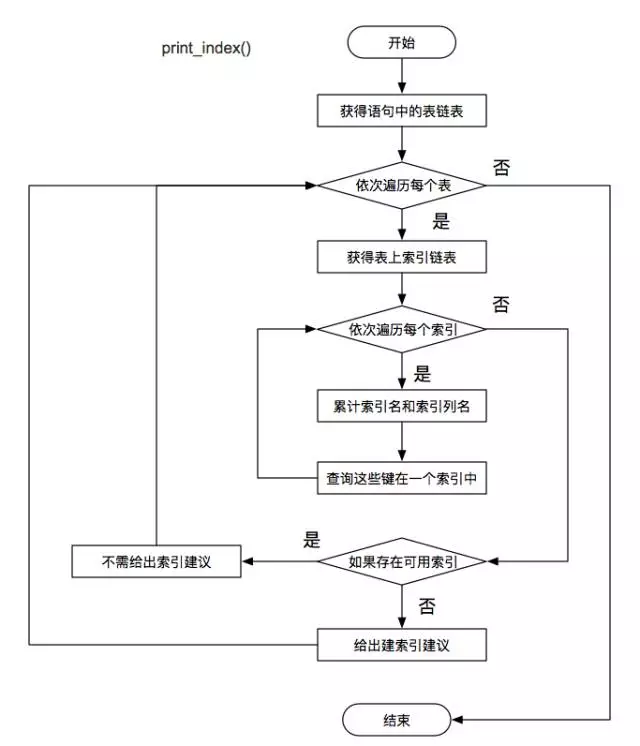
美團開源 SQL 優化工具 SQLAdvisor
https://www.oschina.net/news/82725/sqladvisor-opensource
https://github.com/Meituan-Dianping/SQLAdvisor
SQLAdvisor 是由美團點評公司北京 DBA 團隊開發維護的 SQL 優化工具:輸入SQL,輸出索引優化建議,現已開源。 它基於 MySQL 原生詞法解析,再結合 SQL 中的 where 條件以及欄位選擇度、聚合條件、多表 Join 關係等最終輸出最優的索引優化建議。開發團隊稱目前 SQLAdvisor 在美團內部大量使用,較為成熟、穩定,且開源版本和內部使用版本保持完全一致,希望與業內有類似需求的團隊,一起打造一款優秀的 SQL 優化產品。
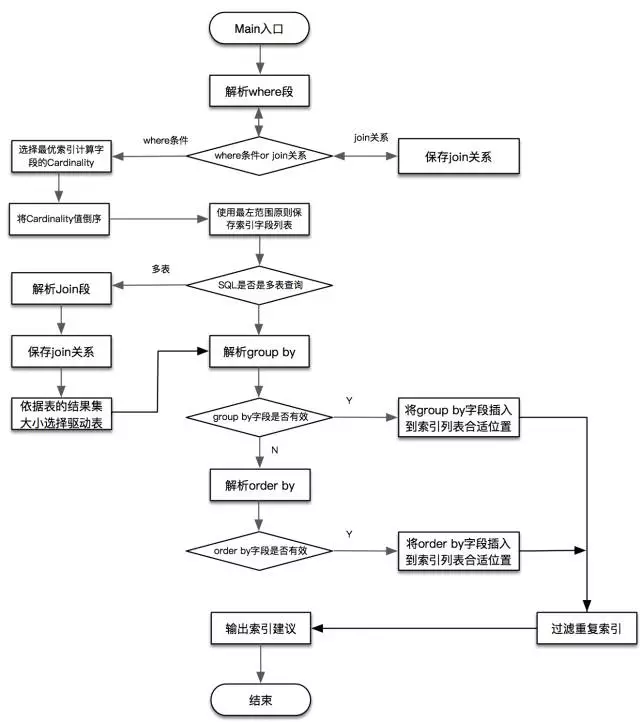
SQLAdvisor 架構流程圖:
SQLAdvisor 使用舉例
sql: SELECT id FROM crm_loan WHERE id_card = '1234567' cmd: ./sqladvisor -h xx -P xx -u xx -pxx -d xx -q "SELECT id FROM crm_loan WHERE id_card = '1234567'" SQLAdvisor輸出: alter table crm_loan add index idx_id_card(id_card)
SQLAdvisor 的優點
-
基於 MySQL 原生詞法解析,充分保證詞法解析的效能、準確定以及穩定性;
-
支援常見的 SQL(Insert/Delete/Update/Select);
-
支援多表 Join 並自動邏輯選定驅動表;
-
支援聚合條件 Order by 和 Group by;
-
過濾表中已存在的索引。
