
python 學習第二十五天(事件驅動和io多路複用)
事件驅動模型
原文連結:http://www.cnblogs.com/yuanchenqi/articles/5722574.html上節的問題:
協程:遇到IO操作就切換。
但什麼時候切回去呢?怎麼確定IO操作完了?


很多程式設計師可能會考慮使用“執行緒池”或“連線池”。“執行緒池”旨在減少建立和銷燬執行緒的頻率,其維持一定合理數量的執行緒,並讓空閒的執行緒重新承擔新的執行任務。“連線池”維持連線的快取池,儘量重用已有的連線、減少建立和關閉連線的頻率。 這兩種技術都可以很好的降低系統開銷,都被廣泛應用很多大型系統,如websphere、tomcat和各種資料庫等。但是,“執行緒池”和“連線池”技術也只是在一定程度上緩解了頻繁呼叫IO介面帶來的資源佔用。而且,所謂“池”始終有其上限,當請求大大超過上限時,“池”構成的系統對外界的響應並不比沒有池的時候效果好多少。所以使用“池”必須考慮其面臨的響應規模,並根據響應規模調整“池”的大小。 對應上例中的所面臨的可能同時出現的上千甚至上萬次的客戶端請求,“執行緒池”或“連線池”或許可以緩解部分壓力,但是不能解決所有問題。總之,多執行緒模型可以方便高效的解決小規模的服務請求,但面對大規模的服務請求,多執行緒模型也會遇到瓶頸,可以用非阻塞介面來嘗試解決這個問題
View Code
傳統的程式設計是如下線性模式的:
開始—>程式碼塊A—>程式碼塊B—>程式碼塊C—>程式碼塊D—>……—>結束
每一個程式碼塊裡是完成各種各樣事情的程式碼,但程式設計者知道程式碼塊A,B,C,D…的執行順序,唯一能夠改變這個流程的是資料。輸入不同的資料,根據條件語句判斷,流程或許就改為A—>C—>E…—>結束。每一次程式執行順序或許都不同,但它的控制流程是由輸入資料和你編寫的程式決定的。如果你知道這個程式當前的執行狀態(包括輸入資料和程式本身),那你就知道接下來甚至一直到結束它的執行流程。
對於事件驅動型程式模型,它的流程大致如下:
開始—>初始化—>等待
與上面傳統程式設計模式不同,事件驅動程式在啟動之後,就在那等待,等待什麼呢?等待被事件觸發。傳統程式設計下也有“等待”的時候,比如在程式碼塊D中,你定義了一個input(),需要使用者輸入資料。但這與下面的等待不同,傳統程式設計的“等待”,比如input(),你作為程式編寫者是知道或者強制使用者輸入某個東西的,或許是數字,或許是檔名稱,如果使用者輸入錯誤,你還需要提醒他,並請他重新輸入。事件驅動程式的等待則是完全不知道,也不強制使用者輸入或者幹什麼。只要某一事件發生,那程式就會做出相應的“反應”。這些事件包括:輸入資訊、滑鼠、敲擊鍵盤上某個鍵還有系統內部定時器觸發。
一、事件驅動模型介紹
通常,我們寫伺服器處理模型的程式時,有以下幾種模型:
(1)每收到一個請求,建立一個新的程序,來處理該請求; (2)每收到一個請求,建立一個新的執行緒,來處理該請求; (3)每收到一個請求,放入一個事件列表,讓主程序通過非阻塞I/O方式來處理請求
第三種就是協程、事件驅動的方式,一般普遍認為第(3)種方式是大多數網路伺服器採用的方式
論事件驅動模型
<!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <title>Title</title> </head> <body> <p onclick="fun()">點我呀</p> <script type="text/javascript"> function fun() { alert('約嗎?') } </script> </body> </html>
事件驅動之滑鼠點選事件註冊
在UI程式設計中,常常要對滑鼠點選進行相應,首先如何獲得滑鼠點選呢? 兩種方式:
1建立一個執行緒迴圈檢測是否有滑鼠點選
那麼這個方式有以下幾個缺點:
- CPU資源浪費,可能滑鼠點選的頻率非常小,但是掃描執行緒還是會一直迴圈檢測,這會造成很多的CPU資源浪費;如果掃描滑鼠點選的介面是阻塞的呢?
- 如果是堵塞的,又會出現下面這樣的問題,如果我們不但要掃描滑鼠點選,還要掃描鍵盤是否按下,由於掃描滑鼠時被堵塞了,那麼可能永遠不會去掃描鍵盤;
- 如果一個迴圈需要掃描的裝置非常多,這又會引來響應時間的問題;
所以,該方式是非常不好的。
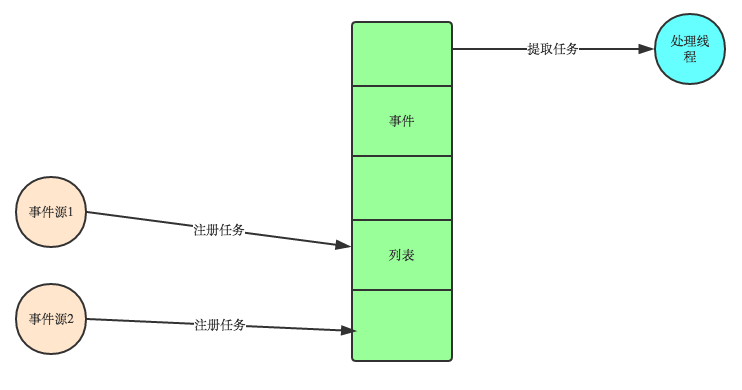
2 就是事件驅動模型
目前大部分的UI程式設計都是事件驅動模型,如很多UI平臺都會提供onClick()事件,這個事件就代表滑鼠按下事件。事件驅動模型大體思路如下:
- 有一個事件(訊息)佇列;
- 滑鼠按下時,往這個佇列中增加一個點選事件(訊息);
- 有個迴圈,不斷從佇列取出事件,根據不同的事件,呼叫不同的函式,如onClick()、onKeyDown()等;
- 事件(訊息)一般都各自儲存各自的處理函式指標,這樣,每個訊息都有獨立的處理函式;
事件驅動程式設計是一種程式設計正規化,這裡程式的執行流由外部事件來決定。它的特點是包含一個事件迴圈,當外部事件發生時使用回撥機制來觸發相應的處理。另外兩種常見的程式設計正規化是(單執行緒)同步以及多執行緒程式設計。
