
swift物件儲存
swift物件儲存
簡介
OpenStack Object Storage(Swift)是OpenStack開源雲端計算專案的子專案之一,被稱為物件儲存,提供了強大的擴充套件性、冗餘和永續性。物件儲存,用於永久型別的靜態資料的長期儲存。
Swift 最初是由 Rackspace 公司開發的高可用分散式物件儲存服務,並於 2010 年貢獻給 OpenStack 開源社群作為其最初的核心子專案之一,為其 Nova 子專案提供虛機映象儲存服務。Swift 構築在比較便宜的標準硬體儲存基礎設施之上,無需採用 RAID(磁碟冗餘陣列),通過在軟體層面引入一致性雜湊技術和資料冗餘性,犧牲一定程度的資料一致性來達到高可用性和可伸縮性,支援多租戶模式、容器和物件讀寫操作,適合解決網際網路的應用場景下非結構化資料儲存問題。
基本原理
1.一致性雜湊(Consistent Hashing)
面對海量級別的物件,需要存放在成千上萬臺伺服器和硬碟裝置上,首先要解決定址問題,即如何將物件分佈到這些裝置地址上。Swift 是基於一致性雜湊技術,通過計算可將物件均勻分佈到虛擬空間的虛擬節點上,在增加或刪除節點時可大大減少需移動的資料量;虛擬空間大小通常採用 2 的 n 次冪,便於進行高效的移位操作;然後通過獨特的資料結構 Ring(環)再將虛擬節點對映到實際的物理儲存裝置上,完成定址過程。 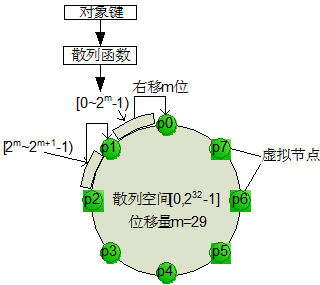
以逆時針方向遞增的雜湊空間有 4 個位元組長共 32 位,整數範圍是[0~232-1];將雜湊結果右移 m 位,可產生 232-m個虛擬節點,例如 m=29 時可產生 8 個虛擬節點。在實際部署的時候需要經過仔細計算得到合適的虛擬節點數,以達到儲存空間和工作負載之間的平衡。
2.資料一致性模型
按照 Eric Brewer 的 CAP(Consistency,Availability,Partition Tolerance)理論,無法同時滿足 3 個方面,Swift 放棄嚴格一致性(滿足 ACID 事務級別),而採用最終一致性模型(Eventual Consistency),來達到高可用性和無限水平擴充套件能力。為了實現這一目標,Swift 採用 Quorum 仲裁協議(Quorum 有法定投票人數的含義):
(1)定義:N:資料的副本總數;W:寫操作被確認接受的副本數量;R:讀操作的副本數量
(2)強一致性:R+W>N,以保證對副本的讀寫操作會產生交集,從而保證可以讀取到最新版本;如果 W=N,R=1,則需要全部更新,適合大量讀少量寫操作場景下的強一致性;如果 R=N,W=1,則只更新一個副本,通過讀取全部副本來得到最新版本,適合大量寫少量讀場景下的強一致性。
(3)弱一致性:R+W<=N,如果讀寫操作的副本集合不產生交集,就可能會讀到髒資料;適合對一致性要求比較低的場景。
Swift 針對的是讀寫都比較頻繁的場景,所以採用了比較折中的策略,即寫操作需要滿足至少一半以上成功 W >N/2,再保證讀操作與寫操作的副本集合至少產生一個交集,即 R+W>N。Swift 預設配置是 N=3,W=2>N/2,R=1 或 2,即每個物件會存在 3 個副本,這些副本會盡量被儲存在不同區域的節點上;W=2 表示至少需要更新 2 個副本才算寫成功;當 R=1 時意味著某一個讀操作成功便立刻返回,此種情況下可能會讀取到舊版本(弱一致性模型);當 R=2 時,需要通過在讀操作請求頭中增加 x-newest=true 引數來同時讀取 2 個副本的元資料資訊,然後比較時間戳來確定哪個是最新版本(強一致性模型);如果資料出現了不一致,後臺服務程序會在一定時間視窗內通過檢測和複製協議來完成資料同步,從而保證達到最終一致性。