SQLAdvisor 原理介紹
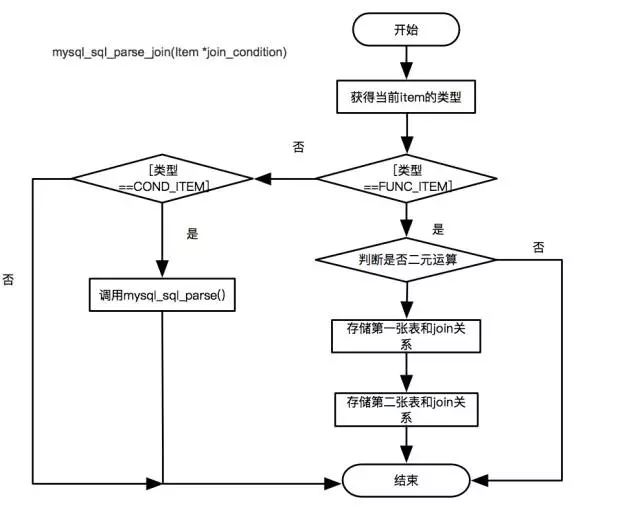
Join 處理
-
Join語法分為兩種:Join on 和 Join using,且 Join on 有時會存在 where 條件中。
-
分析 Join 條件首先會得到一個 nested_join 的 table list,通過判斷它 join_using_fields 欄位是否為空來區分 Join on 與 Join using。
-
生成的 table list 以二叉樹的形式進行儲存,以後序遍歷的方式對二叉樹進行遍歷。
-
生成內部解析樹時,right Join 會轉換成 left Join。
-
Join 條件會存在當層的葉子節點上,如果左右節點都是葉子節點,會存在右葉子節點。
-
每一個非葉子節點代表一次 Join 的結果。
上述實現時,涉及的函式為:mysql_sql_parse_join(TABLE_LIST join_table) mysql_sql_parse_join(Item join_condition) ,主要流程圖如下:
where 處理
-
主要是提取 SQL 語句的 where 條件。where 條件中一般由 AND 和 OR 連線符進行連線,因為 OR 比較難以處理,所以忽略,只處理 AND 連線符。
-
由於 where 條件中可以存在 Join 條件,因此需要進行區分。
-
依次獲取 where 條件,當條件中的操作符是 like,如果不是字首匹配則丟棄這個條件。
-
根據條件計算欄位的區分度按照高低進行倒序排,如果小於30則丟棄。同時使用最左原則將 where 條件進行有序排列。
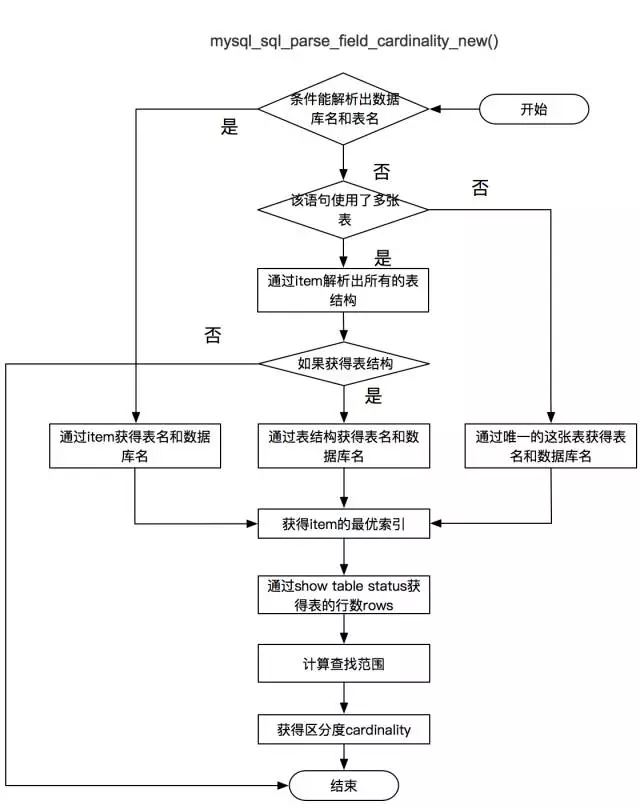
計算區分度
-
通過 “show table status like” 獲得表的總行數 table_count。
-
