 寫入資料的請求 |
$ curl http://localhost:8086/debug/requests?seconds=60
{
"user1:123.45.678.91": {"writes":3,"queries":0},
"user1:000.0.0.0": {"writes":0,"queries":16},
"user2:xx.xx.xxx.xxx": {"writes":4,"queries":0}
}
$ curl -sl -I localhost:8086/ping
HTTP/1.1 204 No Content
Content-Type: application/json
Request-Id: [...]
X-Influxdb-Version: 1.4.x
Date: Wed, 08 Nov 2017 00:09:52 GMT
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
### /query
GET http://localhost:8086/query
POST http://localhost:8086/query
| Verb | Query Type |
|---|---|
| GET | 使用場景: SELECT, SHOW |
| POST | 使用場景:SELECT INTO, ALTER, CREATE, DELETE, DROP, GRANT, KILL, REVOKE |
$ curl -G 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * FROM "mymeas"'
$ curl -XPOST 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * INTO "newmeas" FROM "mymeas"'
$ curl -XPOST 'http://localhost:8086/query' --data-urlencode 'q=CREATE DATABASE "mydb"'
$ curl -XPOST 'http://localhost:8086/query?u=myusername&p=mypassword' --data-urlencode 'q=CREATE DATABASE "mydb"'
$ curl -G 'http://localhost:8086/query?db=mydb&epoch=s' --data-urlencode 'q=SELECT * FROM "mymeas";SELECT mean("myfield") FROM "mymeas"'
$ curl -H "Accept: application/csv" -G 'http://localhost:8086/query?db=mydb' --data-urlencode 'q=SELECT * FROM "mymeas"'
// 返回svg格式
name,tags,time,myfield,mytag1,mytag2
mymeas,,1488327378000000000,33.1,mytag1,mytag2
mymeas,,1488327438000000000,12.4,12,14
$ curl -G 'http://localhost:8086/query?db=mydb'
--data-urlencode 'q=SELECT * FROM "mymeas" WHERE "mytag1" = $tag_value AND "myfield" < $field_value'
--data-urlencode 'params={"tag_value":"12","field_value":30}'
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
### /write
$ curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary 'mymeas,mytag=1 myfield=90'
// 支援多行
$ curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary 'mymeas,mytag=3 myfield=89
mymeas,mytag=2 myfield=34 1463689152000000000'
// 支援檔案
$ curl -i -XPOST "http://localhost:8086/write?db=mydb" --data-binary @data.txt
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4、InfluxQL查詢語言
4.1、查詢資料
4.1.1、基本的SELECT語句
SELECT <field_key>[,<field_key>,<tag_key>] FROM <measurement_name>[,<measurement_name>]
- 1
##### SELECT子句
SLECT *:返回所有的field和tag。
SELECT "<field_key>":返回特定的field。
SELECT "<field_key>","<field_key>":返回多個field。
SELECT "<field_key>","<tag_key>":返回特定的field和tag,SELECT在包括一個tag時,必須只是指定一個field。
SELECT "<field_key>"::field,"<tag_key>"::tag:返回特定的field和tag,::[field | tag]語法指定識別符號的型別。 使用此語法來區分具有相同名稱的field key和tag key。
##### FROM子句
FROM <measurement_name>:從單個measurement返回資料。如果使用CLI需要先用USE指定資料庫,並且使用的DEFAULT儲存策略。如果您使用HTTP API,需要用db引數來指定資料庫,也是使用DEFAULT儲存策略。
FROM <measurement_name>,<measurement_name>:從多個measurement中返回資料。
FROM <database_name>.<retention_policy_name>.<measurement_name>:從一個完全指定的measurement中返回資料,這個完全指定是指指定了資料庫和儲存策略。
FROM <database_name>..<measurement_name>:從一個使用者指定的資料庫中返回儲存策略為DEFAULT的資料。
##### 引號
如果識別符號包含除[A-z,0-9,_]之外的字元,如果它們以數字開頭,或者如果它們是InfluxQL關鍵字,那麼它們必須用雙引號。比如把emoji當作measurement名。
注意:查詢的語法與行協議是不同的。
#### 例子
// 例一:從單個measurement查詢所有的field和tag
> SELECT * FROM "h2o_feet"
// 例二:從單個measurement中查詢特定tag和field
> SELECT "level description","location","water_level" FROM "h2o_feet"
// 例三:從單個measurement中選擇特定的tag和field,並提供其識別符號型別
> SELECT "level description"::field,"location"::tag,"water_level"::field FROM "h2o_feet"
// 例四:從單個measurement查詢所有field
> SELECT *::field FROM "h2o_feet"
// 例五:從measurement中選擇一個特定的field並執行基本計算
> SELECT ("water_level" * 2) + 4 from "h2o_feet"
// 例六:從多個measurement中查詢資料
> SELECT * FROM "h2o_feet","h2o_pH"
// 例七:從完全限定的measurement中選擇所有資料
> SELECT * FROM "NOAA_water_database"."autogen"."h2o_feet"
// 例八:從特定資料庫中查詢measurement的所有資料
> SELECT * FROM "NOAA_water_database".."h2o_feet"
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
4.1.2、WHERE子句
WHERE子句在field,tag和timestamp上支援conditional_expressions.
