做一個爬蟲專用的url解析器
思路分析
首先是獲取三個或以上的url(帶引數的url)
然後通過字串方法將url中的基礎url跟引數分離開
通過對比多個url中的同一個引數的值,
將引數分成三類
一類為不變的引數,一類為會改變的引數,還有一類是時有時無(可有可無)的引數
最後做成GUI,介面設想如下
在左上方的text窗輸入url,點選加入,在右側列表窗會顯示已新增的url,如果存在希望刪除的url,點選列表窗中對應的url,點選刪除即可從列表窗中移除,點選解析,即對url進行解析
程式碼實現
GUI部分
QT介面雖易做,可惜還沒時間去研究QT的gui後臺程式碼怎麼實現,所以還是用tkinter好了
以下是介面程式碼
from tkinter import * import tkinter.messagebox import re from urlparser import URLparser from threading import Timer import time import json def ListboxClick(event): keyname = listbox_result.get(ACTIVE) content = json.loads(label_hidden["text"]) label_result["text"] = content[keyname] def timmer(): now = "現在時間 >>> " now += time.strftime("%Y - %m - %d %H : %M : %S") label_time["text"] = now timer = Timer(1, timmer) timer.start() def Button_rebootClick(event): result = tkinter.messagebox.askquestion(title="提示", message="是否重置?") if result == "no": return None text_input.delete(0.0, END) listbox_show.delete(0, 29) label_result["text"] = "" label_number["text"] = "url個數:0" def Button_joinClick(event): num = int(label_number["text"].split(":")[-1]) if num == 30: return None # 獲得輸入框內容 url = text_input.get(0.0, END)[0:-1] # 刪除輸入框內容 text_input.delete(0.0, END) # 匹配正則表示式,是否為空 space_reg = re.compile(r"^\s*$") if space_reg.match(url): return None # 匹配正則表示式,是否為正常的url格式 url_reg = re.compile(r"^(https?|ftp|file)://[-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|]$") if not url_reg.match(url): result = tkinter.messagebox.askquestion(title="url匹配提示", message="您輸入的url格式可能不正確,確定要新增?") if result == "no": return None # 加入列表框 listbox_show.insert(END, url) num += 1 # 修改個數 label_number["text"] = "url個數:" + str(num) def Button_clearClick(event): num = int(label_number["text"].split(":")[-1]) if num == 0: return # 刪除列表框選中內容 listbox_show.delete(ACTIVE) num -= 1 # 修改個數 label_number["text"] = "url個數:" + str(num) def Button_parseClick(event): # 第一步,取得列表框存放的所有url reg = re.compile(r"^\s*$") url_list = [] index = 0 while True: url = listbox_show.get(index) if reg.match(url): break url_list.append(url) index += 1 # 第二步,傳入後臺處理,返回結果 parser = URLparser.UrlParser() result = parser.parse(url_list) for key, value in