通過計算選擇表中已存在的區分度最高的索引 best_index,同時Primary key > Unique key > 一般索引。
-
通過計算獲取資料取樣的起始值offset與取樣範圍rand_rows:
-
offset = (table_count / 2) > 10W ? 10W : (table_count / 2)
-
rand_rows =(table_count / 2) > 1W ? 1W : (table_count / 2)
-
使用select count(1) from (select field from table force index(best_index) order by cl.. desc limit rand_rows) where field_print 得到滿足條件的rows。
-
cardinality = rows == 0 ? rand_rows : rand_rows / rows;
-
計算完成選擇度後,會根據選擇度大小,將該條件新增到該表中的備選索引中。
主要涉及的函式為:mysql_sql_parse_field_cardinality_new() 計算選擇度。
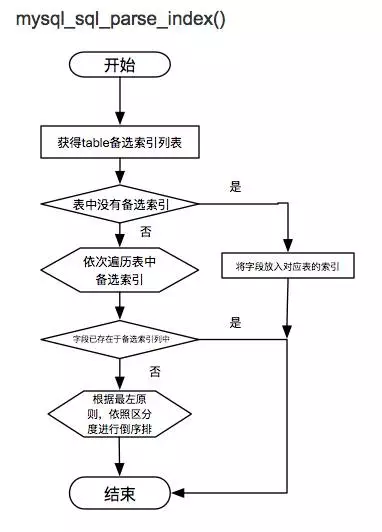
新增備選索引
-
mysql_sql_parse_index()將條件按選擇度新增到備選索引連結串列中。
-
上述兩函式的流程圖如下所示:
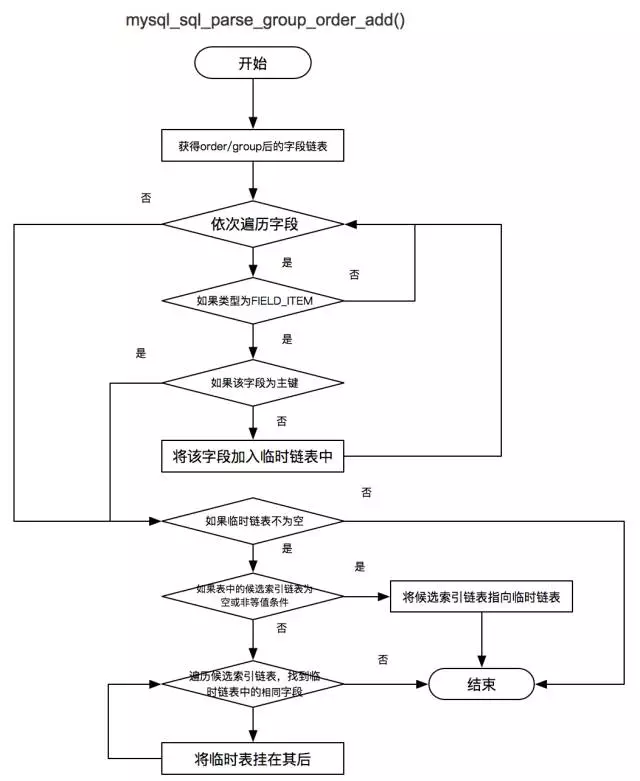
Group 與 Order 處理
-
Group 欄位與 Order 欄位能否用上索引,需要滿足如下條件:
-
涉及到的欄位必須來自於同一張表,並且這張表必須是確定下來的驅動表。
-
Group by 優於 Order by, 兩者只能同時存在一個。
-
Order by 欄位的排序方向必須完全一致,否則丟棄整個 Order by 欄位列。
-
當 Order by 條件中包含主鍵時,如果主鍵欄位為 Order by。 欄位列末尾,忽略該主鍵,否則丟棄整個 Order by 欄位列。