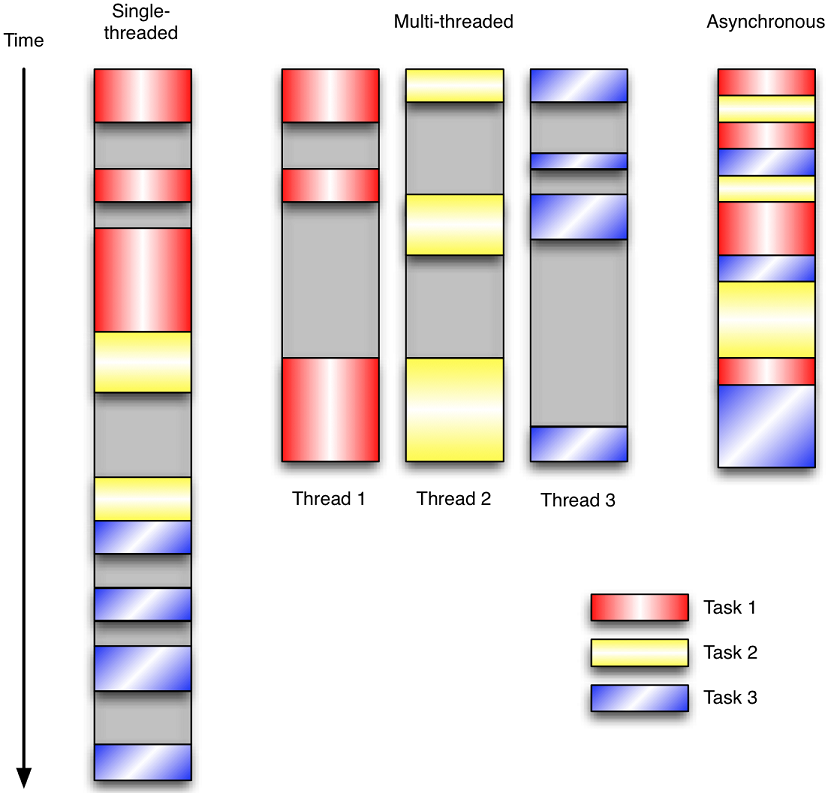
讓我們用例子來比較和對比一下單執行緒、多執行緒以及事件驅動程式設計模型。下圖展示了隨著時間的推移,這三種模式下程式所做的工作。這個程式有3個任務需要完成,每個任務都在等待I/O操作時阻塞自身。阻塞在I/O操作上所花費的時間已經用灰色框標示出來了。
最初的問題:怎麼確定IO操作完了切回去呢?通過回撥函式
1.要理解事件驅動和程式,就需要與非事件驅動的程式進行比較。實際上,現代的程式大多是事件驅動的,比如多執行緒的程式,肯定是事件驅動的。早期則存在許多非事件驅動的程式,這樣的程式,在需要等待某個條件觸發時,會不斷地檢查這個條件,直到條件滿足,這是很浪費cpu時間的。而事件驅動的程式,則有機會釋放cpu從而進入睡眠態(注意是有機會,當然程式也可自行決定不釋放cpu),當事件觸發時被作業系統喚醒,這樣就能更加有效地使用cpu. 2.再說什麼是事件驅動的程式。一個典型的事件驅動的程式,就是一個死迴圈,並以一個執行緒的形式存在,這個死迴圈包括兩個部分,第一個部分是按照一定的條件接收並選擇一個要處理的事件,第二個部分就是事件的處理過程。程式的執行過程就是選擇事件和處理事件,而當沒有任何事件觸發時,程式會因查詢事件佇列失敗而進入睡眠狀態,從而釋放cpu。 3.事件驅動的程式,必定會直接或者間接擁有一個事件佇列,用於儲存未能及時處理的事件。 4.事件驅動的程式的行為,完全受外部輸入的事件控制,所以,事件驅動的系統中,存在大量這種程式,並以事件作為主要的通訊方式。 5.事件驅動的程式,還有一個最大的好處,就是可以按照一定的順序處理佇列中的事件,而這個順序則是由事件的觸發順序決定的,這一特性往往被用於保證某些過程的原子化。 6.目前windows,linux,nucleus,vxworks都是事件驅動的,只有一些微控制器可能是非事件驅動的。
事件驅動註解
注意,事件驅動的監聽事件是由作業系統呼叫的cpu來完成的
IO多路複用
前面是用協程實現的IO阻塞自動切換,那麼協程又是怎麼實現的,在原理是是怎麼實現的。如何去實現事件驅動的情況下IO的自動阻塞的切換,這個學名叫什麼呢? => IO多路複用
比如socketserver,多個客戶端連線,單執行緒下實現併發效果,就叫多路複用。
同步IO和非同步IO,阻塞IO和非阻塞IO分別是什麼,到底有什麼區別?不同的人在不同的上下文下給出的答案是不同的。所以先限定一下本文的上下文。
本文討論的背景是Linux環境下的network IO。
1 IO模型前戲準備
在進行解釋之前,首先要說明幾個概念:
- 使用者空間和核心空間
- 程序切換
- 程序的阻塞
- 檔案描述符
- 快取 I/O
使用者空間與核心空間
現在作業系統都是採用虛擬儲存器,那麼對32位作業系統而言,它的定址空間(虛擬儲存空間)為4G(2的32次方)。
作業系統的核心是核心,獨立於普通的應用程式,可以訪問受保護的記憶體空間,也有訪問底層硬體裝置的所有許可權。
為了保證使用者程序不能直接操作核心(kernel),保證核心的安全,操心繫統將虛擬空間劃分為兩部分,一部分為核心空間,一部分為使用者空間。
針對linux作業系統而言,將最高的1G位元組(從虛擬地址0xC0000000到0xFFFFFFFF),供核心使用,稱為核心空間,而將較低的3G位元組(從虛擬地址0x00000000到0xBFFFFFFF),供各個程序使用,稱為使用者空間。
程序切換
為了控制程序的執行,核心必須有能力掛起正在CPU上執行的程序,並恢復以前掛起的某個程序的執行。這種行為被稱為程序切換,這種切換是由作業系統來完成的。因此可以說,任何程序都是在作業系統核心的支援下執行的,是與核心緊密相關的。
從一個程序的執行轉到另一個程序上執行,這個過程中經過下面這些變化:
儲存處理機上下文,包括程式計數器和其他暫存器。
更新PCB資訊。
把程序的PCB移入相應的佇列,如就緒、在某事件阻塞等佇列。
選擇另一個程序執行,並更新其PCB。
更新記憶體管理的資料結構。
恢復處理機上下文。
注:總而言之就是很耗資源的
程序的阻塞
正在執行的程序,由於期待的某些事件未發生,如請求系統資源失敗、等待某種操作的完成、新資料尚未到達或無新工作做等,則由系統自動執行阻塞原語(Block),使自己由執行狀態變為阻塞狀態。可見,程序的阻塞是程序自身的一種主動行為,也因此只有處於執行態的程序(獲得CPU),才可能將其轉為阻塞狀態。當程序進入阻塞狀態,是不佔用CPU資源的。
檔案描述符fd
檔案描述符(File descriptor)是電腦科學中的一個術語,是一個用於表述指向檔案的引用的抽象化概念。
檔案描述符在形式上是一個非負整數。實際上,它是一個索引值,指向核心為每一個程序所維護的該程序開啟檔案的記錄表。當程式開啟一個現有檔案或者建立一個新檔案時,核心向程序返回一個檔案描述符。在程式設計中,一些涉及底層的程式編寫往往會圍繞著檔案描述符展開。但是檔案描述符這一概念往往只適用於UNIX、Linux這樣的作業系統。
快取 I/O
