
爬取百度翻譯介面
阿新 • • 發佈:2018-11-02
https://fanyi.baidu.com/v2transapi 會報錯
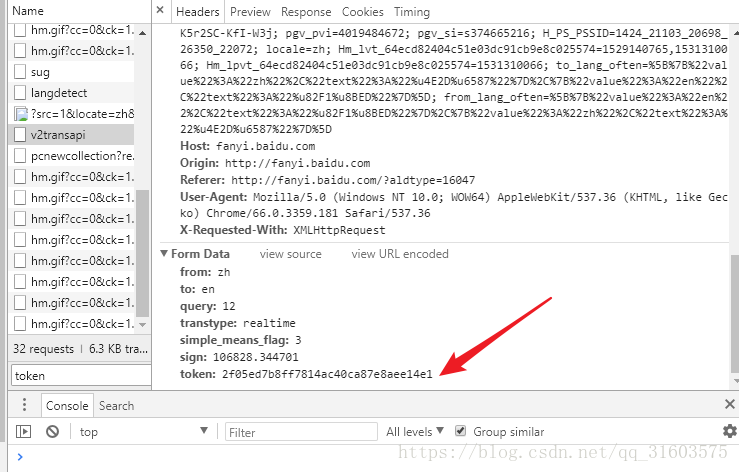
2 嘗試切換到移動端看看結果
https://fanyi.baidu.com/basetrans 這才是正確的介面
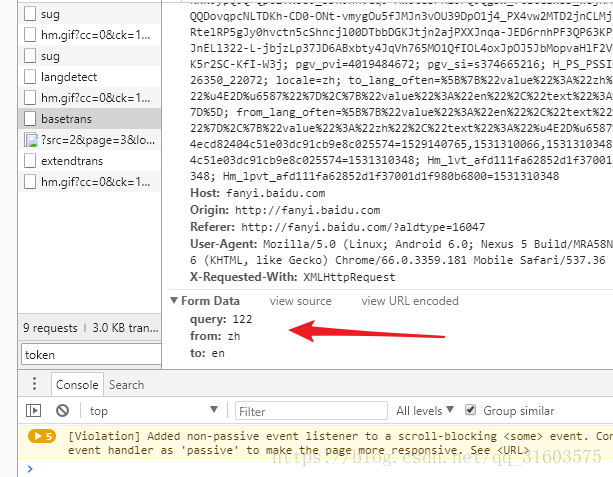
3 程式碼展示
# -*- coding: utf-8 -*-
import requests
import pprint
import re
# 檢測語言url
testing_url = 'https://fanyi.baidu.com/langdetect'
# 翻譯url
translate_url = 'https://fanyi.baidu.com/basetrans'
a = 'https://fanyi.baidu.com/v2transapi'
headers = {
'User-Agent': "Mozilla/5.0 (iPhone; CPU iPhone OS 10_3_1 like Mac OS X) AppleWebKit/603.1.30 (KHTML, like Gecko) Version/10.0 Mobile/14E304 Safari/602.1"
}
# 檢測輸入內容語種
def getLanguageType(content):
data = {'query': content}
resp = requests.post(url=testing_url, data=data, headers=headers).text # 這是post 請求 data引數就是 出入的內容
# resp = {error: 0, msg: "success", lan: "en"} 判斷 len對應的是en 還是zh
return eval(resp)
# 翻譯
def translate(fromlanguage, tolanguage, content):
data = {
'from': fromlanguage,
'to': tolanguage,
'query': content,
}
resp = requests.post(url=translate_url, data=data, headers=headers).text
return eval(resp)
# 翻譯成英文
def to_en(content):
try:
# 檢測輸入內容語種
language_type = getLanguageType(content)['lan']
if language_type == 'en':
return content
else:
# 翻譯成英文
data = translate(language_type, 'en', content)
trans = ' '.join(re.findall(r'[\w,!.?]+', data['trans'][0]['dst']))
trans = re.sub(',', ',', trans)
return trans
except Exception:
return content
# 翻譯成漢語
def to_zh(content):
try:
# 檢測輸入內容語種
language_type = getLanguageType(content)['lan']
if language_type == 'zh':
return content
else:
# 翻譯成英文
data = translate(language_type, 'zh', content)
trans = data['trans'][0]['dst']
trans = re.sub(',', ',', trans)
return trans
except Exception:
return content