-
整個索引列排序優先順序:等值>(group by | order by )> 非等值。
-
該過程中設計的函式主要有:
-
mysql_sql_parse_group() 判斷 Group 後的欄位是否均來自於同一張表。
-
mysql_sql_parse_order() 判斷 Order 後的條件是否可以使用。
-
mysql_sql_parse_group_order_add() 將欄位依次按照規則新增到備選索引連結串列中。
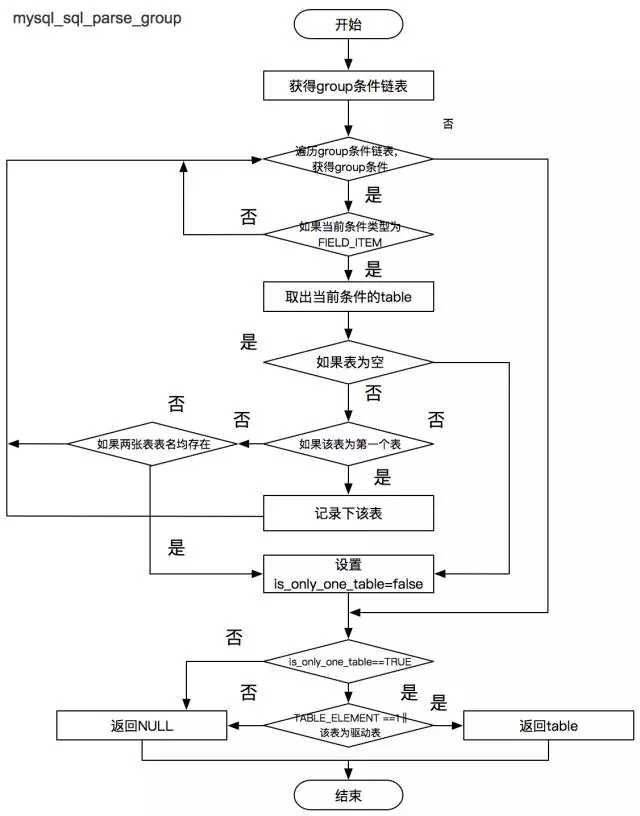
驅動表選擇
-
經過前期的 where 解析、Join 解析,已經將 SQL 中表關聯關係儲存起來,並且按照一定邏輯將候選驅動表確定下來。
-
在侯選驅動表中,按照每一張表的侯選索引欄位中第一個欄位進行計算表中結果集大小。
-
使用 explain select * from table where field 來計算表中結果集。
-
結果集小最小的被確為驅動表。
-
步驟中涉及的函式為:final_table_drived(),在該函式中,呼叫了函式 get_join_table_result_set() 來獲取每張驅動候選表的行數。
新增被驅動表備選索引
-
通過上述過程,已經選擇驅動表,也通過解析儲存了語句中的條件。
-
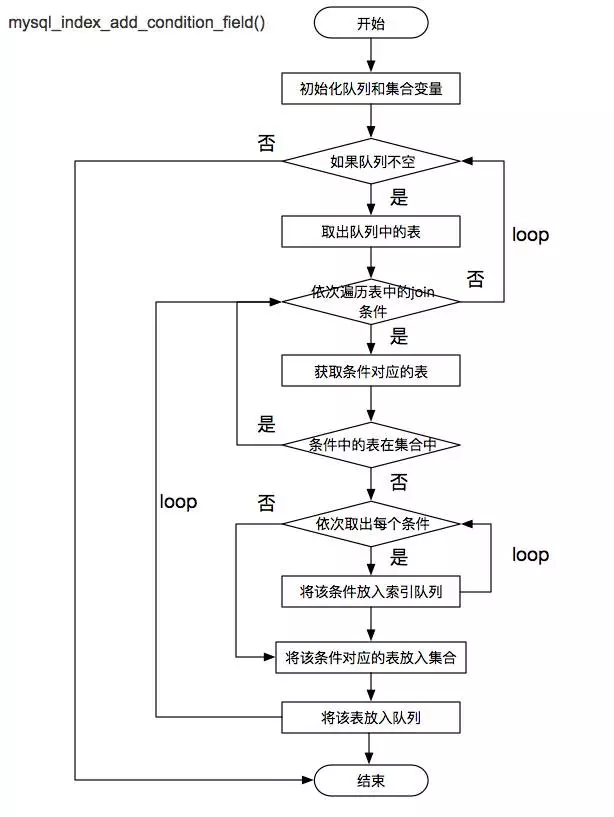
由於選定了驅動表,因此需要對被驅動表的索引,根據 Join 條件進行新增。
-
該過程涉及的函式主要是:mysql_index_add_condition_field(),流程如下:
輸出建議
-
通過上述步驟,已經將每張表的備選索引鍵全部儲存。此時,只要判斷每張表中的候選索引鍵是否在實際表中已存在。沒有索引,則給出建議增加對應的索引。
-
該步驟涉及的函式是:print_index() ,主要的流程圖為: