
base64 原理
Base64編碼之所以稱為Base64,是因為其使用64個字元來對任意資料進行編碼,同理有Base32、Base16編碼。標準Base64編碼使用的64個字元為:
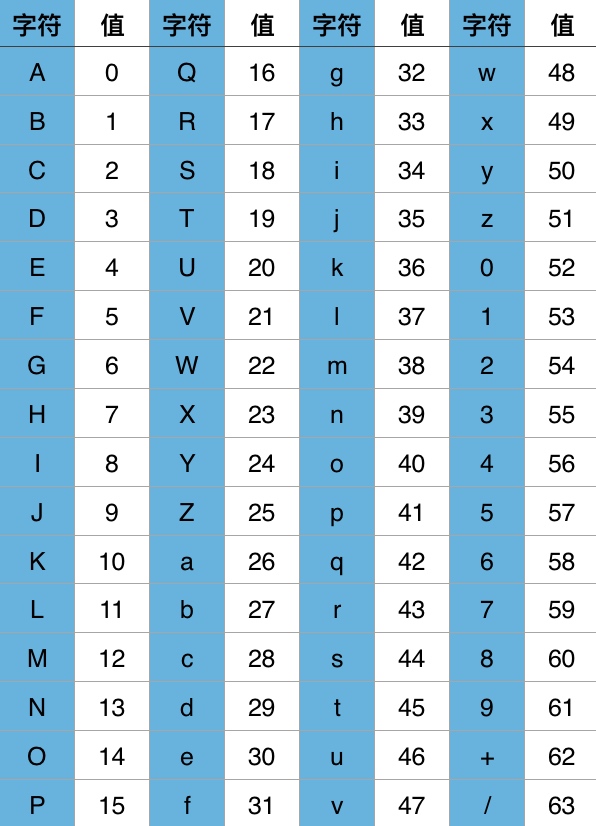
這64個字元是各種字元編碼(比如ASCII碼)所使用字元的子集,並可列印。唯一有點特殊的是最後兩個字元。
Base64本質上是一種將二進位制資料轉成文字資料的方案。對於非二進位制資料,是先將其轉換成二進位制形式,然後每連續6位元(2的6次方=64)計算其十進位制值,根據該值在上面的索引表中找到對應的字元,最終得到一個文字字串。假設我們對Hello!進行Base64編碼,按照ASCII表,其轉換過程如下圖所示:

可知Hello!的Base64編碼結果為SGVsbG8h,原始字串長度為6個字串,編碼後長度為8個字元,每3個原始字元經編碼成4個字元。
但要注意,Base64編碼是每3個原始字元編碼成4個字元,如果原始字串長度不能被3整除,怎麼辦?使用0來補充原始字串。
以Hello!!為例,其轉換過程為:
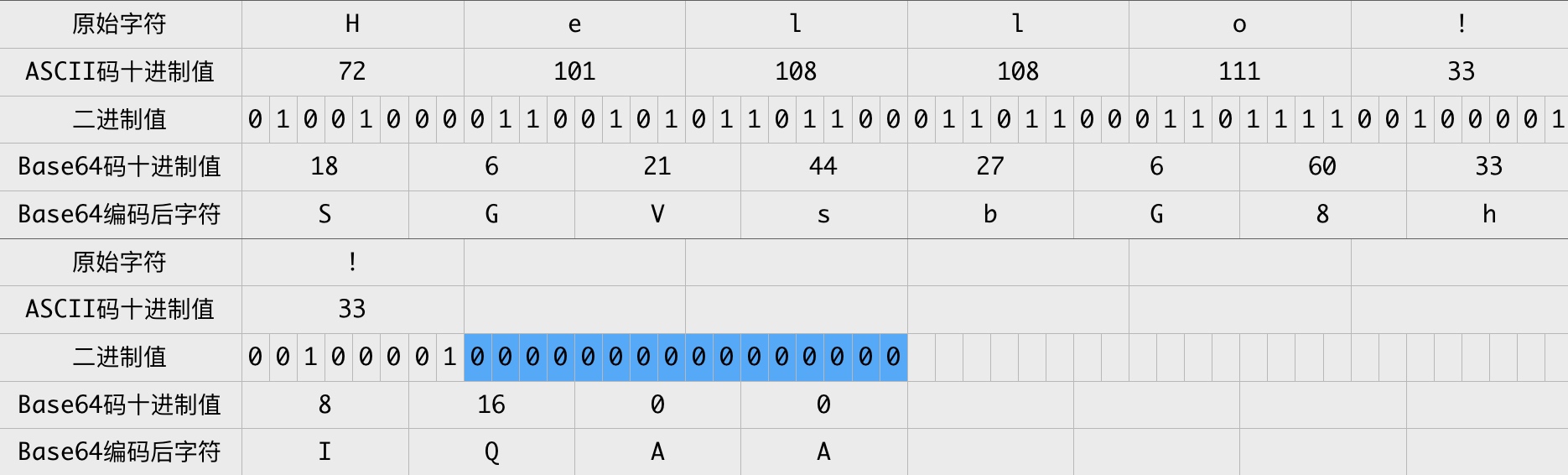
Hello!! Base64編碼的結果為 SGVsbG8hIQAA 。最後2個零值只是為了Base64編碼而補充的,在原始字元中並沒有對應的字元,那麼Base64編碼結果中的最後兩個字元 AA
標準Base64編碼通常用 = 字元來替換最後的 A,即編碼結果為 SGVsbG8hIQ==。因為 = 字元並不在Base64編碼索引表中,其意義在於結束符號,在Base64解碼時遇到 = 時即可知道一個Base64編碼字串結束。
如果Base64編碼字串不會相互拼接再傳輸,那麼最後的 = 也可以省略,解碼時如果發現Base64編碼字串長度不能被4整除,則先補充 = 字元,再解碼即可。
解碼是對編碼的逆向操作,但注意一點:對於最後的兩個 =
A 字元,再轉成對應的兩個6位元二進位制0值,接著轉成原始字元之前,需要將最後的兩個6位元二進位制0值丟棄,因為它們實際上不攜帶有效資訊。