SELECT_clause FROM_clause WHERE <conditional_expression> [(AND|OR) <conditional_expression> [...]]
- 1
##### fields
WHERE子句支援field value是字串,布林型,浮點數和整數這些型別。
在WHERE子句中單引號來表示字串欄位值。具有無引號字串欄位值或雙引號字串欄位值的查詢將不會返回任何資料,並且在大多數情況下也不會返回錯誤。
field_key <operator> ['string' | boolean | float | integer]
- 1
支援的操作符:
= 等於
<> 不等於
!= 不等於
> 大於
>= 大於等於
< 小於
<= 小於等於
##### tags
WHERE子句中的用單引號來把tag value引起來。具有未用單引號的tag或雙引號的tag查詢將不會返回任何資料,並且在大多數情況下不會返回錯誤。
tag_key <operator> ['tag_value']
- 1
支援的操作符:
= 等於
<> 不等於
!= 不等於
##### timestamps
對於大多數SELECT語句,預設時間範圍為UTC的1677-09-21 00:12:43.145224194到2262-04-11T23:47:16.854775806Z。 對於只有GROUP BY time()子句的SELECT語句,預設時間範圍在UTC的1677-09-21 00:12:43.145224194和now()之間。
#### 例子
// 例二:查詢有特定field的key value為字串的資料
> SELECT * FROM "h2o_feet" WHERE "level description" = 'below 3 feet'
// 例三:查詢有特定field的key value並且帶計算的資料
> SELECT * FROM "h2o_feet" WHERE "water_level" + 2 > 11.9
// 例六:根據時間戳來過濾資料
> SELECT * FROM "h2o_feet" WHERE time > now() - 7d
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
4.1.3、GROUP BY子句
GROUP BY子句後面可以跟使用者指定的tags或者是一個時間間隔。
### GROUP BY tags
SELECT_clause FROM_clause [WHERE_clause] GROUP BY [* | <tag_key>[,<tag_key]]
- 1
GROUP BY *:對結果中的所有tag作group by。
GROUP BY <tag_key>:對結果按指定的tag作group by。
GROUP BY <tag_key>,<tag_key>:對結果資料按多個tag作group by,其中tag key的順序沒所謂。
#### 例子
// 例一:對單個tag作group by
> SELECT MEAN("water_level") FROM "h2o_feet" GROUP BY "location"
name: h2o_feet
tags: location=coyote_creek
time mean
---- ----
1970-01-01T00:00:00Z 5.359342451341401
name: h2o_feet
tags: location=santa_monica
time mean
---- ----
1970-01-01T00:00:00Z 3.530863470081006
# epoch 0(`1970-01-01T00:00:00Z`)通常用作等效的空時間戳。
// 例二:對多個tag作group by
> SELECT MEAN("index") FROM "h2o_quality" GROUP BY location,randtag
name: h2o_quality
tags: location=coyote_creek, randtag=1
time mean
---- ----
1970-01-01T00:00:00Z 50.69033760186263
name: h2o_quality
tags: location=coyote_creek, randtag=2
time mean
---- ----
1970-01-01T00:00:00Z 49.661867544220485
// 例三:對所有tag作group by
> SELECT MEAN("index") FROM "h2o_quality" GROUP BY *
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
### GROUP BY time()
GROUP BY time()返回結果按指定的時間間隔group by。
SELECT <function>(<field_key>) FROM_clause WHERE <time_range> GROUP BY time(<time_interval>,<offset_interval>),[tag_key] [fill(<fill_option>)]
- 1
time(time_interval,offset_interval) :
time_interval是一個時間duration。決定了InfluxDB按什麼時間間隔group by。例如:time_interval為5m則在WHERE子句中指定的時間範圍內將查詢結果分到五分鐘時間組裡。
offset_interval是一個持續時間。它向前或向後移動InfluxDB的預設時間界限。offset_interval可以為正或負。
fill(<fill_option>) :可選的,它會更改不含資料的時間間隔的返回值。
覆蓋範圍:基本GROUP BY time()查詢依賴於time_interval,offset_interval和InfluxDB的預設時間邊界來確定每個時間間隔中包含的原始資料以及查詢返回的時間戳。
##### 例子
// 例二:時間間隔為12分鐘並且還對tag key作group by
> SELECT COUNT("water_level") FROM "h2o_feet" WHERE time >= '2015-08-18T00:00:00Z' AND time <= '2015-08-18T00:30:00Z' GROUP BY time(12m),"location"
name: h2o_feet
tags: location=coyote_creek
time count
---- -----
2015-08-18T00:00:00Z 2
2015-08-18T00:12:00Z 2
2015-08-18T00:24:00Z 2
name: h2o_feet
tags: location=santa_monica
time count
---- -----
2015-08-18T00:00:00Z 2
