
LInux 網站基於地域維度的UV分析 以及eclipse將包打包成jar包
PV: Page View 網頁瀏覽量
UV:Unique View 使用者唯一訪問量
Ip:網路IP地址訪問網站的訪問量
VV:Visit View 遊客的訪問數量
回顧:Hadoop 是一個由Apache基金會所開發的分散式系統基礎架構,其功能是為了解決大資料的儲存和大資料的計算。
hdfs:是Hadoop用來解決大資料儲存的方式,又名分散式檔案系統
MapReduce:是一種程式設計模型,用於大規模資料集(大於1TB)的並行運算。學習Hadoop主要學習的是其思想。
hdfs的特點:分散式:
特點:
主從結構:namenode:主節點 作用:儲存元資料,接受處理使用者的請求,管理所有從節點
分塊 、有副本:保證資料不丟失
Map Reduce V2 分散式計算模型 ——》input——》mapper——》shuffle——》reduce——》output
yarn:分散式
resource manager;作用:資源管理,任務排程,管理從節點
Map Reduce 執行過程:——》input:預設從hdfs中讀取資料:Text Input Format / File Input Format ——》路徑:Path path = new
Path(args[0]);——》將每一行轉換為一個keyvalue——》輸出
mapper——》輸入:input的輸出 Longwritable /Text ; map():方法,一行呼叫一次map方法。map思路:1)設計輸出,構造輸出的keyvalue
2) 對每一行內容進行分割——》輸出
shuffle:功能:分割槽,分組,排序
reduce:每一條keyvalue呼叫一次reduce方法 reduce,將相同key的List<value>,進行相加求和
output:輸出,預設將reduce的輸出寫入hdfs中。
MapReduce開發模板
-》Driver:
-》不繼承不實現
-》繼承及實現
extends Configured implements Tool
-》不繼承只實現
implements Tool
-》Mapper
-》Reducer
自定義資料型別
-》要求keyvalue中包含多列
-》在map中
輸出的key:自定義資料型別
輸出的value:nullwritable
-》實現介面
-》Writable
-》write
-》readFields
-》WritableComparable
-》capareTo
-》其他方法
-》get and set
-》建構函式
-》toString
-》hashcode and equals
UV:unique view 唯一訪問數,一個使用者記一次 統計每個城市的UV數
import java.io.IOException;
import java.util.HashSet;
import org.apache.commons.lang.StringUtils;
import org.apache.hadoop.conf.Configuration;
import org.apache.hadoop.conf.Configured;
import org.apache.hadoop.fs.Path;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.LongWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Job;
import org.apache.hadoop.mapreduce.Mapper;
import org.apache.hadoop.mapreduce.Reducer;
import org.apache.hadoop.mapreduce.lib.input.FileInputFormat;
import org.apache.hadoop.mapreduce.lib.output.FileOutputFormat;
import org.apache.hadoop.util.Tool;
import org.apache.hadoop.util.ToolRunner;
public class UrMrtest extends Configured implements Tool {
public static class WebLogUVMapper extends Mapper<LongWritable, Text, Text, Text>{