Base64編碼之所以稱為Base64,是因為其使用64個字元來對任意資料進行編碼,同理有Base32、Base16編碼。標準Base64編碼使用的64個字元為:
這64個字元是各種字元編碼(比如ASCII碼)所使用字元的子集,並可列印。唯一有點特殊的是最後兩個字元。
Base64本質上是一種將二進位制資料轉成文字資料的方案。對於非二進位制資料,是先將其轉換成二進位制形式,然後每連續6位元(2的6次方=64)計算其十進位制值,根據該值在上面的索引表中找到對應的字元,最終得到一個文字字串。假設我們對Hello!進行Base64編碼,按照ASCII表,其轉換過程如下圖所示:
可知Hello!的Base64編碼結果為SGVsbG8h,原始字串長度為6個字串,編碼後長度為8個字元,每3個原始字元經編碼成4個字元。
但要注意,Base64編碼是每3個原始字元編碼成4個字元,如果原始字串長度不能被3整除,怎麼辦?使用0來補充原始字串。
以Hello!!為例,其轉換過程為:
Hello!! Base64編碼的結果為 SGVsbG8hIQAA 。最後2個零值只是為了Base64編碼而補充的,在原始字元中並沒有對應的字元,那麼Base64編碼結果中的最後兩個字元 AA 實際不帶有效資訊,所以需要特殊處理,以免解碼錯誤。
標準Base64編碼通常用 = 字元來替換最後的 A,即編碼結果為 SGVsbG8hIQ==。因為 = 字元並不在Base64編碼索引表中,其意義在於結束符號,在Base64解碼時遇到 = 時即可知道一個Base64編碼字串結束。
如果Base64編碼字串不會相互拼接再傳輸,那麼最後的 = 也可以省略,解碼時如果發現Base64編碼字串長度不能被4整除,則先補充 = 字元,再解碼即可。
解碼是對編碼的逆向操作,但注意一點:對於最後的兩個 = 字元,轉換成兩個A 字元,再轉成對應的兩個6位元二進位制0值,接著轉成原始字元之前,需要將最後的兩個6位元二進位制0值丟棄,因為它們實際上不攜帶有效資訊。