
大資料HBase系列之初識HBase
1. HBase簡介
1.1 為什麼使用HBase
傳統的RDBMS關係型資料庫(MySQL/Oracle)儲存一定量資料時進行資料檢索沒有問題,可當資料量上升到非常巨大規模的資料(TB/PB)級別時,傳統的RDBMS已無法支撐,這時候就需要一種新型的資料庫系統更好更快的處理這些資料。我們可以選擇HBase。
1.2 HBase的地位
HBase佔有舉足輕重的作用,它居於HDFS之上,與MapReduce可以整合,與Hive也可以整合,HBase表中的資料與Hive表的資料可以關聯,Spark也可以讀HBase的資料。
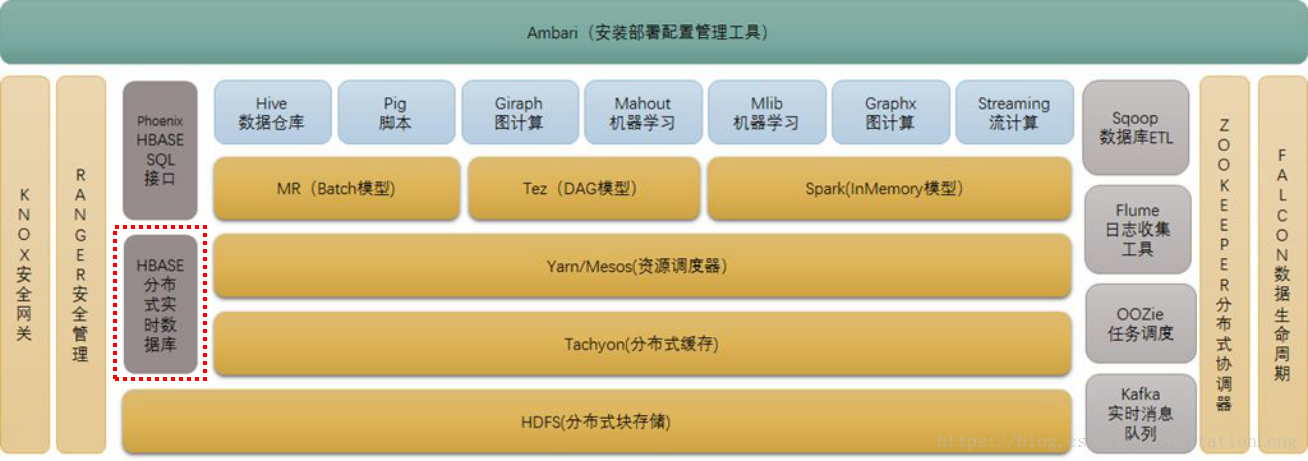
2. HBase是什麼
-
HBase技術來源於 Fay Chang 所撰寫的Google論文:Bigtable(一個結構化資料的分散式儲存系統)。
-
HBase是Apache的Hadoop專案的子專案。HBase不同於一般的關係資料庫,它是一個適合於 非結構化資料儲存的資料庫。另一個不同的是HBase基於列的而不是基於行的模式。
-
HBase(Hadoop Database),是一個高可靠性、高效能、面向列、可伸縮的分散式儲存系統,利用HBase技術可在廉價PC Server上搭建起大規模結構化儲存叢集。
-
HBase實際上是一個Hadoop的資料庫系統,它的主要作用和傳統資料庫系統一樣儲存資料和檢索資料。不同的是,HBase可以儲存海量資料及海量資料的檢索。
2.1 HBase與Hadoop的對比
| Hadoop/HDFS |
HBase |
|---|---|
| 為分散式儲存提供檔案系統 |
提供表狀的面向列的資料儲存 |
| 針對儲存大尺寸的檔案進行優化,不需要對這些檔案進行隨機讀寫 |
針對表狀資料的隨機讀寫進行優化 |
| 直接使用檔案 |
使用key-value對資料 |
| 資料模型不靈活 |
提供靈活的資料模型 |
| 使用檔案系統和處理框架 |
使用表狀儲存,依賴內建的Hadoop MapReduce支援 |
| 為一次寫多次讀進行優化 |
為多次讀寫進行優化 |
2.2 HBase與關係型資料庫的功能對比
| 關係型資料庫RDBMS |
HBase |
|---|---|
| 支援向上擴充套件。(若需要更多的磁碟、記憶體和處理能力,需要升級伺服器) |
支援向外擴充套件。(若需要更多的磁碟、記憶體和處理能力,不需要升級伺服器,需要為叢集新增新的伺服器) |
| 使用SQL查詢從表中讀取資料 |
使用API和MapReduce來訪問HBase表的資料 |
| 面向行(每行資料都是一個連續的頁的單元) |
面向列(每列資料都是一個連續的頁的單元) |
| 資料總量依賴於伺服器配置 |