2015-08-18T00:12:00Z 2
2015-08-18T00:24:00Z 2
// 例一:查詢結果間隔按18分鐘group by,並將預設時間邊界向前移動
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-08-18T00:06:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(18m,6m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:06:00Z 7.884666666666667
2015-08-18T00:24:00Z 7.502333333333333
2015-08-18T00:42:00Z 7.108666666666667
> SELECT MEAN("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-08-18T00:06:00Z' AND time <= '2015-08-18T00:54:00Z' GROUP BY time(18m)
name: h2o_feet
time mean
---- ----
2015-08-18T00:00:00Z 7.946
2015-08-18T00:18:00Z 7.6323333333333325
2015-08-18T00:36:00Z 7.238666666666667
2015-08-18T00:54:00Z 6.982
# fill()的例子
> SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-09-18T16:00:00Z' AND time <= '2015-09-18T16:42:00Z' GROUP BY time(12m)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z 3.599
2015-09-18T16:12:00Z 3.402
2015-09-18T16:24:00Z 3.235
2015-09-18T16:36:00Z
> SELECT MAX("water_level") FROM "h2o_feet" WHERE "location"='coyote_creek' AND time >= '2015-09-18T16:00:00Z' AND time <= '2015-09-18T16:42:00Z' GROUP BY time(12m) fill(100)
name: h2o_feet
--------------
time max
2015-09-18T16:00:00Z 3.599
2015-09-18T16:12:00Z 3.402
2015-09-18T16:24:00Z 3.235
2015-09-18T16:36:00Z 100
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
- 12
- 13
- 14
- 15
- 16
- 17
- 18
- 19
- 20
- 21
- 22
- 23
- 24
- 25
- 26
- 27
- 28
- 29
- 30
- 31
- 32
- 33
- 34
- 35
- 36
- 37
- 38
- 39
- 40
- 41
- 42
- 43
- 44
- 45
- 46
- 47
- 48
- 49
- 50
- 51
- 52
- 53
- 54
- 55
- 56
- 57
- 58
- 59
- 60
## ORDER BY TIME DESC
預設情況下,InfluxDB以升序的順序返回結果; 返回的第一個點具有最早的時間戳,返回的最後一個點具有最新的時間戳。 ORDER BY time DESC反轉該順序,使得InfluxDB首先返回具有最新時間戳的點。
SELECT_clause [INTO_clause] FROM_clause [WHERE_clause] [GROUP_BY_clause] ORDER BY time DESC
- 1
### 例子
// 例一:首先返回最新的點
> SELECT "water_level" FROM "h2o_feet" WHERE "location" = 'santa_monica' ORDER BY time DESC
name: h2o_feet
time water_level
---- -----------
2015-09-18T21:42:00Z 4.938
2015-09-18T21:36:00Z 5.066
[...]
2015-08-18T00:06:00Z 2.116
2015-08-18T00:00:00Z 2.064
- 1
- 2
- 3
- 4
- 5
- 6
- 7
- 8
- 9
- 10
- 11
4.1.4、INTO子句
INTO子句將查詢的結果寫入到使用者自定義的measurement中。
SELECT_clause INTO <measurement_name> FROM_clause [WHERE_clause] [GROUP_BY_clause]
- 1
INTO支援多種格式的measurement。
INTO <measurement_name>:寫入到特定measurement中,用CLI時,寫入到用USE指定的資料庫,保留策略為DEFAULT,用HTTP API時,寫入到db引數指定的資料庫,保留策略為DEFAULT。INTO <database_name>.<retention_policy_name>.<measurement_name>:寫入到完整指定的measurement中。INTO <database_name>..<measurement_name>:寫入到指定資料庫保留策略為DEFAULT。INTO <database_name>.<retention_policy_name>.:MEASUREMENT FROM /<regular_expression>/:將資料寫入與FROM子句中正則表示式匹配的使用者指定資料庫和保留策略的所有measurement。:MEASUREMENT是對FROM子句中匹配的每個measurement的反向引用。(相當於從一個庫的這些表,拷貝到新資料來源的同名表下)
### 例子
// 例一:重新命名資料庫
> SELECT * INTO "copy_NOAA_water_database"."autogen".:MEASUREMENT FROM "NOAA_water_database"."autogen"./.*/ GROUP BY *
name: result
time written
---- -------
0 76290
因為influxdb不支援重新命名資料庫,所以可以這樣重新匯入一邊資料。`group by *`的作用是將原measurement中的tag key,依舊在新的measurement當成tag key。如果不加,
- 1
- 2
- 3
- 4
- 5