private Text outputKey = new Text();
private Text outputValue = new Text();
@Override
protected void map(LongWritable key, Text value,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
//分割每一行的內容
String line = value.toString();
String[] items = line.split("\t");
if (36<=items.length) {
if (StringUtils.isBlank(items[5])) {
return;
}
this.outputKey.set(items[23]);
this.outputValue.set(items[5]);
context.write(outputKey, outputValue);
}else{
return;
}
}
}
public static class WebLogUVReduce extends Reducer<Text, Text, Text, IntWritable>{
@Override
protected void reduce(Text key, Iterable<Text> values,Context context)
throws IOException, InterruptedException {
// TODO Auto-generated method stub
HashSet<String> a = new HashSet<>();
for(Text value:values){
a.add(value.toString());
}
context.write(key, new IntWritable(a.size()));
}
}
@Override
public int run(String[] arg0) throws Exception {
// TODO Auto-generated method stub
//job
Job job = Job.getInstance(this.getConf(),"uvtest");
job.setJarByClass(UrMrtest.class);
//input
FileInputFormat.setInputPaths(job, new Path(arg0[0]));
//map
job.setMapperClass(WebLogUVMapper.class);
job.setMapOutputKeyClass(Text.class);
job.setMapOutputValueClass(Text.class);
//reducer
job.setReducerClass(WebLogUVReduce.class);
job.setOutputKeyClass(Text.class);
job.setOutputValueClass(IntWritable.class);
job.setNumReduceTasks(2);
//output
FileOutputFormat.setOutputPath(job, new Path(arg0[1]));
return job.waitForCompletion(true)?0:1;
}
public static void main(String[] args){
Configuration conf = new Configuration();
try {
int status = ToolRunner.run(conf, new UrMrtest(),args);
System.exit(status);
} catch (Exception e) {
// TODO Auto-generated catch block
e.printStackTrace();
}
}
}將程式碼打包成jar
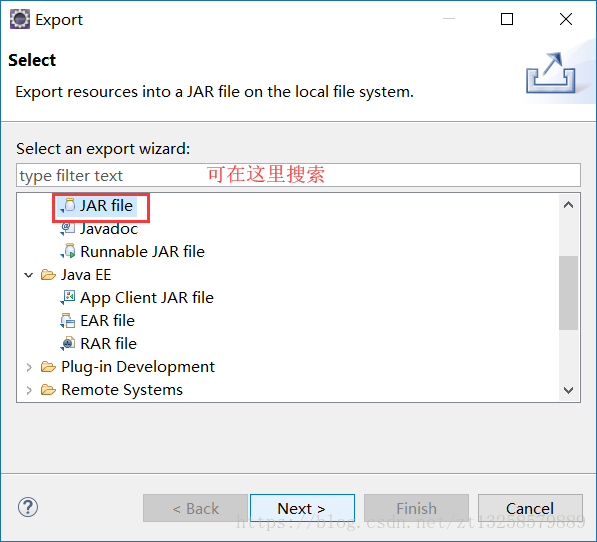
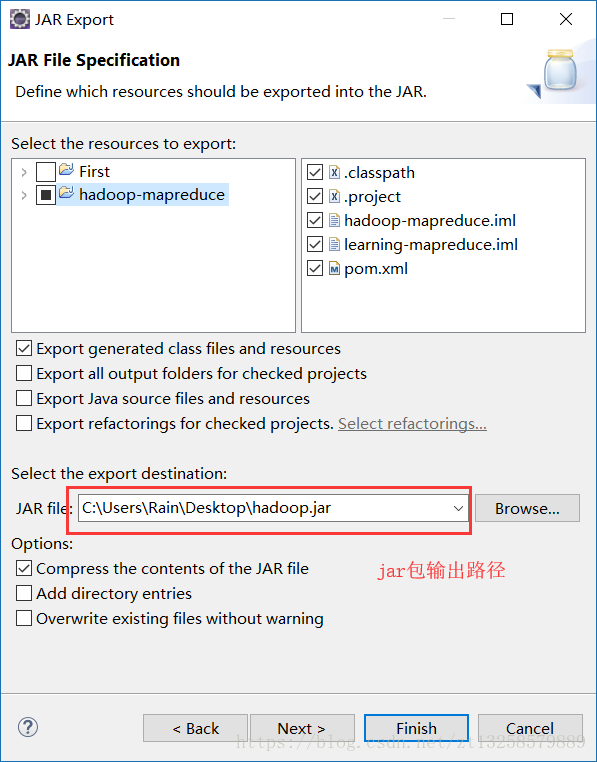
next——》next
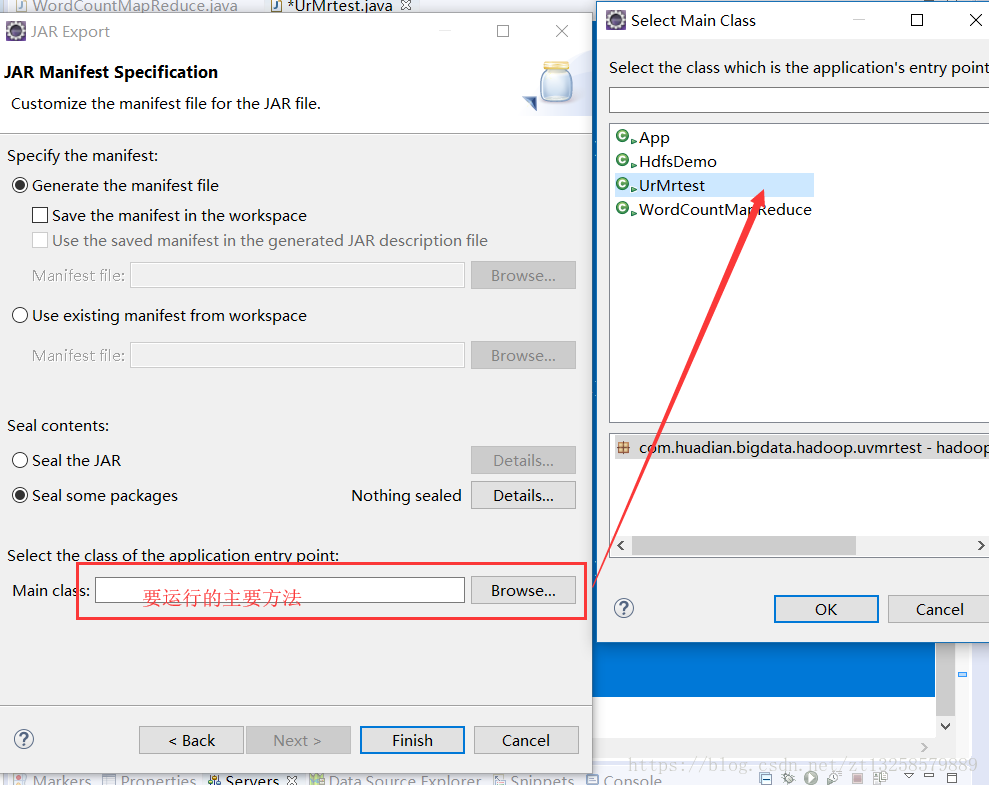
finish 之後
執行OK就好了。
將jar包匯入到Linux中,準備好資料

執行檢測。