3.環的資料結構
環是為了將虛擬節點(分割槽)對映到一組物理儲存裝置上,並提供一定的冗餘度而設計的,其資料結構由以下資訊組成:
儲存裝置列表、裝置資訊包括唯一標識號(id)、區域號(zone)、權重(weight)、IP 地址(ip)、埠(port)、裝置名稱(device)、元資料(meta)。
分割槽到裝置對映關係(replica2part2dev_id 陣列)
計算分割槽號的位移(part_shift 整數,即圖 1 中的 m)
以查詢一個物件的計算過程為例: 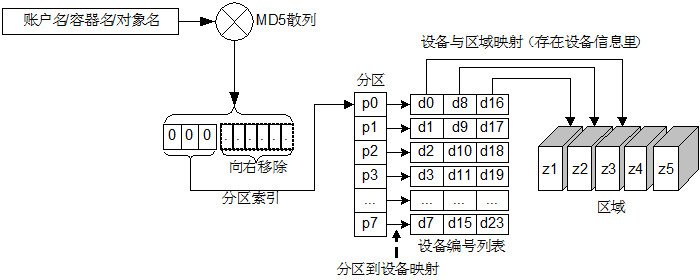
使用物件的層次結構 account/container/object 作為鍵,使用 MD5 雜湊演算法得到一個雜湊值,對該雜湊值的前 4 個位元組進行右移操作得到分割槽索引號,移動位數由上面的 part_shift 設定指定;按照分割槽索引號在分割槽到裝置對映表(replica2part2dev_id)裡查詢該物件所在分割槽的對應的所有裝置編號,這些裝置會被儘量選擇部署在不同區域(Zone)內,區域只是個抽象概念,它可以是某臺機器,某個機架,甚至某個建築內的機群,以提供最高級別的冗餘性,建議至少部署 5 個區域;權重引數是個相對值,可以來根據磁碟的大小來調節,權重越大表示可分配的空間越多,可部署更多的分割槽。
Swift 為賬戶,容器和物件分別定義了的環,查詢賬戶和容器的是同樣的過程。
4.資料模型
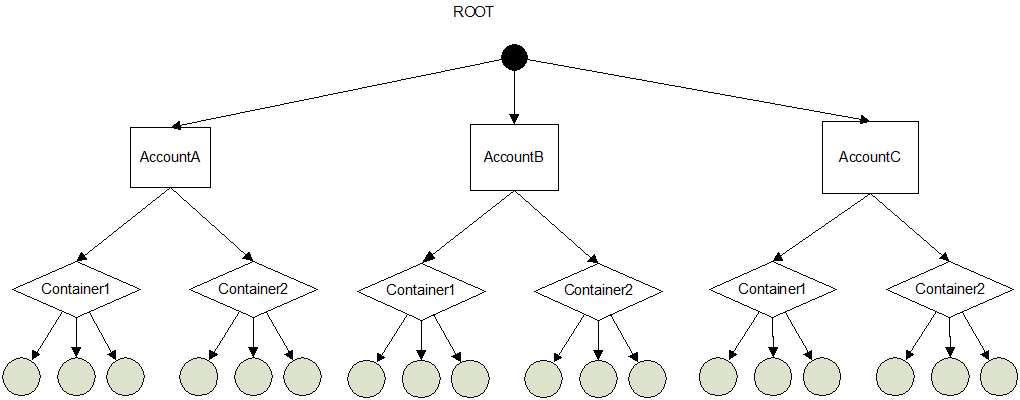
Swift 採用層次資料模型,共設三層邏輯結構:Account/Container/Object(即賬戶/容器/物件),每層節點數均沒有限制,可以任意擴充套件。這裡的賬戶和個人賬戶不是一個概念,可理解為租戶,用來做頂層的隔離機制,可以被多個個人賬戶所共同使用;容器代表封裝一組物件,類似資料夾或目錄;葉子節點代表物件,由元資料和內容兩部分組成,如圖 4 所示:
5.系統架構
Swift 採用完全對稱、面向資源的分散式系統架構設計,所有元件都可擴充套件,避免因單點失效而擴散並影響整個系統運轉;通訊方式採用非阻塞式 I/O 模式,提高了系統吞吐和響應能力。 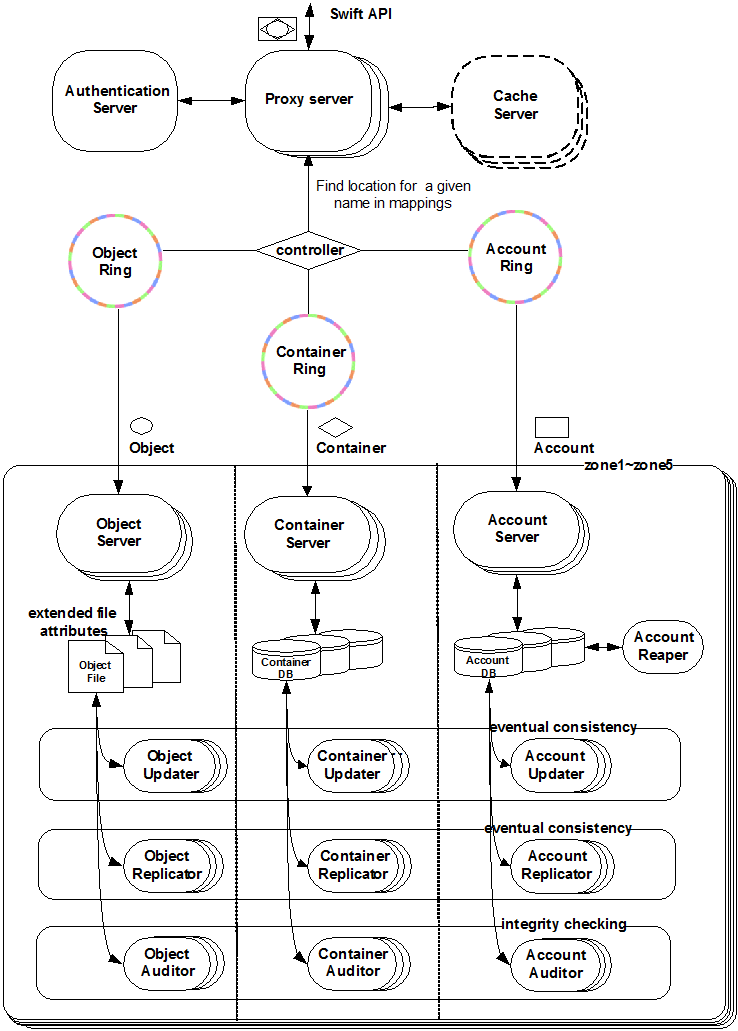
代理服務(Proxy Server):對外提供物件服務 API,會根據環的資訊來查詢服務地址並轉發使用者請求至相應的賬戶、容器或者物件服務;由於採用無狀態的 REST 請求協議,可以進行橫向擴充套件來均衡負載。 認證服務(Authentication Server):驗證訪問使用者的身份資訊,並獲得一個物件訪問令牌(Token),在一定的時間內會一直有效;驗證訪問令牌的有效性並快取下來直至過期時間。 快取服務(Cache Server):快取的內容包括物件服務令牌,賬戶和容器的存在資訊,但不會快取物件本身的資料;快取服務可採用 Memcached 叢集,Swift 會使用一致性雜湊演算法來分配快取地址。 