快取 I/O 又被稱作標準 I/O,大多數檔案系統的預設 I/O 操作都是快取 I/O。在 Linux 的快取 I/O 機制中,作業系統會將 I/O 的資料快取在檔案系統的頁快取( page cache )中,也就是說,資料會先被拷貝到作業系統核心的緩衝區中,然後才會從作業系統核心的緩衝區拷貝到應用程式的地址空間。使用者空間沒法直接訪問核心空間的,核心態到使用者態的資料拷貝
思考:為什麼資料一定要先到核心區,直接到使用者記憶體不是更直接嗎?
快取 I/O 的缺點:
資料在傳輸過程中需要在應用程式地址空間和核心進行多次資料拷貝操作,這些資料拷貝操作所帶來的 CPU 以及記憶體開銷是非常大的。
同步(synchronous) IO和非同步(asynchronous) IO,阻塞(blocking) IO和非阻塞(non-blocking)IO分別是什麼,到底有什麼區別?這個問題其實不同的人給出的答案都可能不同,比如wiki,就認為asynchronous IO和non-blocking IO是一個東西。這其實是因為不同的人的知識背景不同,並且在討論這個問題的時候上下文(context)也不相同。所以,為了更好的回答這個問題,我先限定一下本文的上下文。
本文討論的背景是Linux環境下的network IO。
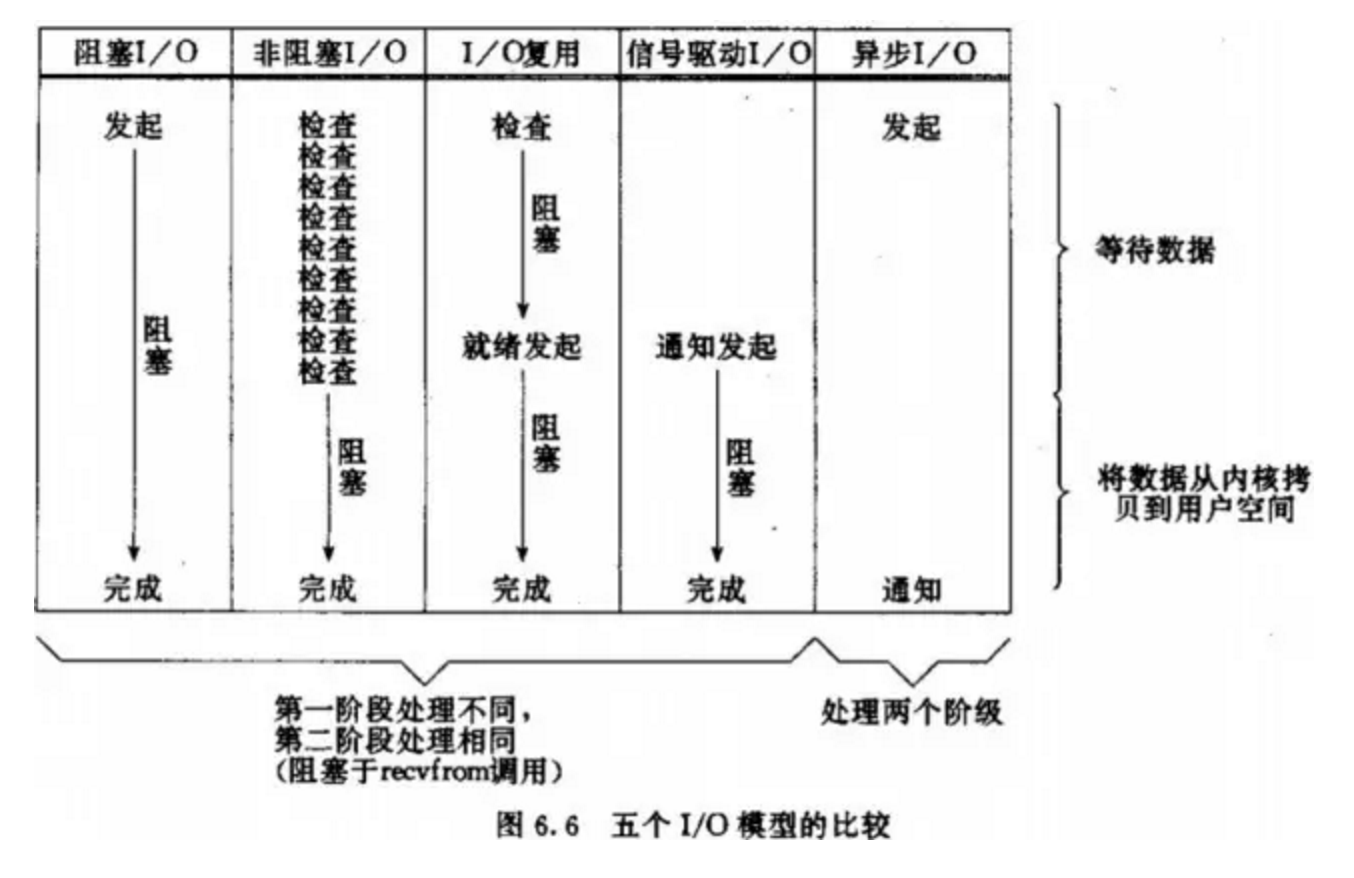
Stevens在文章中一共比較了五種IO Model:
-
-
- blocking IO
- nonblocking IO
- IO multiplexing
- signal driven IO
- asynchronous IO
-
由於signal driven IO在實際中並不常用,所以我這隻提及剩下的四種IO Model。
再說一下IO發生時涉及的物件和步驟。
對於一個network IO (這裡我們以read舉例),它會涉及到兩個系統物件,一個是呼叫這個IO的process (or thread),另一個就是系統核心(kernel)。當一個read操作發生時,它會經歷兩個階段:
1 等待資料準備 (Waiting for the data to be ready)
2 將資料從核心拷貝到程序中 (Copying the data from the kernel to the process)
記住這兩點很重要,因為這些IO Model的區別就是在兩個階段上各有不同的情況。
2 blocking IO (阻塞IO)
在linux中,預設情況下所有的socket都是blocking,一個典型的讀操作流程大概是這樣:
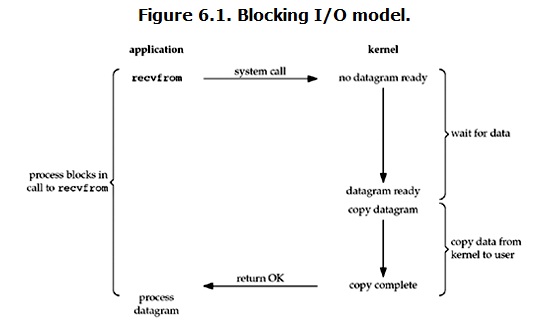
當用戶程序呼叫了recvfrom這個系統呼叫,kernel就開始了IO的第一個階段:準備資料。對於network io來說,很多時候資料在一開始還沒有到達(比如,還沒有收到一個完整的UDP包),這個時候kernel就要等待足夠的資料到來。而在使用者程序這邊,整個程序會被阻塞。當kernel一直等到資料準備好了,它就會將資料從kernel中拷貝到使用者記憶體,然後kernel返回結果,使用者程序才解除block的狀態,重新執行起來。
所以,blocking IO的特點就是在IO執行的兩個階段都被block了。
3 non-blocking IO(非阻塞IO)
linux下,可以通過設定socket使其變為non-blocking。當對一個non-blocking socket執行讀操作時,流程是這個樣子:
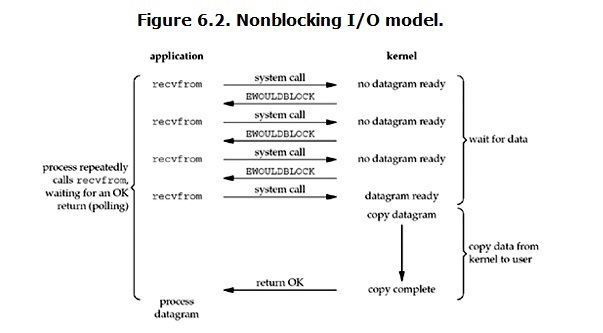
從圖中可以看出,當用戶程序發出read操作時,如果kernel中的資料還沒有準備好,那麼它並不會block使用者程序,而是立刻返回一個error。從使用者程序角度講 ,它發起一個read操作後,並不需要等待,而是馬上就得到了一個結果。使用者程序判斷結果是一個error時,它就知道資料還沒有準備好,於是它可以再次傳送read操作。一旦kernel中的資料準備好了,並且又再次收到了使用者程序的system call,那麼它馬上就將資料拷貝到了使用者記憶體,然後返回。
所以,使用者程序其實是需要不斷的主動詢問kernel資料好了沒有。
注意:
在網路IO時候,非阻塞IO也會進行recvform系統呼叫,檢查資料是否準備好,與阻塞IO不一樣,”非阻塞將大的整片時間的阻塞分成N多的小的阻塞, 所以程序不斷地有機會 ‘被’ CPU光顧”。即每次recvform系統呼叫之間,cpu的許可權還在程序手中,這段時間是可以做其他事情的,
也就是說非阻塞的recvform系統呼叫呼叫之後,程序並沒有被阻塞,核心馬上返回給程序,如果資料還沒準備好,此時會返回一個error。程序在返回之後,可以乾點別的事情,然後再發起recvform系統呼叫。重複上面的過程,迴圈往復的進行recvform系統呼叫。這個過程通常被稱之為輪詢。輪詢檢查核心資料,直到資料準備好,再拷貝資料到程序,進行資料處理。需要注意,拷貝資料整個過程,程序仍然是屬於阻塞的狀態。
4 IO multiplexing(IO多路複用)
IO multiplexing這個詞可能有點陌生,但是如果我說select,epoll,大概就都能明白了。有些地方也稱這種IO方式為event driven IO。我們都知道,select/epoll的好處就在於單個process就可以同時處理多個網路連線的IO。它的基本原理就是select/epoll這個function會不斷的輪詢所負責的所有socket,當某個socket有資料到達了,就通知使用者程序。它的流程如圖:
