
《Batch Normalization: Accelerating Deep Network Training by Reducing Internal Covariate Shift》論文筆記
1. 論文思想
訓練深度學習網路是相當複雜的,每個層的輸入分佈會在訓練中隨著前一層的引數變化而改變。仔細地網路初始化以及較低的學習率下會降低網路的訓練速度,特別是具有飽和非線性的網路。在該論文中將該中現象稱之為“internal covariate shift”,在論文中為了解決該問題提出了BN的概念,它取得的成果也會很顯著:
(1)網路中添加了BN層之後可以使得網路使用更高的學習率,減少對網路初始化的關注
(2)網路中加入了BN層相當於增加了正則化,在一些場合下網路中可以取消掉Dropout層
(3)在加入BN層的網路結構中,達到相同的精度,加入BN層的網路能夠減少14倍的訓練步驟
(4)將論文中提出的理念運用到之前的網路後在ImageNet獲得了4.9% Top-5的驗證錯誤率,4.8的測試錯誤率,已經超過了人類的水平。
在前人的研究中對深度學習網路中的輸入進行白化處理,可以使得網路的效能得到提升,其實白化就是將資料進行歸一化處理,將資料轉換成為0均值和方差為1的資料分佈。另外,在深度學習訓練過程中SGD使用了batch_size進行訓練,避免使用單個樣本進行訓練,其中的道理也是batch_size進行訓練下降的方向更加準確,震盪更小。
而在網路中會出現“internal covariate shift”的問題就是因為網路在學習過程中網路中的輸入分佈是在不斷變化的,那麼在輸入的時候給它把分佈固定,那麼網路的訓練那麼不是會有好轉,正是基於這樣的思想,就祭出BN操作了。
2. 使用Min-Batch統計標準化
由於對每個輸入層做白化操作是花銷巨大且其實不可微的,也就沒辦法進行梯度傳遞。那麼在該文章裡面是對
維輸入
中的1維單獨進行標準化:
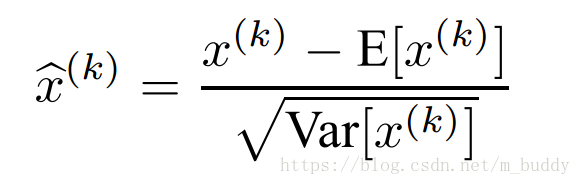
但是值得注意的是單一地對層輸入進行標準化會使得層的表達。例如,Sigmoid的輸入標準化會將輸入壓縮到Sigmoid函式的非線性函式中的線性部分中去。
但是這樣的操作會使得網路層的表達能力下降。因而在該篇論文中對標準化函式進行了修正。為每個
增加一對引數
與
,用作在原分佈上做縮放和偏移。
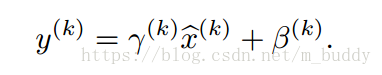
其中,對於引數取值為:
與
。因而對於輸入一個Batch-Size
對應的
,其對應的線性變化
描述為:
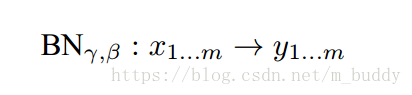
因而當前Batch-Size的標準化變換可以描述為如下形式:

上面的內容是BN操作的前向操作,但是網路要進行訓練就需要梯度資訊進行反向傳遞那麼這裡加入的BN層能夠進行反向運算麼?這裡其實就是判斷該變換是不是可微分的。論文中給出了其證明
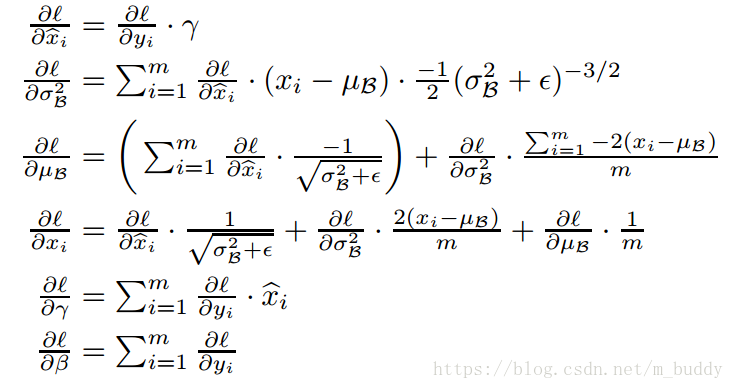
因為引入了BN操作,這就消除了“internal covariate shift”的問題,因而可以加快網路的訓練過程。
2.1 BN網路的訓練與推斷