賬戶服務(Account Server):提供賬戶元資料和統計資訊,並維護所含容器列表的服務,每個賬戶的資訊被儲存在一個 SQLite 資料庫中。 容器服務(Container Server):提供容器元資料和統計資訊,並維護所含物件列表的服務,每個容器的資訊也儲存在一個 SQLite 資料庫中。 物件服務(Object Server):提供物件元資料和內容服務,每個物件的內容會以檔案的形式儲存在檔案系統中,元資料會作為檔案屬性來儲存,建議採用支援擴充套件屬性的 XFS 檔案系統。 複製服務(Replicator):會檢測本地分割槽副本和遠端副本是否一致,具體是通過對比雜湊檔案和高階水印來完成,發現不一致時會採用推式(Push)更新遠端副本,例如物件複製服務會使用遠端檔案拷貝工具 rsync 來同步;另外一個任務是確保被標記刪除的物件從檔案系統中移除。 更新服務(Updater):當物件由於高負載的原因而無法立即更新時,任務將會被序列化到在本地檔案系統中進行排隊,以便服務恢復後進行非同步更新;例如成功建立物件後容器伺服器沒有及時更新物件列表,這個時候容器的更新操作就會進入排隊中,更新服務會在系統恢復正常後掃描佇列並進行相應的更新處理。 審計服務(Auditor):檢查物件,容器和賬戶的完整性,如果發現位元級的錯誤,檔案將被隔離,並複製其他的副本以覆蓋本地損壞的副本;其他型別的錯誤會被記錄到日誌中。 賬戶清理服務(Account Reaper):移除被標記為刪除的賬戶,刪除其所包含的所有容器和物件。
特性
1.極高的資料永續性
資料永續性和系統可用性不同,指的是資料的可靠性,資料儲存到系統後,到某一天丟失的可能性。AS3的資料永續性是11個9,即如果儲存1萬個(4個0)檔案到S3中,1千萬(7個0)年之後,可能會丟失1個檔案。
我們從理論上測算過,Swift在5個Zone、5×10個儲存節點的環境下,資料複製份是為3,資料永續性的SLA能達到10個9。
2.完全對稱的系統架構
“對稱”意味著Swift中各節點可以完全對等,能極大地降低系統維護成本。
無限的可擴充套件性
(1)資料儲存容量無限可擴充套件;(2)Swift效能(如QPS、吞吐量等)可線性提升
Swift是完全對稱的架構,擴容只需簡單地新增機器,系統會自動完成資料遷移等工作,使各儲存節點重新達到平衡狀態。
3.無單點故障
元資料問題,Swift的元資料儲存是完全均勻隨機分佈的,並且與物件檔案儲存一樣,元資料也會儲存多份。
4.簡單、可依賴
設計簡單
應用場景
最典型的應用是網盤類的儲存引擎,比如Dropbox背後使用的就是AS3。在OpenStack中還可以與映象服務Glance結合,為其儲存映象檔案。另外,由於Swift的無限擴充套件能力,非常適合用於儲存日誌檔案和資料備份倉庫。
架構概述
Swift主要有三個組成部分:Proxy Server、Storage Server和Consistency Server。其架構如圖1所示,其中Storage和Consistency服務均允許在Storage Node上。Auth認證服務目前已從Swift中剝離出來,使用OpenStack的認證服務Keystone,目的在於實現統一OpenStack各個專案間的認證管理。
API介面