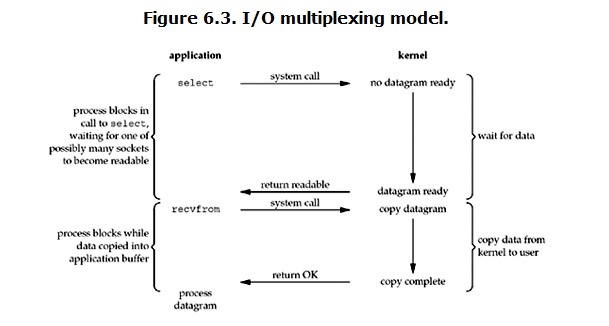
當用戶程序呼叫了select,那麼整個程序會被block,而同時,kernel會“監視”所有select負責的socket,當任何一個socket中的資料準備好了,select就會返回。這個時候使用者程序再呼叫read操作,將資料從kernel拷貝到使用者程序。
這個圖和blocking IO的圖其實並沒有太大的不同,事實上,還更差一些。因為這裡需要使用兩個system call (select 和 recvfrom),而blocking IO只調用了一個system call (recvfrom)。但是,用select的優勢在於它可以同時處理多個connection。(多說一句。所以,如果處理的連線數不是很高的話,使用select/epoll的web server不一定比使用multi-threading + blocking IO的web server效能更好,可能延遲還更大。select/epoll的優勢並不是對於單個連線能處理得更快,而是在於能處理更多的連線。)
在IO multiplexing Model中,實際中,對於每一個socket,一般都設定成為non-blocking,但是,如上圖所示,整個使用者的process其實是一直被block的。只不過process是被select這個函式block,而不是被socket IO給block。
注意1:select函式返回結果中如果有檔案可讀了,那麼程序就可以通過呼叫accept()或recv()來讓kernel將位於核心中準備到的資料copy到使用者區。
注意2: select的優勢在於可以處理多個連線,不適用於單個連線
5 Asynchronous I/O(非同步IO)
linux下的asynchronous IO其實用得很少。先看一下它的流程:
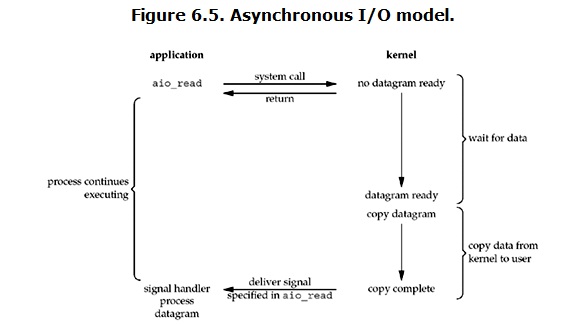
使用者程序發起read操作之後,立刻就可以開始去做其它的事。而另一方面,從kernel的角度,當它受到一個asynchronous read之後,首先它會立刻返回,所以不會對使用者程序產生任何block。然後,kernel會等待資料準備完成,然後將資料拷貝到使用者記憶體,當這一切都完成之後,kernel會給使用者程序傳送一個signal,告訴它read操作完成了。
到目前為止,已經將四個IO Model都介紹完了。現在回過頭來回答最初的那幾個問題:blocking和non-blocking的區別在哪,synchronous IO和asynchronous IO的區別在哪。
先回答最簡單的這個:blocking vs non-blocking。前面的介紹中其實已經很明確的說明了這兩者的區別。呼叫blocking IO會一直block住對應的程序直到操作完成,而non-blocking IO在kernel還準備資料的情況下會立刻返回。
在說明synchronous IO和asynchronous IO的區別之前,需要先給出兩者的定義。Stevens給出的定義(其實是POSIX的定義)是這樣子的:
A synchronous I/O operation causes the requesting process to be blocked until that I/O operationcompletes;
An asynchronous I/O operation does not cause the requesting process to be blocked;
兩者的區別就在於synchronous IO做”IO operation”的時候會將process阻塞。按照這個定義,之前所述的blocking IO,non-blocking IO,IO multiplexing都屬於synchronous IO。有人可能會說,non-blocking IO並沒有被block啊。這裡有個非常“狡猾”的地方,定義中所指的”IO operation”是指真實的IO操作,就是例子中的recvfrom這個system call。non-blocking IO在執行recvfrom這個system call的時候,如果kernel的資料沒有準備好,這時候不會block程序。但是,當kernel中資料準備好的時候,recvfrom會將資料從kernel拷貝到使用者記憶體中,這個時候程序是被block了,在這段時間內,程序是被block的。而asynchronous IO則不一樣,當程序發起IO 操作之後,就直接返回再也不理睬了,直到kernel傳送一個訊號,告訴程序說IO完成。在這整個過程中,程序完全沒有被block。
注意:由於咱們接下來要講的select,poll,epoll都屬於IO多路複用,而IO多路複用又屬於同步的範疇,故,epoll只是一個偽非同步而已。
各個IO Model的比較如圖所示:

