
如何判斷CPU是大端還是小端模式
一、概念及詳解
在各種體系的計算機中通常採用的位元組儲存機制主要有兩種: Big-Endian和Little-Endian,即大端模式和小端模式。
Big-Endian和Little-Endian的定義如下:
1) Little-Endian:就是低位位元組排放在記憶體的低地址端,高位位元組排放在記憶體的高地址端。
2) Big-Endian:就是高位位元組排放在記憶體的低地址端,低位位元組排放在記憶體的高地址端。

舉一個例子,比如16進位制數字0x12345678在記憶體中的表示形式為:
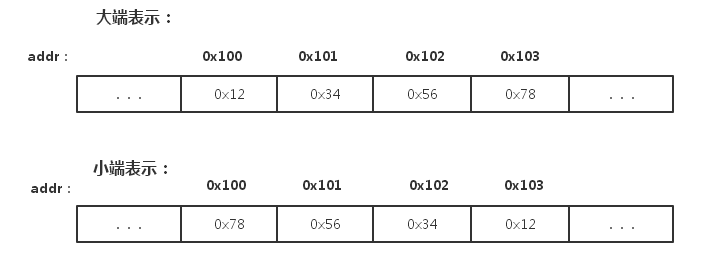
大端小端沒有誰優誰劣,各自優勢便是對方劣勢:
小端模式 :強制轉換資料不需要調整位元組內容,1、2、4位元組的儲存方式一樣。
大端模式 :符號位的判定固定為第一個位元組,容易判斷正負。
為什麼會有大小端模式之分呢?
這是因為在計算機系統中,我們是以位元組為單位的,每個地址單元都對應著一個位元組,一個位元組為8bit。但是在C語言中除了8bit的char之外,還有16bit的short型,32bit的long型(要看具體的編譯器),另外,對於位數大於8位的處理器,例如16位或者32位的處理器,由於暫存器寬度大於一個位元組,那麼必然存在著一個如何將多個位元組安排的問題。因此就導致了大端儲存模式和小端儲存模式。
例如一個16bit的short型x,在記憶體中的地址為0x0010,x的值為0x1122,那麼0x11為高位元組,0x22為低位元組。對於大端模式,就將0x11放在低地址中,即0x0010中,0x22放在高地址中,即0x0011
如何判斷機器的位元組序
int i=1;
char *p=(char *)&i;
if(*p == 1)
printf("小端模式");
else // (*p == 0)
printf("大端模式");或者使用聯合體union:
//return 1 : little-endian
// 0 : big-endian
int checkCPUendian()
{
union 因為聯合體union的存放順序是所有成員都從低地址開始存放,利用該特性就可以輕鬆地獲得了CPU對記憶體採用Little-endian還是Big-endian模式讀寫。
常見的位元組序
一般作業系統都是小端,而通訊協議是大端的。
常見CPU的位元組序
| 大小端 | CPU |
|---|---|
| Big Endian | PowerPC、IBM、Sun |
| Little Endian | x86、DEC |
ARM既可以工作在大端模式,也可以工作在小端模式。
常見檔案的位元組序
| 檔案格式 | 大小端 |
|---|---|
| Adobe PS | Big Endian |
| BMP | Little Endian |
| DXF(AutoCAD) | Variable |
| GIF | Little Endian |
| JPEG | Big Endian |
| MacPaint | Big Endian |
| RTF | Little Endian |
另外,Java和所有的網路通訊協議都是使用Big-Endian的編碼。
大端小端的轉換方法

#define BigtoLittle16(A) ((((uint16)(A) & 0xff00) >> 8) | \
(((uint16)(A) & 0x00ff) << 8))
#define BigtoLittle32(A) ((((uint32)(A) & 0xff000000) >> 24) | \
(((uint32)(A) & 0x00ff0000) >> 8) | \
(((uint32)(A) & 0x0000ff00) << 8) | \
(((uint32)(A) & 0x000000ff) << 24))