Swift 通過 Proxy Server 向外提供基於 HTTP 的 REST 服務介面,對賬戶、容器和物件進行 CRUD 等操作。在訪問 Swift 服務之前,需要先通過認證服務(keystone)獲取訪問令牌,然後在傳送的請求中加入頭部資訊 X-Auth-Token。下面是請求返回賬戶中的容器列表的示例:
GET /v1/<account> HTTP/1.1
Host: storage.swift.com
X-Auth-Token: eaaafd18-0fed-4b3a-81b4-663c99ec1cbb 響應頭部資訊中包含狀態碼 200,容器列表包含在響應體中: HTTP/1.1 200 Ok Date: Thu, 07 Jan 2013 18:57:07 GMT Server: Apache Content-Type: text/plain; charset=UTF-8 Content-Length: 32 images movies documents backups
結束語
OpenStack Swift 作為穩定和高可用的開源物件儲存被很多企業作為商業化部署,如新浪的 App Engine 已經上線並提供了基於 Swift 的物件儲存服務,韓國電信的 Ucloud Storage 服務。有理由相信,因為其完全的開放性、廣泛的使用者群和社群貢獻者,Swift 可能會成為雲端儲存的開放標準,從而打破 Amazon S3 在市場上的壟斷地位,推動雲端計算在朝著更加開放和可互操作的方向前進。
一切才是開始
看完swift,發現原來雲端計算領域更為龐大。。。一切學習都是開始啊!
基於Quorum投票的冗餘控制演算法
1.簡介
Quorom 機制,是一種分散式系統中常用的,用來保證資料冗餘和最終一致性的投票演算法,其主要數學思想來源於鴿巢原理。
在有冗餘資料的分散式儲存系統當中,冗餘資料物件會在不同的機器之間存放多份拷貝。但是同一時刻一個數據物件的多份拷貝只能用於讀或者用於寫。
該演算法可以保證同一份資料物件的多份拷貝不會被超過兩個訪問物件讀寫。
演算法來源於[Gifford, 1979][3][1]。 分散式系統中的每一份資料拷貝物件都被賦予一票。每一個操作必須要獲得最小的讀票數(Vr)或者最小的寫票數(Vw)才能讀或者寫。如果一個系統有V票(意味著一個數據物件有V份冗餘拷貝),那麼這最小讀寫票必須滿足:
Vr + Vw > V
Vw > V/2
第一條規則保證了一個數據不會被同時讀寫。當一個寫操作請求過來的時候,它必須要獲得Vw個冗餘拷貝的許可。而剩下的數量是V-Vw 不夠Vr,因此不能再有讀請求過來了。同理,當讀請求已經獲得了Vr個冗餘拷貝的許可時,寫請求就無法獲得許可了。
第二條規則保證了資料的序列化修改。一份資料的冗餘拷貝不可能同時被兩個寫請求修改。
2.應用
在分散式系統中,冗餘資料是保證可靠性的手段,因此冗餘資料的一致性維護就非常重要。一般而言,一個寫操作必須要對所有的冗餘資料都更新完成了,才能稱為成功結束。比如一份資料在5臺裝置上有冗餘,因為不知道讀資料會落在哪一臺裝置上,那麼一次寫操作,必須5臺裝置都更新完成,寫操作才能返回。
對於寫操作比較頻繁的系統,這個操作的瓶頸非常大。Quorum演算法可以讓寫操作只要寫完3臺就返回。剩下的由系統內部緩慢同步完成。而讀操作,則需要也至少讀3臺,才能保證至少可以讀到一個最新的資料。
Quorum的讀寫最小票數可以用來做為系統在讀、寫效能方面的一個可調節引數。寫票數Vw越大,則讀票數Vr越小,這時候系統寫的開銷就大。反之則寫的開銷就小。