經過上面的介紹,會發現non-blocking IO和asynchronous IO的區別還是很明顯的。在non-blocking IO中,雖然程序大部分時間都不會被block,但是它仍然要求程序去主動的check,並且當資料準備完成以後,也需要程序主動的再次呼叫recvfrom來將資料拷貝到使用者記憶體。而asynchronous IO則完全不同。它就像是使用者程序將整個IO操作交給了他人(kernel)完成,然後他人做完後發訊號通知。在此期間,使用者程序不需要去檢查IO操作的狀態,也不需要主動的去拷貝資料。
五種IO模型比較:
6 select poll epoll IO多路複用介紹
首先列一下,sellect、poll、epoll三者的區別
- select
select最早於1983年出現在4.2BSD中,它通過一個select()系統呼叫來監視多個檔案描述符的陣列,當select()返回後,該陣列中就緒的檔案描述符便會被核心修改標誌位,使得程序可以獲得這些檔案描述符從而進行後續的讀寫操作。
select目前幾乎在所有的平臺上支援
select的一個缺點在於單個程序能夠監視的檔案描述符的數量存在最大限制,在Linux上一般為1024,不過可以通過修改巨集定義甚至重新編譯核心的方式提升這一限制。
另外,select()所維護的儲存大量檔案描述符的資料結構,隨著檔案描述符數量的增大,其複製的開銷也線性增長。同時,由於網路響應時間的延遲使得大量TCP連線處於非活躍狀態,但呼叫select()會對所有socket進行一次線性掃描,所以這也浪費了一定的開銷。
-
poll
它和select在本質上沒有多大差別,但是poll沒有最大檔案描述符數量的限制。
一般也不用它,相當於過渡階段 -
epoll
直到Linux2.6才出現了由核心直接支援的實現方法,那就是epoll。被公認為Linux2.6下效能最好的多路I/O就緒通知方法。windows不支援
沒有最大檔案描述符數量的限制。
比如100個連線,有兩個活躍了,epoll會告訴使用者這兩個兩個活躍了,直接取就ok了,而select是迴圈一遍。
(瞭解)epoll可以同時支援水平觸發和邊緣觸發(Edge Triggered,只告訴程序哪些檔案描述符剛剛變為就緒狀態,它只說一遍,如果我們沒有采取行動,那麼它將不會再次告知,這種方式稱為邊緣觸發),理論上邊緣觸發的效能要更高一些,但是程式碼實現相當複雜。
另一個本質的改進在於epoll採用基於事件的就緒通知方式。在select/poll中,程序只有在呼叫一定的方法後,核心才對所有監視的檔案描述符進行掃描,而epoll事先通過epoll_ctl()來註冊一個檔案描述符,一旦基於某個檔案描述符就緒時,核心會採用類似callback的回撥機制,迅速啟用這個檔案描述符,當程序呼叫epoll_wait()時便得到通知。
所以市面上上見到的所謂的非同步IO,比如nginx、Tornado、等,我們叫它非同步IO,實際上是IO多路複用。
select與epoll
# 首先我們來定義流的概念,一個流可以是檔案,socket,pipe等等可以進行I/O操作的核心物件。# 不管是檔案,還是套接字,還是管道,我們都可以把他們看作流。 # 之後我們來討論I/O的操作,通過read,我們可以從流中讀入資料;通過write,我們可以往流寫入資料。現在假 # 定一個情形,我們需要從流中讀資料,但是流中還沒有資料,(典型的例子為,客戶端要從socket讀如資料,但是 # 伺服器還沒有把資料傳回來),這時候該怎麼辦? # 阻塞。阻塞是個什麼概念呢?比如某個時候你在等快遞,但是你不知道快遞什麼時候過來,而且你沒有別的事可以幹 # (或者說接下來的事要等快遞來了才能做);那麼你可以去睡覺了,因為你知道快遞把貨送來時一定會給你打個電話 # (假定一定能叫醒你)。 # 非阻塞忙輪詢。接著上面等快遞的例子,如果用忙輪詢的方法,那麼你需要知道快遞員的手機號,然後每分鐘給他掛 # 個電話:“你到了沒?” # 很明顯一般人不會用第二種做法,不僅顯很無腦,浪費話費不說,還佔用了快遞員大量的時間。 # 大部分程式也不會用第二種做法,因為第一種方法經濟而簡單,經濟是指消耗很少的CPU時間,如果執行緒睡眠了, # 就掉出了系統的排程佇列,暫時不會去瓜分CPU寶貴的時間片了。 # # 為了瞭解阻塞是如何進行的,我們來討論緩衝區,以及核心緩衝區,最終把I/O事件解釋清楚。緩衝區的引入是為 # 了減少頻繁I/O操作而引起頻繁的系統呼叫(你知道它很慢的),當你操作一個流時,更多的是以緩衝區為單位進 # 行操作,這是相對於使用者空間而言。對於核心來說,也需要緩衝區。 # 假設有一個管道,程序A為管道的寫入方,B為管道的讀出方。 # 假設一開始核心緩衝區是空的,B作為讀出方,被阻塞著。然後首先A往管道寫入,這時候核心緩衝區由空的狀態變 # 到非空狀態,核心就會產生一個事件告訴B該醒來了,這個事件姑且稱之為“緩衝區非空”。 # 但是“緩衝區非空”事件通知B後,B卻還沒有讀出資料;且核心許諾了不能把寫入管道中的資料丟掉這個時候,A寫 # 入的資料會滯留在核心緩衝區中,如果核心也緩衝區滿了,B仍未開始讀資料,最終核心緩衝區會被填滿,這個時候 # 會產生一個I/O事件,告訴程序A,你該等等(阻塞)了,我們把這個事件定義為“緩衝區滿”。 # 假設後來B終於開始讀資料了,於是核心的緩衝區空了出來,這時候核心會告訴A,核心緩衝區有空位了,你可以從 # 長眠中醒來了,繼續寫資料了,我們把這個事件叫做“緩衝區非滿” # 也許事件Y1已經通知了A,但是A也沒有資料寫入了,而B繼續讀出資料,知道核心緩衝區空了。這個時候核心就告 # 訴B,你需要阻塞了!,我們把這個時間定為“緩衝區空”。 # 這四個情形涵蓋了四個I/O事件,緩衝區滿,緩衝區空,緩衝區非空,緩衝區非滿(注都是說的核心緩衝區,且這四 # 個術語都是我生造的,僅為解釋其原理而造)。這四個I/O事件是進行阻塞同步的根本。(如果不能理解“同步”是 # 什麼概念,請學習作業系統的鎖,訊號量,條件變數等任務同步方面的相關知識)。 # # 然後我們來說說阻塞I/O的缺點。但是阻塞I/O模式下,一個執行緒只能處理一個流的I/O事件。如果想要同時處理多 # 個流,要麼多程序(fork),要麼多執行緒(pthread_create),很不幸這兩種方法效率都不高。 # 於是再來考慮非阻塞忙輪詢的I/O方式,我們發現我們可以同時處理多個流了(把一個流從阻塞模式切換到非阻塞 # 模式再此不予討論): # while true { # for i in stream[]; { # if i has data # read until unavailable # } # } # 我們只要不停的把所有流從頭到尾問一遍,又從頭開始。這樣就可以處理多個流了,但這樣的做法顯然不好,因為 # 如果所有的流都沒有資料,那麼只會白白浪費CPU。這裡要補充一點,阻塞模式下,核心對於I/O事件的處理是阻 # 塞或者喚醒,而非阻塞模式下則把I/O事件交給其他物件(後文介紹的select以及epoll)處理甚至直接忽略。 # # 為了避免CPU空轉,可以引進了一個代理(一開始有一位叫做select的代理,後來又有一位叫做poll的代理,不 # 過兩者的本質是一樣的)。這個代理比較厲害,可以同時觀察許多流的I/O事件,在空閒的時候,會把當前執行緒阻 # 塞掉,當有一個或多個流有I/O事件時,就從阻塞態中醒來,於是我們的程式就會輪詢一遍所有的流(於是我們可 # 以把“忙”字去掉了)。程式碼長這樣: # while true { # select(streams[]) # for i in streams[] { # if i has data # read until unavailable # } # } # 於是,如果沒有I/O事件產生,我們的程式就會阻塞在select處。但是依然有個問題,我們從select那裡僅僅知 # 道了,有I/O事件發生了,但卻並不知道是那幾個流(可能有一個,多個,甚至全部),我們只能無差別輪詢所有流, # 找出能讀出資料,或者寫入資料的流,對他們進行操作。 # 但是使用select,我們有O(n)的無差別輪詢複雜度,同時處理的流越多,每一次無差別輪詢時間就越長。再次 # 說了這麼多,終於能好好解釋epoll了 # epoll可以理解為event poll,不同於忙輪詢和無差別輪詢,epoll之會把哪個流發生了怎樣的I/O事件通知我 # 們。此時我們對這些流的操作都是有意義的。 # 在討論epoll的實現細節之前,先把epoll的相關操作列出: # epoll_create 建立一個epoll物件,一般epollfd = epoll_create() # epoll_ctl (epoll_add/epoll_del的合體),往epoll物件中增加/刪除某一個流的某一個事件 # 比如 # epoll_ctl(epollfd, EPOLL_CTL_ADD, socket, EPOLLIN);//有緩衝區內有資料時epoll_wait返回 # epoll_ctl(epollfd, EPOLL_CTL_DEL, socket, EPOLLOUT);//緩衝區可寫入時epoll_wait返回 # epoll_wait(epollfd,…)等待直到註冊的事件發生 # (注:當對一個非阻塞流的讀寫發生緩衝區滿或緩衝區空,write/read會返回-1,並設定errno=EAGAIN。 # 而epoll只關心緩衝區非滿和緩衝區非空事件)。 # 一個epoll模式的程式碼大概的樣子是: # while true { # active_stream[] = epoll_wait(epollfd) # for i in active_stream[] { # read or write till unavailable # } # } # 舉個例子: # select: # 班裡三十個同學在考試,誰先做完想交卷都要通過按鈕來活動,他按按鈕作為老師的我桌子上的燈就會變紅. # 一旦燈變紅,我(select)我就可以知道有人交卷了,但是我並不知道誰交的,所以,我必須跟個傻子似的輪詢 # 地去問:嘿,是你要交卷嗎?然後我就可以以這種效率極低地方式找到要交卷的學生,然後把它的卷子收上來. # # # epoll: # 這次再有人按按鈕,我這不光燈會亮,上面還會顯示要交卷學生的名字.這樣我就可以直接去對應學生那收卷就 # 好了.當然,同時可以有多人交卷.