result.items(): listbox_result.insert(END, key) if key.startswith("主體url:"): label_result["text"] = value # 第三步,將獲得的結果放到隱藏標籤裡 result = json.dumps(result) label_hidden["text"] = result # 主視窗 window = Tk() window.maxsize(1000, 600) window.minsize(1000, 600) window.title("帶引數url解析器") # 文字輸入框 Label(window, text="請在下方輸入框輸入url", font=(15,)).place(x=20, y=10) text_input = Text(window, width=50, height=10, borderwidth=5, relief=SUNKEN, font=(15,)) text_input.place(x=20, y=40) # url列表框 Label(window, text="已輸入的url列表", font=(15,)).place(x=570, y=10) label_number = Label(window, text="url個數:0", font=(15,)) label_number.place(x=890, y=10) # # 框架 frame_listbox_show = Frame(window) frame_listbox_show.place(x=570, y=40) # # 滾動條 show_scx = Scrollbar(frame_listbox_show, orient=HORIZONTAL) show_scx.pack(side=BOTTOM, fill=X) show_scy = Scrollbar(frame_listbox_show) show_scy.pack(side=RIGHT, fill=Y) # # url列表框 listbox_show = Listbox(frame_listbox_show, width=48, height=28, borderwidth=5, relief=SUNKEN, font=(15,), xscrollcommand=show_scx.set, yscrollcommand=show_scy.set) listbox_show.pack(side=LEFT, fill=BOTH) show_scx.config(command=listbox_show.xview) show_scy.config(command=listbox_show.yview) # 結果列表框 Label(window, text="url解析結果如下", font=(15,)).place(x=20, y=215) # # 框架 frame_listbox_result = Frame(window) frame_listbox_result.place(x=20, y=242) # # 滾動條 result_scx = Scrollbar(frame_listbox_result, orient=HORIZONTAL) result_scx.pack(side=BOTTOM, fill=X) result_scy = Scrollbar(frame_listbox_result) result_scy.pack(side=RIGHT, fill=Y) # # 結果列表框 listbox_result = Listbox(frame_listbox_result, width=28, height=17, relief=SUNKEN, font=(15,), borderwidth=5, xscrollcommand=result_scx.set, yscrollcommand=result_scy.set) listbox_result.pack(side=LEFT) result_scx.config(command=listbox_result.xview) result_scy.config(command=listbox_result.yview) label_hidden = Label(window, width=10, height=10, text="這是隱藏標籤") label_hidden.place(x=300, y=250) label_result = Label(window, font=(15,), borderwidth=5, relief=SUNKEN, width=30, height=19) label_result.place(x=295, y=242) # 按鈕 # # 加入 button_join = Button(window, text="加 