在上面的內容中給出瞭如何給一個Batch-size使用BN操作進行網路分佈變換。那麼在網路訓練之後怎麼使用每個Batch-size訓練的結果來推斷網路最後應該取值的引數呢?接下來的內容便是網路的推斷(最後引數確立)。首先網路訓完成之後就需要使用總體統計來標準化網路,即是下面的公式
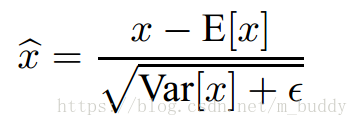
其中無偏方差估計
,
是Batch-size的大小,而
是這些取樣的方差。下面這幅圖便是推斷網路的大致流程。

這裡的輸入是引數為
的訓練網路與子集資料
,輸出是經過推斷在之後的
。這裡演算法的1~5便是當前Batch-size的標準化,之後步驟6開始訓練去優化訓練與BN中的引數。接下來步驟8~12是推斷總體統計,得到最後該BN層的引數。
2.2 BN可以使用更高的學習率
在傳統的深度網路中太高的學習率會導致梯度爆炸或是消失,以及陷入區域性最優值的問題。在網路中加入BN之後可以防止網路中引數微小的變化被放大。在網路中使用更大的學習率,可以被理解成為是層引數範圍的增大,這在反相傳播的過程中會導致模型梯度爆炸。那麼增大的引數可以使用
a$來表示,那麼訓練的時候層的標準化可以表示為
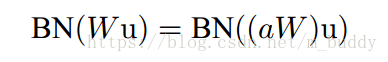
可以看到縮放參數的範圍並不會對BN的結果帶來影響,因而加入BN之後可以使得網路可以使用更高的學習率。
3. 實驗
下面這幅圖是在MNIST資料集上進行測試,結果為
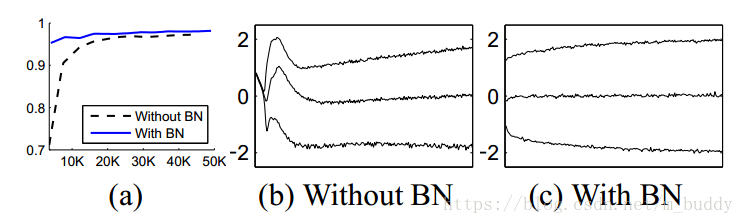
可以明顯看到網路在加入BN之後訓練的曲線變得更加平滑,收斂也更快。
3.1 加速BN網路
只是使用BN並不能使得該文章中的BN作用最大化,文章中給出瞭如下的建議:
(1)提高學習率:在批標準化模型中,我們已經能夠從高學習率中實現訓練加速,沒有不良的副作用。
(2)刪除Dropout層:我們發現從BN-Inception中刪除Dropout層可以使網路實現更高的驗證準確率。我們推測,批標準化提供了類似丟棄的正則化收益,因為對於訓練樣本觀察到的啟用受到了同一小批量資料中樣本隨機選擇的影響。
(3)更徹底地攪亂訓練樣本。我們啟用了分佈內部攪亂訓練資料,這樣可以防止同一個例子一起出現在小批量資料中。這導致驗證準確率提高了約1%,這與批標準化作為正則化項的觀點是一致的:它每次被看到時都會影響一個樣本,在我們的方法中內在的隨機化應該是最有益的。
(4)減少L2全中正則化。雖然在Inception中模型引數的L2損失會控制過擬合,但在修改的BN-Inception中,損失的權重減少了5倍。我們發現這提高了在提供的驗證資料上的準確性。
(5)加速學習率衰減。在訓練Inception時,學習率呈指數衰減。因為我們的網路訓練速度比Inception更快,所以我們將學習速度降低加快6倍。
(5)刪除區域性響應歸一化(Local Response Normalization, LRN)。雖然Inception和其它網路(Srivastava等人,2014)從中受益,但是我們發現使用批標準化它是不必要的。
(5)減少光照扭曲。因為批標準化網路訓練更快,並且觀察每個訓練樣本更少的次數,所以通過更少地扭曲它們,我們讓訓練器關注更多的“真實”影象。