View Code
IO多路複用的觸發方式
# 在linux的IO多路複用中有水平觸發,邊緣觸發兩種模式,這兩種模式的區別如下: ## 水平觸發:如果檔案描述符已經就緒可以非阻塞的執行IO操作了,此時會觸發通知.允許在任意時刻重複檢測IO的狀態, # 沒有必要每次描述符就緒後儘可能多的執行IO.select,poll就屬於水平觸發. # # 邊緣觸發:如果檔案描述符自上次狀態改變後有新的IO活動到來,此時會觸發通知.在收到一個IO事件通知後要儘可能 # 多的執行IO操作,因為如果在一次通知中沒有執行完IO那麼就需要等到下一次新的IO活動到來才能獲取到就緒的描述 # 符.訊號驅動式IO就屬於邊緣觸發. # # epoll既可以採用水平觸發,也可以採用邊緣觸發. # # 大家可能還不能完全瞭解這兩種模式的區別,我們可以舉例說明:一個管道收到了1kb的資料,epoll會立即返回,此時 # 讀了512位元組資料,然後再次呼叫epoll.這時如果是水平觸發的,epoll會立即返回,因為有資料準備好了.如果是邊 # 緣觸發的不會立即返回,因為此時雖然有資料可讀但是已經觸發了一次通知,在這次通知到現在還沒有新的資料到來, # 直到有新的資料到來epoll才會返回,此時老的資料和新的資料都可以讀取到(當然是需要這次你儘可能的多讀取). # 下面我們還從電子的角度來解釋一下: # # 水平觸發:也就是隻有高電平(1)或低電平(0)時才觸發通知,只要在這兩種狀態就能得到通知.上面提到的只要 # 有資料可讀(描述符就緒)那麼水平觸發的epoll就立即返回. # # 邊緣觸發:只有電平發生變化(高電平到低電平,或者低電平到高電平)的時候才觸發通知.上面提到即使有資料 # 可讀,但是沒有新的IO活動到來,epoll也不會立即返回.
水平觸發和邊緣觸發
簡單例項
例項1(non-blocking IO):
import time import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) sk.setsockopt sk.bind(('127.0.0.1',6667)) sk.listen(5) sk.setblocking(False) while True: try: print ('waiting client connection .......') connection,address = sk.accept() # 程序主動輪詢 print("+++",address) client_messge = connection.recv(1024) print(str(client_messge,'utf8')) connection.close() except Exception as e: print (e) time.sleep(4) #############################client import time import socket sk = socket.socket(socket.AF_INET,socket.SOCK_STREAM) while True: sk.connect(('127.0.0.1',6667)) print("hello") sk.sendall(bytes("hello","utf8")) time.sleep(2) break
View Code
優點:能夠在等待任務完成的時間裡幹其他活了(包括提交其他任務,也就是 “後臺” 可以有多個任務在同時執行)。
缺點:任務完成的響應延遲增大了,因為每過一段時間才去輪詢一次read操作,而任務可能在兩次輪詢之間的任意時間完成。這會導致整體資料吞吐量的降低。
例項2(IO multiplexing):
在非阻塞例項中,輪詢的主語是程序,而“後臺” 可能有多個任務在同時進行,人們就想到了迴圈查詢多個任務的完成狀態,只要有任何一個任務完成,就去處理它。不過,這個監聽的重任通過呼叫select等函式交給了核心去做。IO多路複用有兩個特別的系統呼叫select、poll、epoll函式。select呼叫是核心級別的,select輪詢相對非阻塞的輪詢的區別在於—前者可以等待多個socket,能實現同時對多個IO埠進行監聽,當其中任何一個socket的資料準好了,就能返回進行可讀,然後程序再進行recvfrom系統呼叫,將資料由核心拷貝到使用者程序,當然這個過程是阻塞的。
例項2:
import socket import select sk=socket.socket() sk.bind(("127.0.0.1",9904)) sk.listen(5) while True: r,w,e=select.select([sk,],[],[],5) for i in r: # conn,add=i.accept() #print(conn) print("hello") print('>>>>>>') #*************************client.py import socket sk=socket.socket() sk.connect(("127.0.0.1",9904)) while 1: inp=input(">>").strip() sk.send(inp.encode("utf8")) data=sk.recv(1024) print(data.decode("utf8"))
View Code
請思考:為什麼不呼叫accept,會反覆print?