入", width=10, height=1, font=(15,), borderwidth=5, relief=RAISED) button_join.place(x=450, y=50) # # 刪除 button_clear = Button(window, text="刪 除", width=10, height=1, font=(15,), borderwidth=5, relief=RAISED) button_clear.place(x=450, y=108) # # 解析 button_parse = Button(window, text="解 析", width=10, height=1, font=(15,), borderwidth=5, relief=RAISED) button_parse.place(x=450, y=166) # 底部欄 button_reboot = Button(window, text="重 置", width=10, height=1, borderwidth=5, relief=RAISED, font=(15,)) button_reboot.place(x=882, y=562) now = "現在時間 >>> " now += time.strftime("%Y - %m - %d %H : %M : %S") label_time = Label(window, text=now, font=(15,)) label_time.place(x=20, y=570) # 繫結事件 # # 加入按鈕左鍵點選事件 button_join.bind("<ButtonRelease-1>", Button_joinClick) # # 刪除按鈕左鍵點選事件 button_clear.bind("<1>", Button_clearClick) # # 解析按鈕左鍵點選事件 button_parse.bind("<1>", Button_parseClick) # # 重置按鈕左鍵點選事件 button_reboot.bind("<ButtonRelease-1>", Button_rebootClick) # # 列表框點選事件 listbox_result.bind("<1>", ListboxClick) # 設定定時器 timer = Timer(1, timmer) timer.start() # 主視窗執行 window.mainloop()
暫時還沒有封裝成類,介面也一般,不過這次加了定時器,可以定時重新整理內容,牛刀小試,每秒重新整理一次時間好了
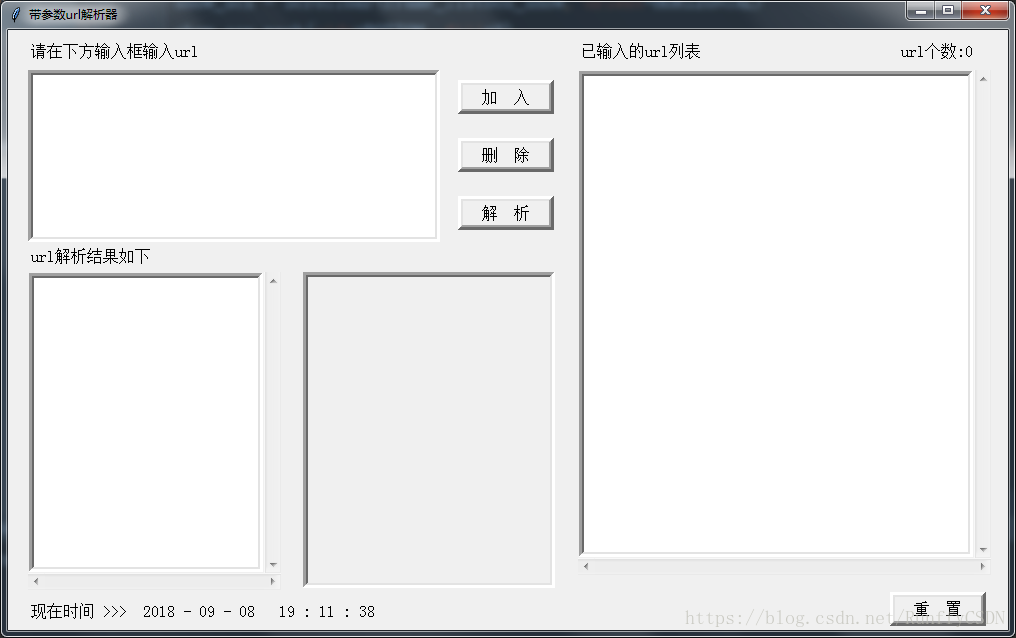
介面看著其實還不賴
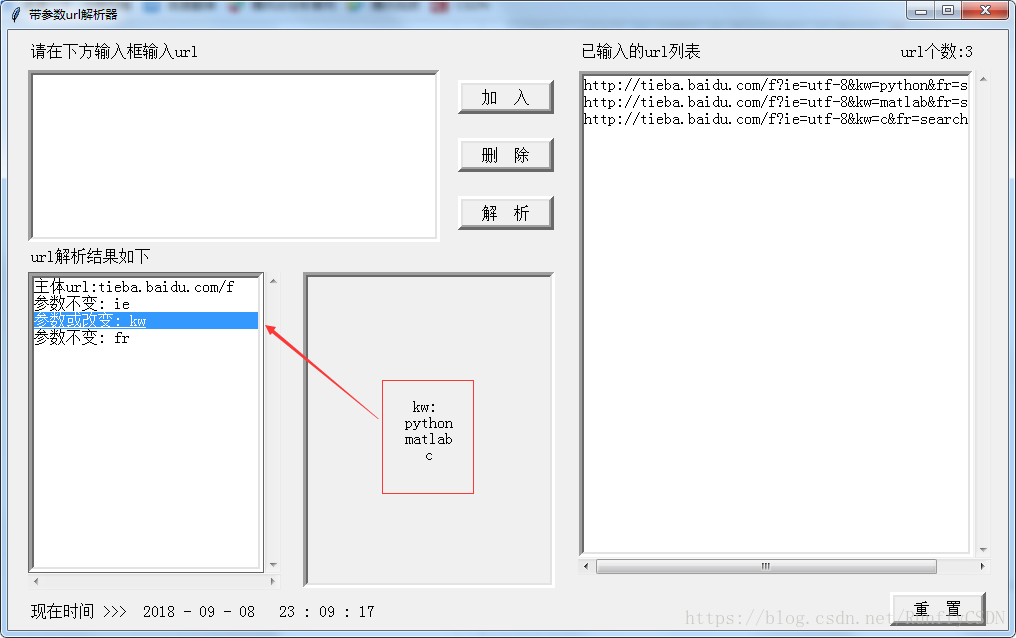
兩個結果窗顯示的原理大概就是將加入的url送到後臺,解析後得到的結果是一個字典
左邊的列表框顯示的是字典的鍵,右邊的標籤顯示的是單一某鍵對應的鍵值,一般就是某個引數的結果羅列
通過點選右側的列表框的具體內容決定右側標籤顯示何種內容
在顯示結果的標籤框 label_result 背後由一個專門存放全部資料的隱藏標籤,即是程式碼中的 label_hidden
需要切換內容的時候即從 label_hidden 中提取出來資料以呼叫
後端url處理部分
通過前端得到的一個列表
首先分析一下url是否為有?存在的帶參url,如果不是,則返回帶有錯誤提示資訊的字典
然後遍歷分析url主體是否一致(為了避免有時手殘輸錯別的url),確定一致了才僅需進行引數解析,但需要注意的是,即便是同一個網站,也會有出現http或https各種開頭的情況,為了避免這種狀況,url主體只取到https://後面到?前面的部分來進行對比
接下來就是引數分析,其實也簡單,以&分割引數,獲得引數鍵值對列表,再對引數列表進行遍歷,以=分割鍵與值,將擁有相同鍵名的鍵值存放到另一字典中相同鍵名下的列表裡
最後將存放參數的字典進行遍歷,
第一步分析是否為可預設引數,鍵值中的引數列表的長度小於輸入url列表的長度即為存在預設,意味著該引數可預設,如果是可預設,continue繼續下一次迴圈
第二步分析是否為不變引數,計算鍵值中的引數列表的集合長度,如果為1,即為不變引數
否則則是或改變引數
最後將分析結果做成字典,輸出到前端
具體程式碼如下
import re
class UrlParser(object):
def parse(self, url_list):
'''
:param url_list: 一個至少包含3個url的列表
:return:
'''
key_list = []
result = {}
for index, url in enumerate(url_list):
# 第一步,分離url主體,若存在不相同,返回提示
if "?" not in url:
return {str(index + 1): "第%d個url不屬於帶引數型url" % (index + 1)}
all_part = url.split("?")