資料總量不依賴於伺服器配置,而是總的機器數量 |
| 模式更嚴格 |
模式靈活,不太嚴格 |
| 具有ACID支援 |
沒有內建的對HBase的支援 |
| 適合結構化資料 |
適合結構化和非結構化資料 |
| 傳統關係型資料庫一般是中心化的 |
通常是分散式的 |
| 一般能保證事務完整性 |
HBase不支援事務 |
| 支援JOIN |
不支援JOIN |
| 支援參照完整性 |
沒有內建的參照完整性支援 |
- 當資料量比較小,RDBMS可以支撐的時候,可以用RDBMS來實現,若需要線上事務處理時,RDBMS是合適的。
- 但當有海量資料需要處理時,可以選擇HBase,並且HBase由於是列儲存型資料庫,在聚合計算和資料分析時非常快。
| 列儲存資料庫的優點 |
列儲存資料庫的缺點 |
|---|---|
| 具有高效和資料壓縮的內部支援 |
JOIN和多表合併資料的查詢效能不好 |
| 支援快速資料檢索 |
更新過程中有大量的寫入和刪除操作,需要頻繁合併和分裂,降低了儲存效率 |
| 管理和配置簡單。支援橫向擴充套件 |
對關係模型支援不好,分割槽和索引模式設計比較困難 |
| 聚合查詢的效能非常高 |
|
| 可高效地進行分割槽 |
3. HBase架構設計及表的儲存設計
- HBase是水平擴充套件的、分散式的、開源有序對映資料庫。它執行在Hadoop檔案系統HDFS上。它不要求有預定義的模式,可以被看做彈性擴充套件的多維表格,通過動態新增列,在資料插入或查詢之前修改列結構,以支援任意的資料結構。
- HBase是一個建立在HDFS上的列儲存資料庫,具有至此線性擴充套件(橫向擴充套件)、自動故障轉移、自動分割槽及模式自由等特性。
3.1 HBase體系架構圖
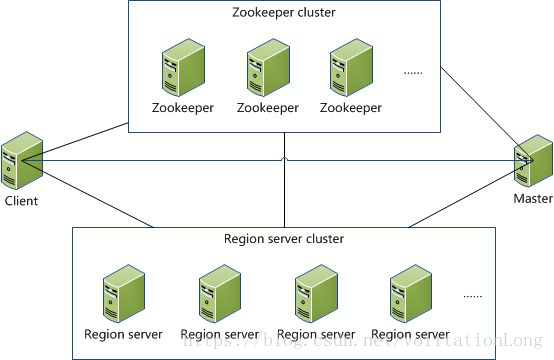
3.2 HBase架構設計及表的儲存設計
- Master
為HBase的主節點,用來協調客戶端應用程式和RegionServer的關係,同時用來監控和記錄元資料的變化和管理。
- RegionServer
是從節點,用region的形式處理實際的表。region是HBase表的基礎單元元件,它儲存了分散式表。所以HBase表和HBase叢集利用Master和RegionServer來協同工作。
- ZooKeeper
是一個高效能、集中化、分散式應用程式協調服務,它為HBase提供了分散式同步和組服務。在HBase中,它用來選舉叢集主節點Master,以便跟蹤可用的線上伺服器,同時維護叢集的元資料。一般安裝多個,用於提供Master的高可用性。
通常,Master和Hadoop的NameNode程序執行在同一臺主機上,與DataNode通訊以讀寫HDFS的資料。RegionServer跟Hadoop的DataNode執行在同一臺主機上。