select屬於水平觸發
bingo
例項3(server端併發聊天):
#***********************server.py import socket import select sk=socket.socket() sk.bind(("127.0.0.1",8801)) sk.listen(5) inputs=[sk,] while True: r,w,e=select.select(inputs,[],[],5) print(len(r)) for obj in r: if obj==sk: conn,add=obj.accept() print(conn) inputs.append(conn) else: data_byte=obj.recv(1024) print(str(data_byte,'utf8')) inp=input('回答%s號客戶>>>'%inputs.index(obj)) obj.sendall(bytes(inp,'utf8')) print('>>',r) #***********************client.py import socket sk=socket.socket() sk.connect(('127.0.0.1',8801)) while True: inp=input(">>>>") sk.sendall(bytes(inp,"utf8")) data=sk.recv(1024) print(str(data,'utf8'))
View Code
檔案描述符其實就是咱們平時說的控制代碼,只不過檔案描述符是linux中的概念。注意,我們的accept或recv呼叫時即向系統發出recvfrom請求
(1) 如果核心緩衝區沒有資料--->等待--->資料到了核心緩衝區,轉到使用者程序緩衝區;
(2) 如果先用select監聽到某個檔案描述符對應的核心緩衝區有了資料,當我們再呼叫accept或recv時,直接將資料轉到使用者緩衝區。

思考1:開啟5個client,分別按54321的順序傳送訊息,那麼server端是按什麼順序回訊息的呢?
思考2: 如何在某一個client端退出後,不影響server端和其它客戶端正常交流
linux:
if not data_byte: inputs.remove(obj) continue
win

try: data_byte=obj.recv(1024) print(str(data_byte,'utf8')) inp=input('回答%s號客戶>>>'%inputs.index(obj)) obj.sendall(bytes(inp,'utf8')) except Exception: inputs.remove(obj)
延伸
例項4:
#_*_coding:utf-8_*_ __author__ = 'Alex Li' import select import socket import sys import queue # Create a TCP/IP socket server = socket.socket(socket.AF_INET, socket.SOCK_STREAM) server.setblocking(False) # Bind the socket to the port server_address = ('localhost', 10000) print(sys.stderr, 'starting up on %s port %s' % server_address) server.bind(server_address) # Listen for incoming connections server.listen(5) # Sockets from which we expect to read inputs = [ server ] # Sockets to which we expect to write outputs = [ ] message_queues = {} while inputs: # Wait for at least one of the sockets to be ready for processing print( '\nwaiting for the next event') readable, writable, exceptional = select.select(inputs, outputs, inputs) # Handle inputs for s in readable: if s is server: # A "readable" server socket is ready to accept a connection connection, client_address = s.accept() print('new connection from', client_address) connection.setblocking(False) inputs.append(connection) # Give the connection a queue for data we want to send message_queues[connection] = queue.Queue() else: data = s.recv(1024) if data: # A readable client socket has data print(sys.stderr, 'received "%s" from %s' % (data, s.getpeername()) ) message_queues[s].put(data) # Add output channel for response if s not in outputs: outputs.append(s) else: # Interpret empty result as closed connection print('closing', client_address, 'after reading no data') # Stop listening for input on the connection if s in outputs: outputs.remove(s) #既然客戶端都斷開了,我就不用再給它返回資料了,所以這時候如果這個客戶端的連線物件還在outputs列表中,就把它刪掉 inputs.remove(s) #inputs中也刪除掉 s.close() #把這個連線關閉掉 # Remove message queue del message_queues[s] # Handle outputs for s in writable: try: next_msg = message_queues[s].get_nowait() except queue.Empty: # No messages waiting so stop checking for writability. print('output queue for', s.getpeername(), 'is empty') outputs.remove(s) else: print( 'sending "%s" to %s' % (next_msg, s.getpeername())) s.send(next_msg) # Handle "exceptional conditions" for s in exceptional: print('handling exceptional condition for', s.getpeername() ) # Stop listening for input on the connection inputs.remove(s) if s in outputs: outputs.remove(s) s.close() # Remove message queue del message_queues[s]
View Code
例項5:
# select 模擬一個socket server,注意socket必須在非阻塞情況下才能實現IO多路複用。# 接下來通過例子瞭解select 是如何通過單程序實現同時處理多個非阻塞的socket連線的。 # server端 import select import socket import queue server = socket.socket() server.bind(( ’ localhost ’,9000 )) server.listen(1000 ) server.setblocking(False) # 設定成非阻塞模式,accept和recv都非阻塞 # 這裡如果直接 server.accept() ,如果沒有連線會報錯,所以有資料才調他們 # BlockIOError:[WinError 10035] 無法立即完成一個非阻塞性套接字操作。 msg_dic = {} inputs = [server,] # 交給核心、select檢測的列表。 # 必須有一個值,讓select檢測,否則報錯提供無效引數。 # 沒有其他連線之前,自己就是個socket,自己就是個連線,檢測自己。活動了說明有連結 outputs = [] # 你往裡面放什麼,下一次就出來了 while True: readable, writeable, exceptional = select.select(inputs, outputs, inputs) # 定義檢測 # 新來連線 檢測列表 異常(斷開) # 異常的也是inputs是: 檢測那些連線的存在異常 print (readable,writeable,exceptional) for r in readable: if r is server: # 有資料,代表來了一個新連線 conn, addr = server.accept() print( ” 來了個新連線 ” ,addr) inputs.append(conn) # 把連線加到檢測列表裡,如果這個連線活動了,就說明資料來了 # inputs = [server.conn] # 【conn】只返回活動的連線,但怎麼確定是誰活動了 # 如果server活動,則來了新連線,conn活動則來資料 msg_dic[conn] = queue.Queue() # 初始化一個佇列,後面存要返回給這個客戶端的資料 else : try : data = r.recv(1024) # 注意這裡是r,而不是conn,多個連線的情況 print( ” 收到資料 ” ,data) # r.send(data) # 不能直接發,如果客戶端不收,資料就沒了 msg_dic[r].put(data) # 往裡面放資料 outputs.append(r) # 放入返回的連線佇列裡 except ConnectionResetError as e: print( ” 客戶端斷開了 ” ,r) if r in outputs: outputs.remove(r) # 清理已斷開的連線 inputs.remove(r) # 清理已斷開的連線 del msg_dic[r] # #清理已斷開的連線 for w in writeable: # 要返回給客戶端的連線列表 data_to_client = msg_dic[w].get() # 在字典裡取資料 w.send(data_to_client) # 返回給客戶端 outputs.remove(w) # 刪除這個資料,確保下次迴圈的時候不返回這個已經處理完的連線了。 for e in exceptional: # 如果連線斷開,刪除連線相關資料 if e in outputs: outputs.remove(e) inputs.remove(e) del msg_dic[e] # *************************client import socket client = socket.socket() client.connec