url_reg = re.compile(r"^(https?|ftp|file)://([-A-Za-z0-9+&@#/%?=~_|!:,.;]+[-A-Za-z0-9+&@#/%=~_|])$")
uurl = url_reg.findall(all_part[0])[0][1]
if index > 0:
if uurl != main_url:
return {str(index + 1): "第%d個url的主體url與其前面的url主體不相同" % (index + 1)}
else:
main_url = uurl
all_params = all_part[1]
# 第二步,分離引數
param = all_params.split("&")
# 第三步,分離鍵值對
for p in param:
k_v = p.split("=")
key = k_v[0]
value = k_v[1]
if key not in key_list:
result[key] = []
key_list.append(key)
result[key].append(value)
# 解析引數
num = len(url_list)
output = {"主體url:" + main_url: "雙擊左側參\n數檢視詳情"}
for key, value in result.items():
# 判斷是否為可預設引數
if len(value) < num:
output["引數可預設: " + key] = key + " : \n" + "\n".join(value) + "\nNone" * (num - len(value))
continue
# 判斷是否為不變引數
if len(set(value)) == 1:
output["引數不變: " + key] = key + " : \n" + "\n".join(value)
else:
output["引數或改變: " + key] = key + ": \n" + "\n".join(value)
return output
結果展示
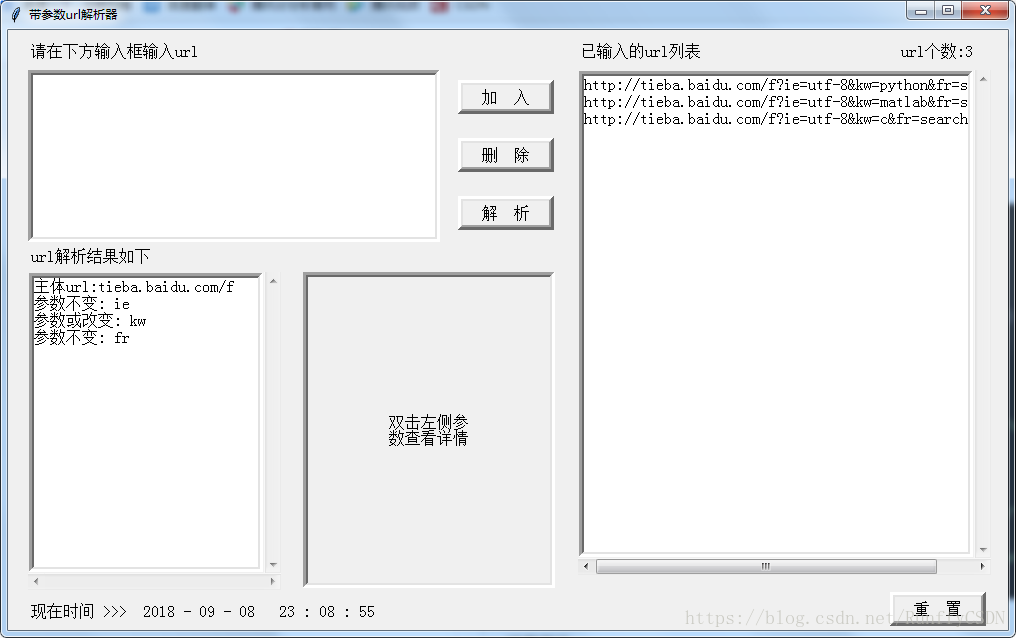
取了百度貼吧三個搜尋結果下的url,分別是python,matlab,c
http://tieba.baidu.com/f?ie=utf-8&kw=python&fr=search
http://tieba.baidu.com/f?ie=utf-8&kw=matlab&fr=search
http://tieba.baidu.com/f?ie=utf-8&kw=c&fr=search
加入到列表框之後,點選""解析""